队伍 / 人数 1426 / 1764
A榜 0.65159296,6/468
B榜 0.59547145,9/108
进入总决赛,最终排名第5
- 李一鸣,**科学院计算技术研究所,liyiming22s1@ict.ac.cn
- 张兆,**科学院计算技术研究所,zhaozhao809@163.com
- 李想,**科学院自动化研究所,2300049883@qq.com
- 赵家乐,**科学院计算技术研究所,1007613549@qq.com
-
公开数据:仅使用官方训练集及部分官方A榜测试集(伪标签)进行模型训练,未使用任何外部数据。
-
预训练模型:百度ernie-3.0-base https://huggingface.co/nghuyong/ernie-3.0-base-zh
-
算法流程图:
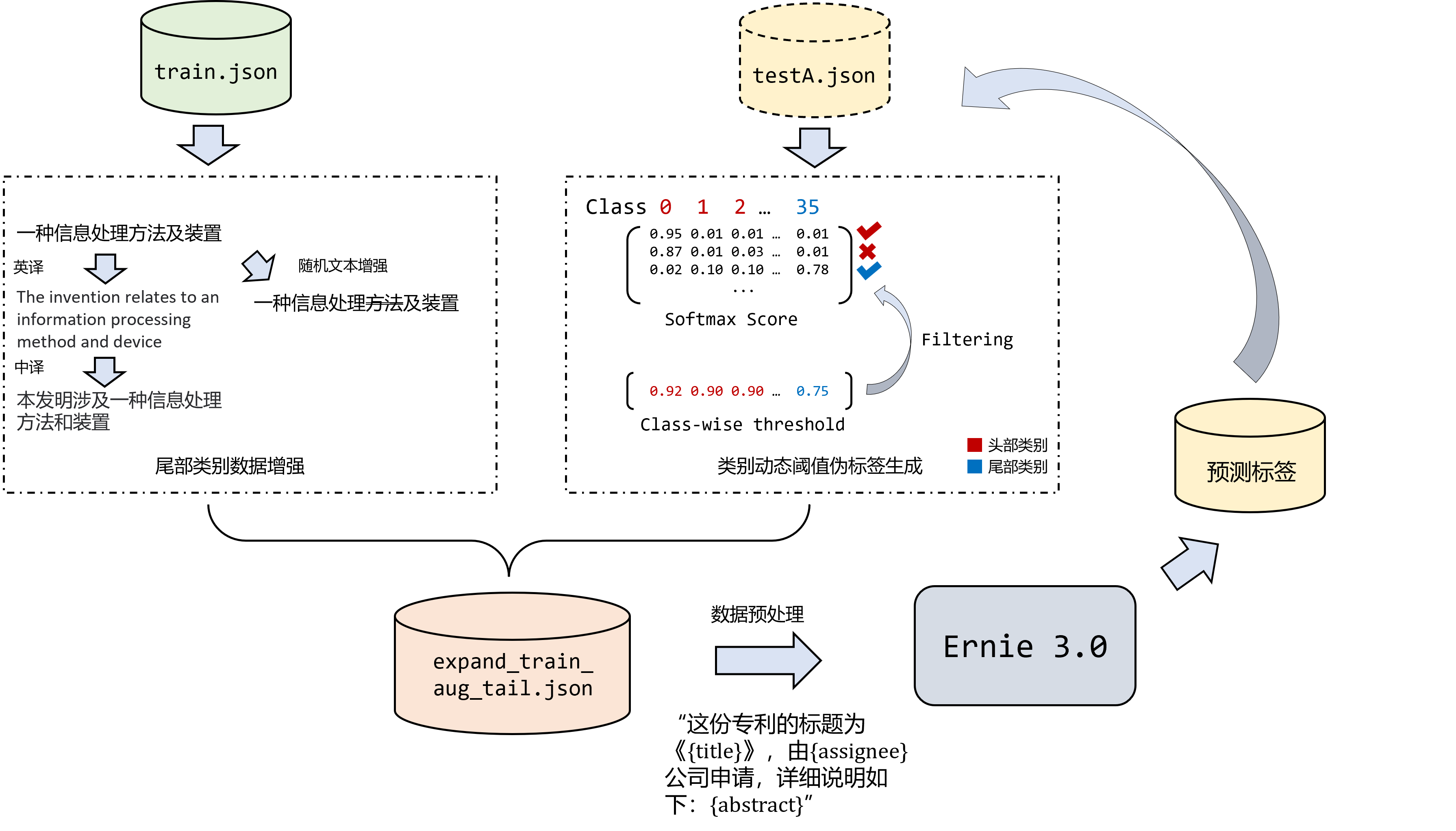
-
伪标签产生流程
传统的伪标签处理方法通常预先选定一个阈值
$c$ ,若模型对于测试样本的第$i$ 类的 softmax 分数大于$c$ ,则认为模型对于该样本的预测是较为可靠的,并将该样本连同其伪标签$i$ 加入到训练集中。在我们的做法中,我们考虑到训练数据集存在长尾分布,不再对于所有类别使用同一个固定阈值
$c$ ,而是为每一个类别$i$ 设置一个单独的阈值$c_i$ 。在确定第$i$ 类数据的伪标签阈值$c_i$ 时,我们首先筛选出所有预测标签为$i$ 的样本及其 softmax 分数,并将其按照 softmax 分数降序排列,选择第$\alpha$ 分位数(即从大到小排序在第$\alpha$ 的分数)的 softmax 分数作为阈值$c_i$ ,若此时产生的$c_i$ 小于一个固定阈值$fix_thresh$ ,则将其修正为$c_i^* = fix_thresh$ 。代码参见 add_pseudo_labels.py,生成的伪标签扩展数据集文件以"expand_train_"作为前缀 (如 expand_train_cur_best.json)。 -
数据增强流程
解决方案主要对官方训练数据集 train.json 中的尾部类别(12,22,32,35)进行如下两类数据增强:
-
使用英语、法语、德语、日语、韩语五门语言对其进行回译。代码参见 back_trans.py,生成的扩展数据集文件为 trans_aug_tail.json 。
-
使用 ChineseEDA 进行随机删除、增加、同义词替换等。代码参见 eda.py,生成的扩展数据集文件为 eda_data.json 。
将生成的 trans_aug_tail.json 及 eda_aug_tail.json 文件拼接在(经伪标签扩展)的训练数据集文件后,得到最终的训练文件,如在伪标签扩展的 expand_train_cur_best.json 文件后拼接 trans_aug_tail.json 、eda_aug_tail.json 文件得到训练文件 expand_train_cur_best_aug_tail.json 。
-
-
测试数据预处理流程
A、B 榜测试数据均直接送入模型进行推理,无特殊预处理。

最终进行预测的9个模型 路径:./models 和 ./docker/data/user_data/models
Docker镜像 路径:./docker/image/IMAGE.tar.gz
.
