这里存放了一些经典网络及其项目实战内容。
具体而言,是按照 CNN 发展时间节点来拟写存放的。
截至目前,编写完成的项目有:
- 1998 年——LeNet-5:这是 Yann LeCun 在 1998 年设计的用于手写数字识别的卷积神经网络。该项目自己搭建了 Lenet-5 网络并在 MNIST 手写数字识别项目中得到了应用。(注:该项目最令我印象深刻的是我自己验证了几年前学者验证的最大池化的效果是要优于平均池化的;这一点在本项目代码中并没有体现,原因是项目旨在遵循基准 LeNet-5 模型的各项指标,应用了基准模型设计的平均池化,若改为最大池化,训练代码中的优化器定义可删去动量项,亦可随之删去学习率变化代码,也可达到同样效果)

- 2012 年——AlexNet:这是 2012 年 ImageNet 竞赛冠军获得者 Hinton 和他的学生 Alex Krizhevsky 设计的。该项目自己搭建了 AlexNet 网络并在 MNIST 手写数字识别项目中得到了应用。(注:MNIST 手写数字识别数据集是单通道的,在该项目中用 numpy 库将图片依次转换为 3 通道在进行处理)
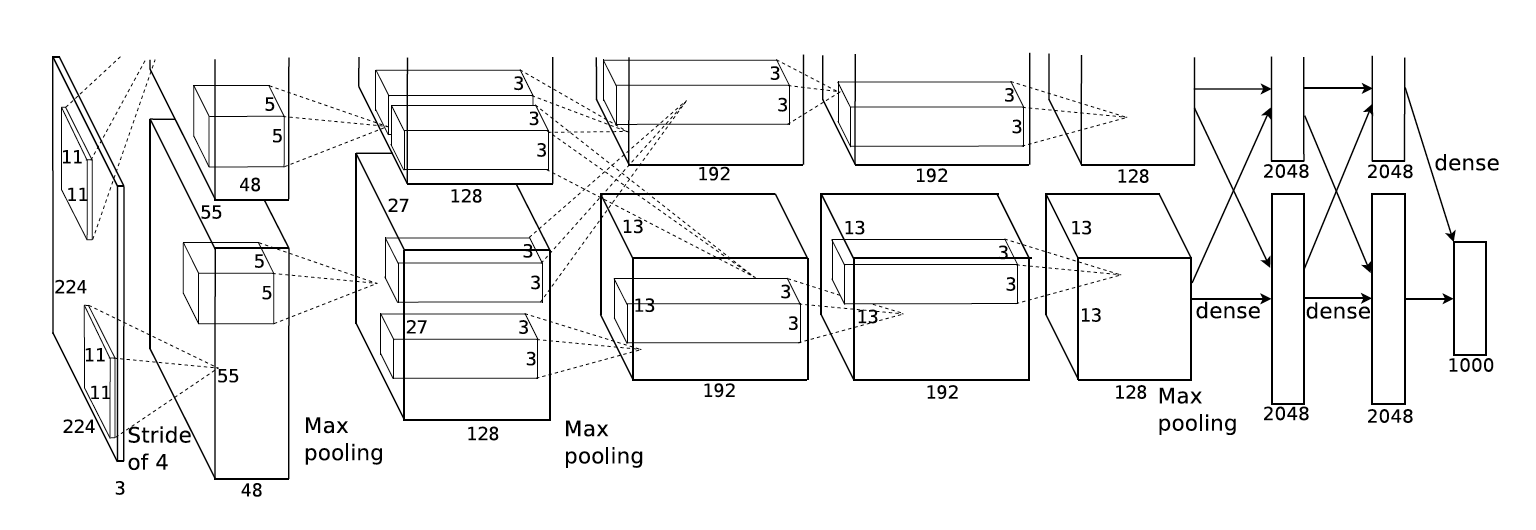
- 2014 年——VGGNet:这是 2014 年牛津大学计算机视觉组和 Google DeepMind 公司研究员一起研发的深度网络模型。该网络结构被分为 11,13,16,19 层;该项目自己搭建了 VGGNet 网络并在 MNIST 手写数字识别项目中得到了应用。(注:该项目主要修改了 AlexNet 应用实例中的 net.py 代码,由于输入图片通道数依然为 3 通道,所以延续了 AlexNet 应用实例中的 train.py 与 test.py ,仅调小了其中的 banch_size (由 16 变为了 8),以避免因 CUDA 内存不足而引起的报错)
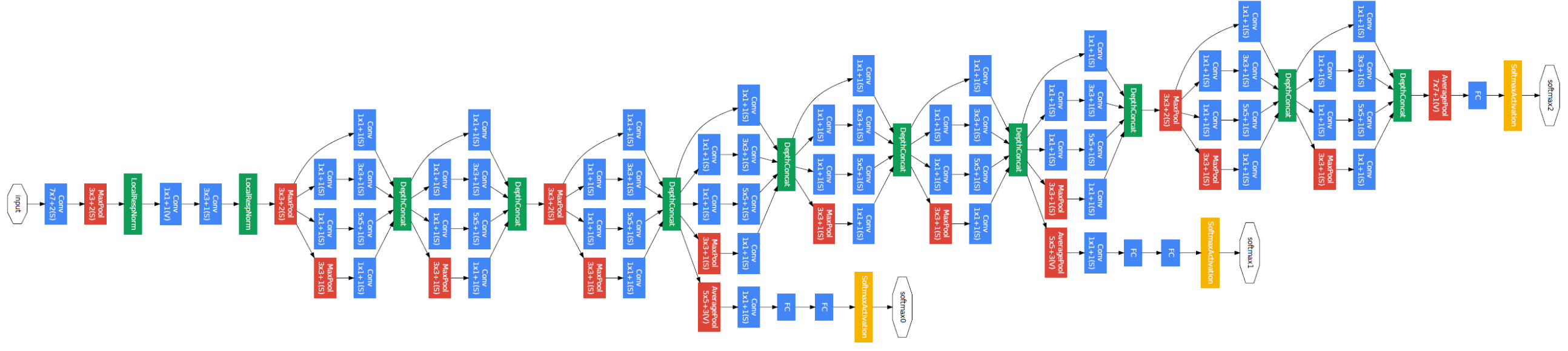
- 2014 年——GoogLeNet:这是 google 推出的基于 Inception 模块的深度神经网络模型,在 2014 年的 ImageNet 竞赛中夺得了冠军,在随后的两年中一直在改进,形成了 Inception V2、Inception V3、Inception V4 等版本。该项目自己搭建了 GoogLeNet 网络并在 MNIST 手写数字识别项目中得到了应用。(注:net.py 代码着实很长,原因是冗余的太多了,正像我的朋友吃午饭时讲的那样:“这个代码重复部分很多,完全可以写到一个函数里调用啊,这样写太没有灵魂了。”怎么说呢,主要当时快写完了,后来想想也是;也不能说这样写清晰地展现了 GoogLeNet 的架构,反而会让人觉得这是一个憨批程序员,一根筋,不懂得变通,所以这个自我复现的 GoogLeNet 版本的 net.py 文件代码就这样留着吧,也算是一个提醒,以后写代码在实现功能的基础上争取精简一些...)
