数学公式识别,增强:中文公式、手写公式





Seq2Seq + Attention + Beam Search。结构如下:
- python3.5 + tensorflow1.12.2
[可选]latex (latex 转 pdf)[可选]ghostscript (图片处理)[可选]magick (pdf 转 png)
[可选]新开一个虚拟环境virtualenv env35 --python=python3.5 source env35/bin/activate- 安装依赖
pip install -r requirements.txt // cpu 版 pip install -r requirements-gpu.txt // gpu 版
- 下载数据集
git submodule init git submodule update
如果 git 速度太慢,您也可以手动下载数据集,放到 data 目录下。数据集仓库在 https://github.com/LinXueyuanStdio/Data-for-LaTeX_OCR 数据仓库同时托管到 huggingface (linxy/LaTeX_OCR),欢迎使用!
Linux
一键安装
make install-linux或
- 安装本项目依赖
virtualenv env35 --python=python3.5
source env35/bin/activate
pip install -r requirements.txt- 安装 latex (latex 转 pdf)
sudo apt-get install texlive-latex-base
sudo apt-get install texlive-latex-extra- 安装 ghostscript
sudo apt-get update
sudo apt-get install ghostscript
sudo apt-get install libgs-dev- 安装magick (pdf 转 png)
wget http://www.imagemagick.org/download/ImageMagick.tar.gz
tar -xvf ImageMagick.tar.gz
cd ImageMagick-7.*; \
./configure --with-gslib=yes; \
make; \
sudo make install; \
sudo ldconfig /usr/local/lib
rm ImageMagick.tar.gz
rm -r ImageMagick-7.*Mac
一键安装
make install-mac或
- 安装本项目依赖
sudo pip install -r requirements.txt- LaTeX
我们需要 pdflatex,可以傻瓜式一键安装:http://www.tug.org/mactex/mactex-download.html
- 安装magick (pdf 转 png)
wget http://www.imagemagick.org/download/ImageMagick.tar.gz
