TensorFlow implementation of:
Neural Combinatorial Optimization with Reinforcement Learning, Bello I., Pham H., Le Q. V., Norouzi M., Bengio S.
for the TSP with Time Windows (TSP-TW).
and Learning Heuristics for the TSP by Policy Gradient, Deudon M., Cournut P., Lacoste A., Adulyasak Y. and Rousseau L.M.
for the Traveling Salesman Problem (TSP) (final release here)

The Neural Network consists in a RNN or self attentive encoder-decoder with an attention module connecting the decoder to the encoder (via a "pointer"). The model is trained by Policy Gradient (Reinforce, 1992).
- Python 2.7 or 3.5
- TensorFlow 1.0.1
- tqdm
- Google OR tools - optional reference solver (main.py, dataset.py)
(under progress)
- To train a (2D TSP20) model from scratch (data is generated on the fly):
> python main.py --max_length=20 --inference_mode=False --restore_model=False --save_to=20/model --log_dir=summary/20/repo
NB: Just make sure ./save/20/model exists (create folder otherwise)
- To visualize training on tensorboard:
> tensorboard --logdir=summary/20/repo
- To test a trained model:
> python main.py --max_length=20 --inference_mode=True --restore_model=True --restore_from=20/model
- To pretrain a (2D TSPTW20) model with infinite travel speed from scratch:
> python main.py --inference_mode=False --pretrain=True --restore_model=False --speed=1000. --beta=3 --save_to=speed1000/n20w100 --log_dir=summary/speed1000/n20w100
- To fine tune a (2D TSPTW20) model with finite travel speed:
> python main.py --inference_mode=False --pretrain=False --kNN=5 --restore_model=True --restore_from=speed1000/n20w100 --speed=10.0 --beta=3 --save_to=speed10/s10_k5_n20w100 --log_dir=summary/speed10/s10_k5_n20w100
NB: Just make sure save_to folders exist
- To visualize training on tensorboard:
> tensorboard --logdir=summary/speed1000/n20w100
> tensorboard --logdir=summary/speed10/s10_k5_n20w100
- To test a trained model with finite travel speed on Dumas instances (in the benchmark folder):
> python main.py --inference_mode=True --restore_model=True --restore_from=speed10/s10_k5_n20w100 --speed=10.0
Sampling 128 permutations with the Self-Attentive Encoder + Pointer Decoder:
- Comparison to Google OR tools on 1000 TSP20 instances: (predicted tour length) = 0.9983 * (target tour length)

