HDRTVNet [Paper Link]
Xiangyu Chen*, Zhengwen Zhang*, Jimmy S. Ren, Lynhoo Tian, Yu Qiao and Chao Dong
(* indicates equal contribution)
This paper is accepted to ICCV 2021.
I will give a detailed interpretation about this work on Zhihu. The link will be released soon.
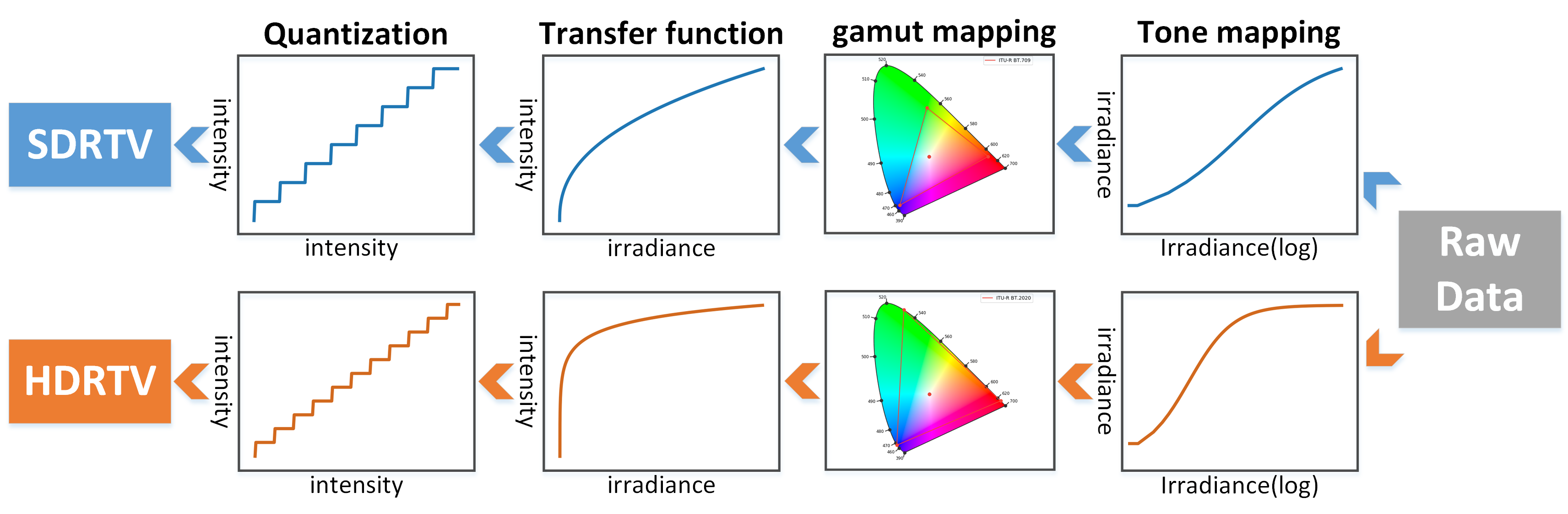
Simplified SDRTV/HDRTV formation pipeline:
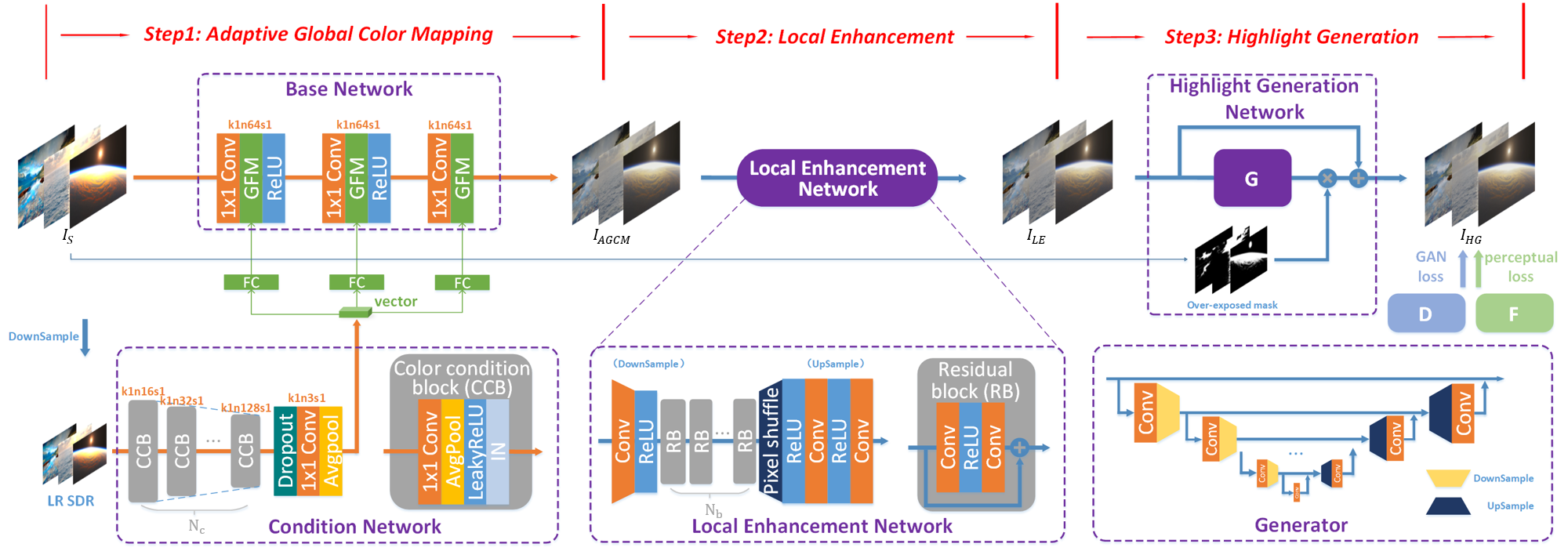
Overview of the method:
We conduct a dataset using videos with 4K resolutions under HDR10 standard (10-bit, Rec.2020, PQ) and their counterpart SDR versions from Youtube. The dataset consists of a training set with 1235 image pairs and a test set with 117 image pairs. Please refer to the paper for the details on the processing of the dataset. The dataset can be downloaded from Baidu Netdisk (access code: 6qvu) or OneDrive (access code: HDRTVNet). The training set is uploaded after subsection compression since it's too large. Please download the complete dataset to unzip.