tar -xvf ImageMagick.tar.gz
cd ImageMagick-7.*; \
./configure --with-gslib=yes; \
make;\
sudo make install; \
rm ImageMagick.tar.gz
rm -r ImageMagick-7.*生成小数据集、训练、评价
提供了样本量为 100 的小数据集,方便测试。只需 2 分钟就可以根据 ./data/small.formulas/ 下的公式生成用于训练的图片。
注意:样本量很小,是无法有效训练模型的。这个小数据集仅用于确认代码有没有 bug。如果用于预测,那结果极差,因为数据不够。
一步训练
make small
或
-
生成数据集
用 LaTeX 公式生成图片,同时保存公式-图片映射文件,生成字典 只用运行一次
# 默认 python build.py # 或者 python build.py --data=configs/data_small.json --vocab=configs/vocab_small.json
-
训练
# 默认 python train.py # 或者 python train.py --data=configs/data_small.json --vocab=configs/vocab_small.json --training=configs/training_small.json --model=configs/model.json --output=results/small/ -
评价预测的公式
# 默认 python evaluate_txt.py # 或者 python evaluate_txt.py --results=results/small/ -
评价数学公式图片
# 默认 python evaluate_img.py # 或者 python evaluate_img.py --results=results/small/
生成完整数据集、训练、评价
根据公式生成 70,000+ 数学公式图片需要 2-3 个小时
一步训练
make full
或
-
生成数据集
用 LaTeX 公式生成图片,同时保存公式-图片映射文件,生成字典 只用运行一次
python build.py --data=configs/data.json --vocab=configs/vocab.json -
训练
python train.py --data=configs/data.json --vocab=configs/vocab.json --training=configs/training.json --model=configs/model.json --output=results/full/ -
评价预测的公式
python evaluate_txt.py --results=results/full/ -
评价数学公式图片
python evaluate_img.py --results=results/full/
可视化训练过程
用 tensorboard 可视化训练过程