Sampling 256 permutations with the RNN Encoder + Pointer Decoder, followed by a 2-opt post processing on best tour:
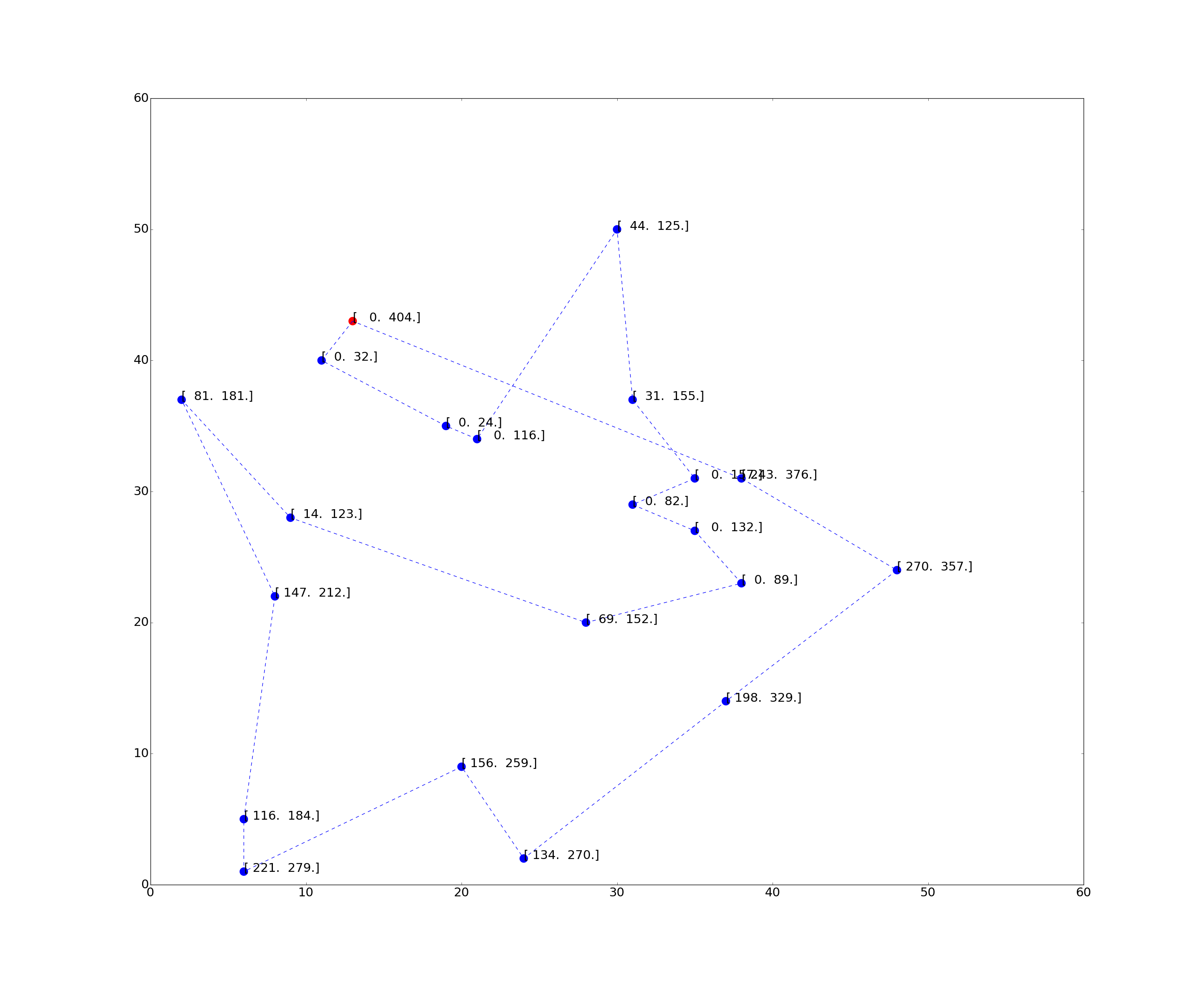
- Dumas instance n20w100.001
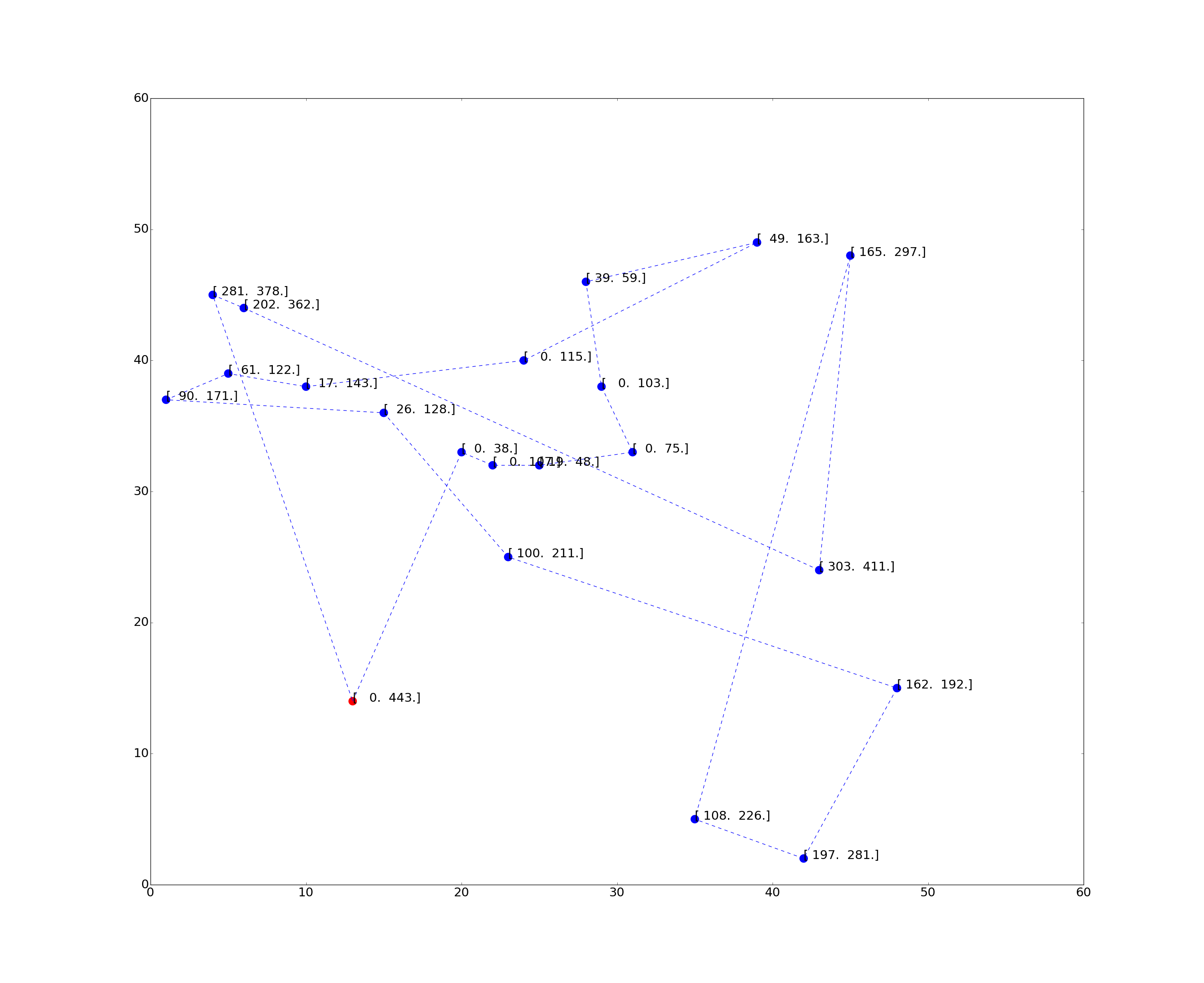
- Dumas instance n20w100.003


Michel Deudon / @mdeudon
Pierre Cournut / @pcournut
Bello, I., Pham, H., Le, Q. V., Norouzi, M., & Bengio, S. (2016). Neural combinatorial optimization with reinforcement learning. arXiv preprint arXiv:1611.09940.