We also provide the original Youtube links of these videos, which can be found in this file. Note that we cannot provide the download links since we do not have the copyright to distribute. Please download this dataset only for academic use.
Please refer to the requirements. Matlab is also used to process the data, but it is not necessary and can be replaced by OpenCV.
We provide the pretrained models to test, which can be downloaded from Baidu Netdisk (access code: 2me9) or OneDrive (access code: HDRTVNet). Since our method is casaded of three steps, the results also need to be inferenced step by step.
- Before testing, it is optional to generate the downsampled inputs of the condition network in advance. Make sure the
input_folderandsave_LR_folderin./scripts/generate_mod_LR_bic.mare correct, then run the file using Matlab. After that, matlab-bicubic-downsampled versions of the input SDR images are generated that will be input to the condition network. Note that this step is not necessary, but can reproduce more precise performance. Besides, if the pretrained HG model would be used, you should generate the masks of the input SDR images using./scripts/generate_mask.pyand modify the corresponding paths in the config files. - For the first part of AGCM, make sure the paths of
dataroot_LQ,dataroot_cond,dataroot_GTandpretrain_model_Gin./codes/options/test/test_AGCM.ymlare correct, then run
cd codes
python test.py -opt options/test/test_AGCM.yml
- Note that if the first step is not preformed, the line of
dataroot_condshould be commented. The test results will be saved to./results/Adaptive_Global_Color_Mapping. - For the second part of LE, make sure
dataroot_LQis modified into the path of results obtained by AGCM, then run
python test.py -opt options/test/test_LE.yml
- Note that results generated by LE can achieve the best quantitative performance. The part of HG is for the completeness of the solution and improving the visual quality forthermore. For testing the last part of HG, make sure
dataroot_LQis modified into the path of results obtained by LE, then run
python test.py -opt options/test/test_HG.yml
- Note that the results of the each step are 16-bit images that can be converted into HDR10 video.
- Prepare the data. Generate the sub-images with specific patch size using
./scripts/extract_subimgs_single.pyand generate the down-sampled inputs for the condition network (using the./scripts/generate_mod_LR_bic.mor any other methods). As the pipeline of the testing process, masks of SDR images need to be generated in advance if the HG part would be trained. - For AGCM, make sure that the paths and settings in
./options/train/train_AGCM.ymlare correct, then run
cd codes
python train.py -opt options/train/train_AGCM.yml
- For LE, the inputs are generated by the trained AGCM model. The original data should be inferenced through the first step (refer to the last part on how to test AGCM) and then be processed by extracting sub-images. After that, modify the corresponding settings in
./options/train/train_LE.ymland run
python train.py -opt options/train/train_LE.yml
- For HG, the inputs are also obtained by the last part LE, thus the training data need to be processed by similar operations as the previous two parts. When the data is prepared, it is recommended to pretrain the generator at first by running
python train.py -opt options/train/train_HG_Generator.yml
- After that, choose a pretrained model and modify the path of pretrained model in
./options/train/train_HG_GAN.yml, then run
python train.py -opt options/train/train_HG_GAN.yml
- All models and training states are stored in
./experiments.
Five metrics are used to evaluate the quantitative performance of different methods, including PSNR, SSIM, SR_SIM, Delta EITP (ITU Rec.2124) and HDR-VDP3. Since the latter three metrics are not very common in recent papers, we provide some reference codes in ./metrics for convenient usage.
Since HDR10 is an HDR standard using PQ transfer function for the video, the correct way to visualize the results is to synthesize the image results into a video format and display it on the HDR monitor or TVs that support HDR. The HDR images in our dataset are generated by directly extracting frames from the original HDR10 videos, thus these images consisting of PQ values look relatively dark compared to their true appearances. We provide the reference commands of our extracting frames and synthesizing videos in ./scripts. Please use MediaInfo to check the format and the encoding information of synthesized videos before visualization. If circumstances permit, we strongly recommend to observe the HDR results and the original HDR resources by this way on the HDR dispalyer.
If the HDR displayer is not available, some media players with HDR render can play the HDR video and show a relatively realistic look, such as Potplayer. Note that this is only an approximate alternative, and it still cannot fully restore the appearance of HDR content on HDR monitors.
If our work is helpful to you, please cite our paper:
@inproceedings{chen2021new,
title={A New Journey from SDRTV to HDRTV},
author={Chen, Xiangyu and Zhang, Zhengwen and Ren, Jimmy S. and Tian, Lynhoo and Qiao, Yu and Dong, Chao},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2021}
}
The code is inspired by BasicSR.