小数据集
cd results/small
tensorboard --logdir ./
完整数据集
cd results/full
tensorboard --logdir ./
可视化预测过程
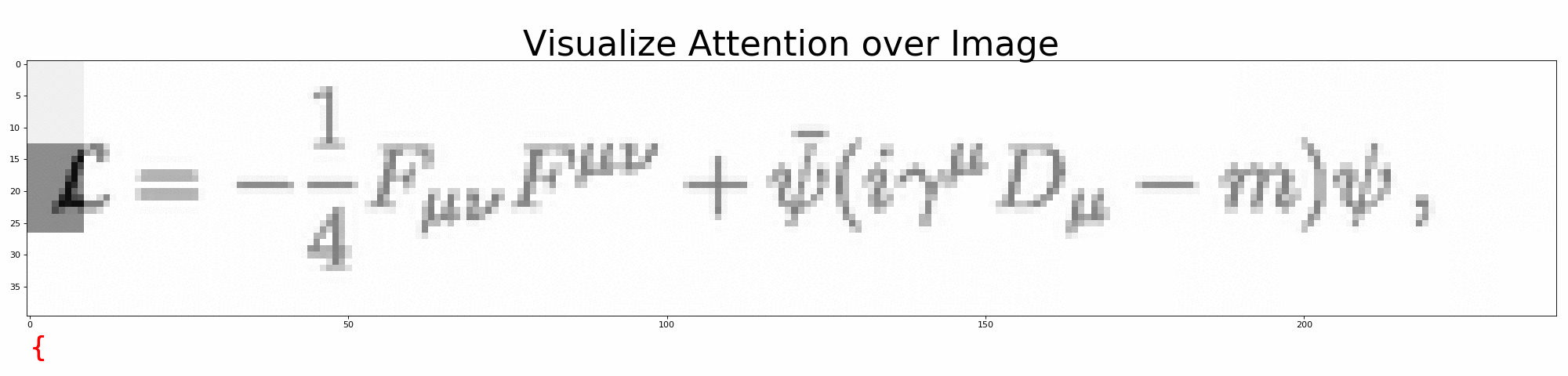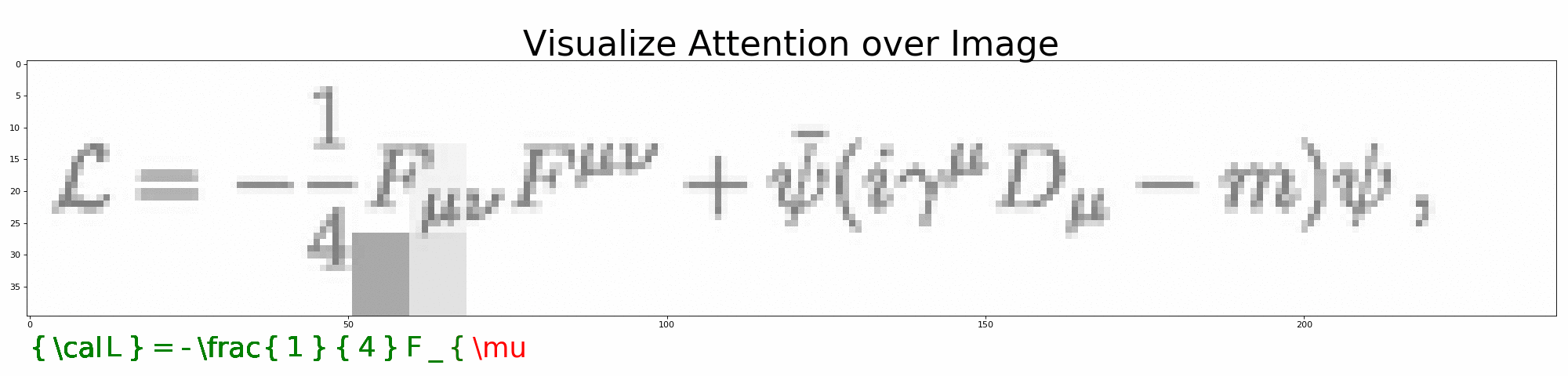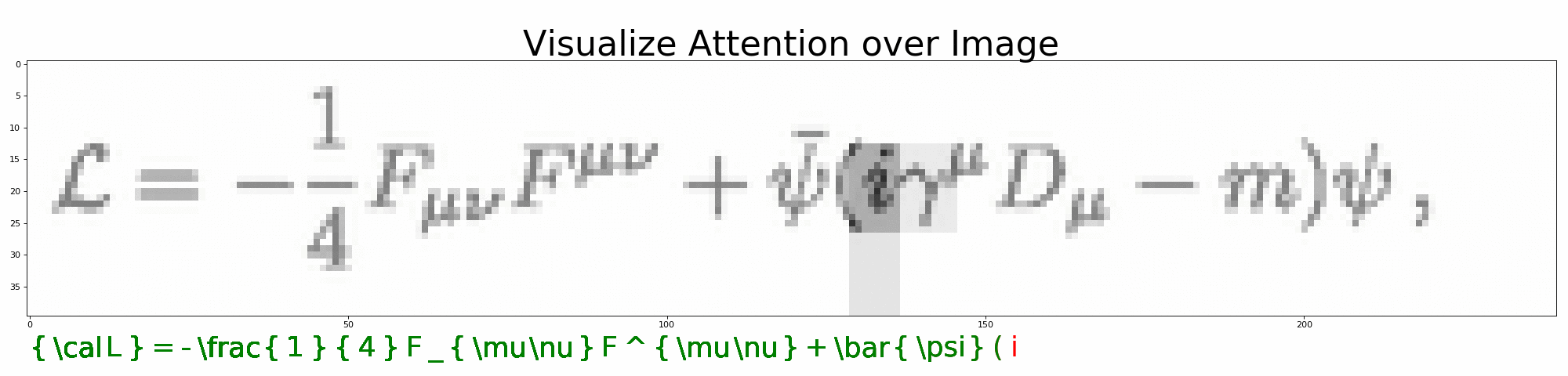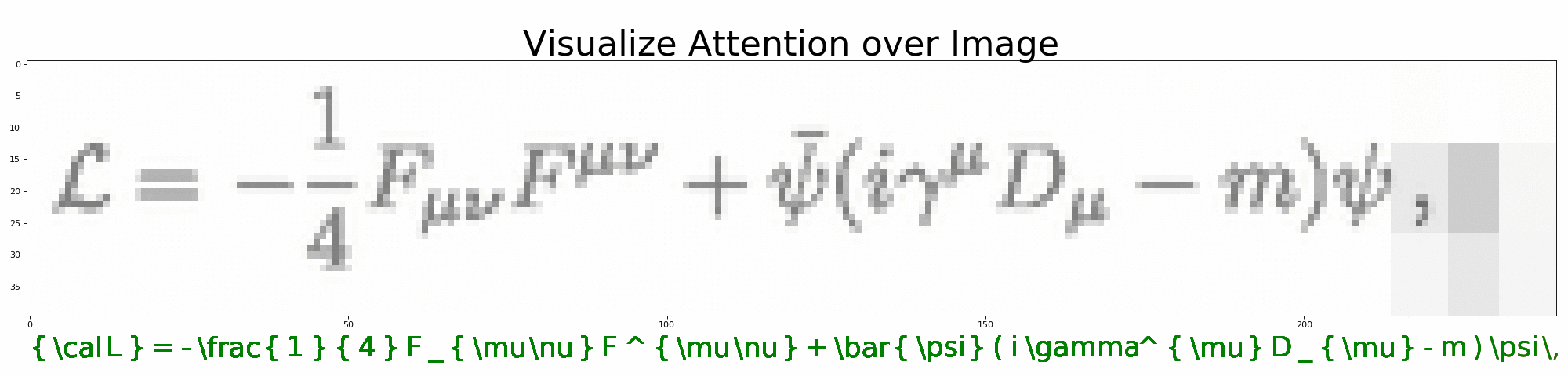
打开 visualize_attention.ipynb,一步步观察模型是如何预测 LaTeX 公式的。
或者运行
# 默认
python visualize_attention.py
# 或者
python visualize_attention.py --image=data/images_test/6.png --vocab=configs/vocab.json --model=configs/model.json --output=results/full/可在 --output 下生成预测过程的注意力图。
部署为 Django 应用
- 安装部署需要的环境
pip install django
- 开启服务
python manage.py runserver 0.0.0.0:8010
- 开启图片服务
cd data/images_train python -m SimpleHTTPServer 8020 - 使用方法
在输入框里依次输入
0.png,1.png等等,即可看到结果
| 指标 | 训练分数 | 测试分数 |
|---|---|---|
| perplexity | 1.12 | 1.13 |
| EditDistance | 94.16 | 93.36 |
| BLEU-4 | 91.03 | 90.47 |
| ExactMatchScore | 49.30 | 46.22 |
perplexity 是越接近1越好,其余3个指标是越大越好。
其中 EditDistance 和 BLEU-4 已达到业内先进水平
将 perplexity 训练到 1.03 左右,ExactMatchScore 还可以再升,应该可以到 70 以上。
机器不太好,训练太费时间了。
十分感谢 Harvard 和 Guillaume Genthial 、Kelvin Xu 等人提供巨人的肩膀。
论文:
LaTeX_OCR 的 PyTorch 版: https://github.com/qs956/Latex_OCR_Pytorch by @qs956
BibTeX
@misc{lin2024latex_ocr_pro,
title={LaTeX_OCR_PRO},
author={Xueyuan Lin},
year={2024},
publisher={GitHub},
howpublished={\url{https://github.com/LinXueyuanStdio/LaTeX_OCR_PRO}},
}