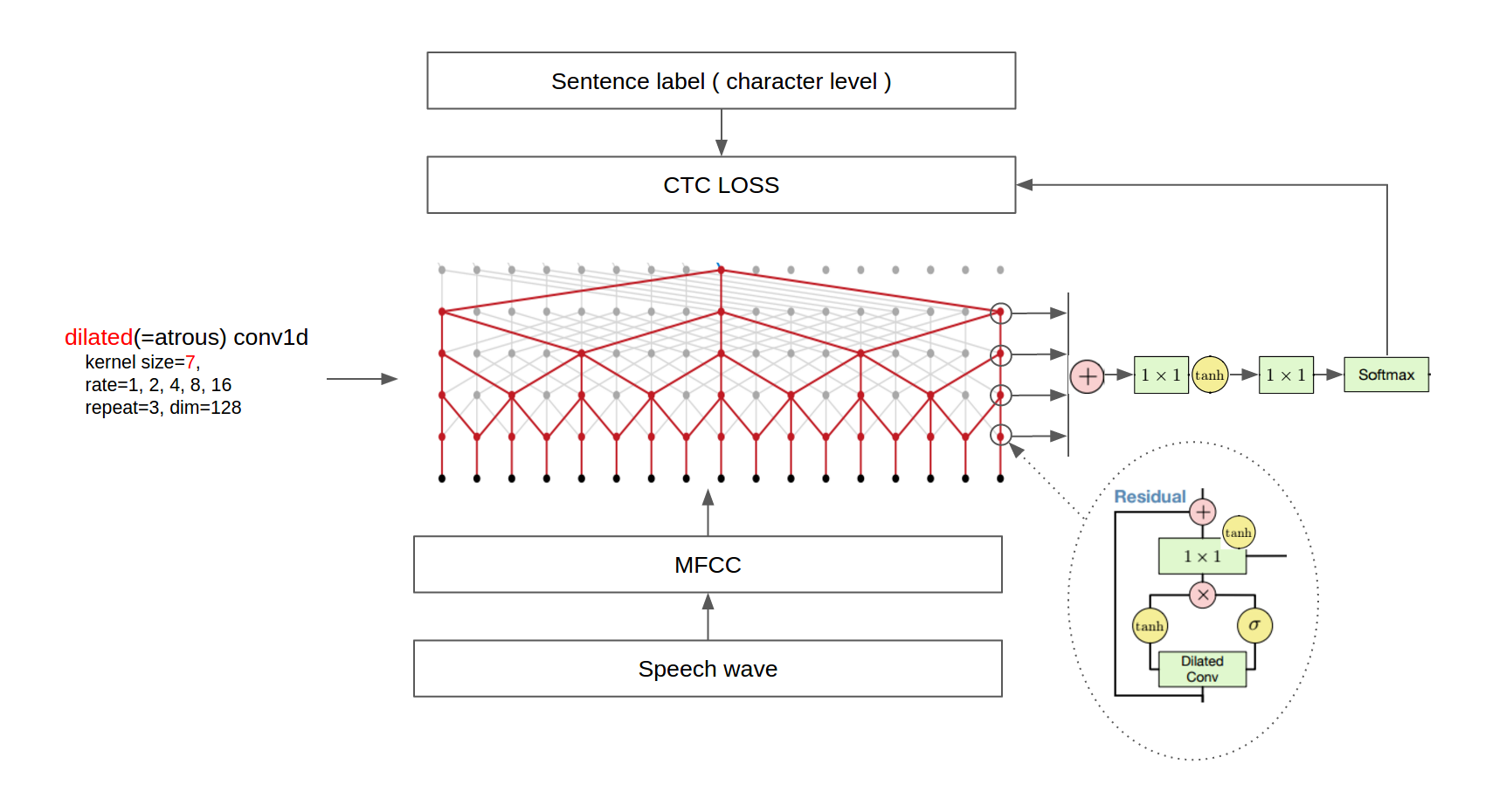
The architecture is shown in the following figure.
|
The WaveNet neural network architecture directly generates a raw audio waveform, showing excellent results in text-to-speech and general audio generation. The network models the conditional probability to generate the next sample in the audio waveform, given all previous samples and possibly additional parameters.
After an audio preprocessing step, the input waveform is quantized to a fixed integer range.
The integer amplitudes are then one-hot encoded to produce a tensor of shape A convolutional layer that only accesses the current and previous inputs then reduces the channel dimension. The core of the network is constructed as a stack of causal dilated layers, each of which is a dilated convolution (convolution with holes), which only accesses the current and past audio samples. The outputs of all layers are combined and extended back to the original number of channels by a series of dense postprocessing layers, followed by a softmax function to transform the outputs into a categorical distribution. The loss function is the cross-entropy between the output for each timestep and the input at the next timestep. In this repository, the network implementation can be found in wavenet.py. |
TensorFlow needs to be installed before running the training script. Code is tested on TensorFlow version 2 for Python 3.10
In addition, glog and librosa must be installed for reading and writing audio.
To install the required python packages, run
pip install -r requirements.txtTo run this project, install it locally.
You can use any corpus containing .wav files.
- We've mainly used the VCTK (around 10.4GB, Alternative host) so far.
- LibriSpeech
- TEDLIUM release 2
Create dataset
- Download and extract dataset(only VCTK support)
- Assume the directory of VCTK dataset is C:/speech_to_text, Execute to create record for train or test
python tools/create_tf_record.py -input_dir='C:/speech_to_text'
Execute to train model.
python train.py
Execute to evalute model.
python test.py
Demo
1.Download pretrain model Best model and extract to 'release' directory
Link to the best weight of the pretrained Wavenet
2.Execute to transform a speech wave file to the English sentence. The result will be printed on the console.
python demo.py -input_path <wave_file path>
For example, try the following command.
python demo.py -input_path=data/demo.wav -ckpt_model=release/<name of the modele>
Results
After the demo with a WAV file, the result of the sentence
Ask her to bring these things with her from the store"
is given in the figure below :

Ibab. tensorflow-wavenet 2016. GitHub repository. https://github.com/ibab/tensorflow-wavenet/.
L. Allioui, S. Brahami, B. Ghoul, A. Mezemate. WaveNet 2022. GitHub repository. https://github.com/LounesAl/WaveNet.