├── add_pseudo_labels.py # 伪标签生成代码
├── data # 用到的数据及增强数据文件
│ ├── alignlanguage.py # 根据回译结果修改数据集
│ ├── back_trans.py # 回译代码
│ ├── fewshot # 用到的所有数据文件
│ │ └── *.json
│ └── translate.py # 翻译数据
├── dataset.py # 模型数据处理
├── docker # 可以在提供的docker镜像里面一键运行的代码
├── eda.py # ChineseEDA 处理
├── ensemble # 模型集成代码
├── example_run.sh # 运行脚本示例
├── log.py # 日志记录配置
├── main.py # 主文件
├── model1.py # 模型架构文件
├── model_structures_try # 其他尝试的微调结构
├── models # 使用到的模型,包括训练日志和输出结果
├── requirements.txt # 依赖库
├── submit(FinalB) # 最终B榜提交文件
├── summary.md # 训练测试过程中的原始日志记录
├── tools # 一些小工具
└── trick.py # 模型训练技巧和其他损失函数等具体参数含义参考 main.py
使用的Python版本为3.8.13
pip install -r requirements.txt# Variables
SEED=42
K=1
GPU='2 3'
TEST_BATCH=128
TRAIN_FILE=train.json
LABEL=36
DROPOUT=0.3
MODEL=model1
# 直接联网下载模型文件
# BERT='nghuyong/ernie-3.0-base-zh'
# 调用已经下载好的原始文件
BERT='pretrained/nghuyong/ernie-3.0-base-zh'
TIMESTAMP=$(date +%Y_%m_%d_%H_%M_%S)python main.py \
--train \
--batch 12 --board --datetime ${TIMESTAMP} --epoch 1 --gpu ${GPU} --lr 2e-5 --seed ${SEED} --early_stop 10 \
--data_folder_dir fewshot --data_file ${TRAIN_FILE} --label ${LABEL} \
--checkpoint 20 --save \
--bert ${BERT} --dropout ${DROPOUT} --feature_layer 4 --freeze 0 --model ${MODEL} \
--K ${K} --split_test_ratio 0.2
# --en \
# --awp 1 --ema 0.999 --fgm --fl --mixif --pgd 3 --rdrop 0.1 --sce --swa --warmup 0.1python main.py \
--test \
--batch ${TEST_BATCH} --datetime ${TIMESTAMP} --gpu ${GPU} \
--data_folder_dir fewshot --data_file ${TRAIN_FILE} --label ${LABEL} \
--bert ${BERT} --dropout ${DROPOUT} --feature_layer 4 --freeze 0 --model ${MODEL} \
--K ${K}
# --en \python main.py \
--predict \
--batch ${TEST_BATCH} --datetime ${TIMESTAMP} --gpu ${GPU} \
--data_folder_dir fewshot --data_file testA.json --label ${LABEL} \
--bert ${BERT} --dropout ${DROPOUT} --feature_layer 4 --freeze 0 --model ${MODEL} \
--K ${K}
# predict_with_score \
# --en \python add_pseudo_labels.py \
--predict_csv result.csv \
--corpus_json testA.json --origin_train_json train.json \
--data_folder_dir fewshotpython ensemble.py \
--batch 256 --datetime $(date +%Y_%m_%d_%H_%M_%S) --gpu 2 3 \
--data_file data/fewshot/testA.json --model_folder_path models --label 36 \
--model_dict \
"[
{'name': '2022_10_28_15_41_45/best_1.pt', 'model': 'model5', 'bert': 'pretrained/nghuyong/ernie-3.0-base-zh', 'feature_layers': 4, 'dropout': 0.3, 'language': 'zh', 'swa': False},
{'name': '2022_10_28_15_41_45/best_2.pt', 'model': 'model5', 'bert': 'pretrained/nghuyong/ernie-3.0-base-zh', 'feature_layers': 4, 'dropout': 0.3, 'language': 'zh', 'swa': False},
{'name': '2022_10_28_15_41_45/best_3.pt', 'model': 'model5', 'bert': 'pretrained/nghuyong/ernie-3.0-base-zh', 'feature_layers': 4, 'dropout': 0.3, 'language': 'zh', 'swa': False},
]" \
--model_weight "[1, 1, 1]" \
# --score --single