- 2015 年——ResNet:这是由微软研究院的 Kaiming He 等四名华人提出,通过使用 ResNet Unit 成功训练出了 152 层的神经网络,并在 ILSVRC2015 比赛中取得冠军,在 top5 上的错误率为 3.57%,同时参数量比 VGGNet 低,效果非常突出。ResNet 的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时 ResNet 的推广性非常好,甚至可以直接用到 InceptionNet 网络中。该项目自己搭建了 ResNet18 网络并在 MNIST 手写数字识别项目中得到了应用。

- 2015 年——U-Net:2014 年,加州大学伯克利分校的 Long 等人提出全卷积网络(FCN),这使得卷积神经网络无需全连接层即可进行密集的像素预测,CNN 从而得到普及。a. U-net 建立在 FCN 的网络架构上,作者修改并扩大了这个网络框架,使其能够使用很少的训练图像就得到很 精确的分割结果。b. 添加上采样阶段,并且添加了很多的特征通道,允许更多的原图像纹理的信息在高分辨率的 layers 中进行传播。c. U-net 没有 FC 层,且全程使用 valid 来进行卷积,这样的话可以保证分割的结果都是基于没有缺失的上下文特征得到的,因此输入输出的图像尺寸不太一样( 但是在 keras 上代码做的都是 same convolution),对于图像很大的输入,可以使用 overlap-strategy 来进行无缝的图像输出。d. 为了预测输入图像的边缘部分,通过镜像输入图像来外推丢失的上下文,实则输入大图像也是可以的,但是这个策略基于 GPU 内存不够的情况下所提出的。e. 细胞分割的另外一个难点在于将相同类别且互相接触的细胞分开,因此作者提出了 weighted loss,也就是赋予相互接触的两个细胞之间的 background 标签更高的权重。网络分为四个主要部分:preprocessing、down convolution、up convolution、Output Map preprocessing 该项目自己搭建了 U-Net 网络并在 Semantic Segmentation 项目中得到了应用。

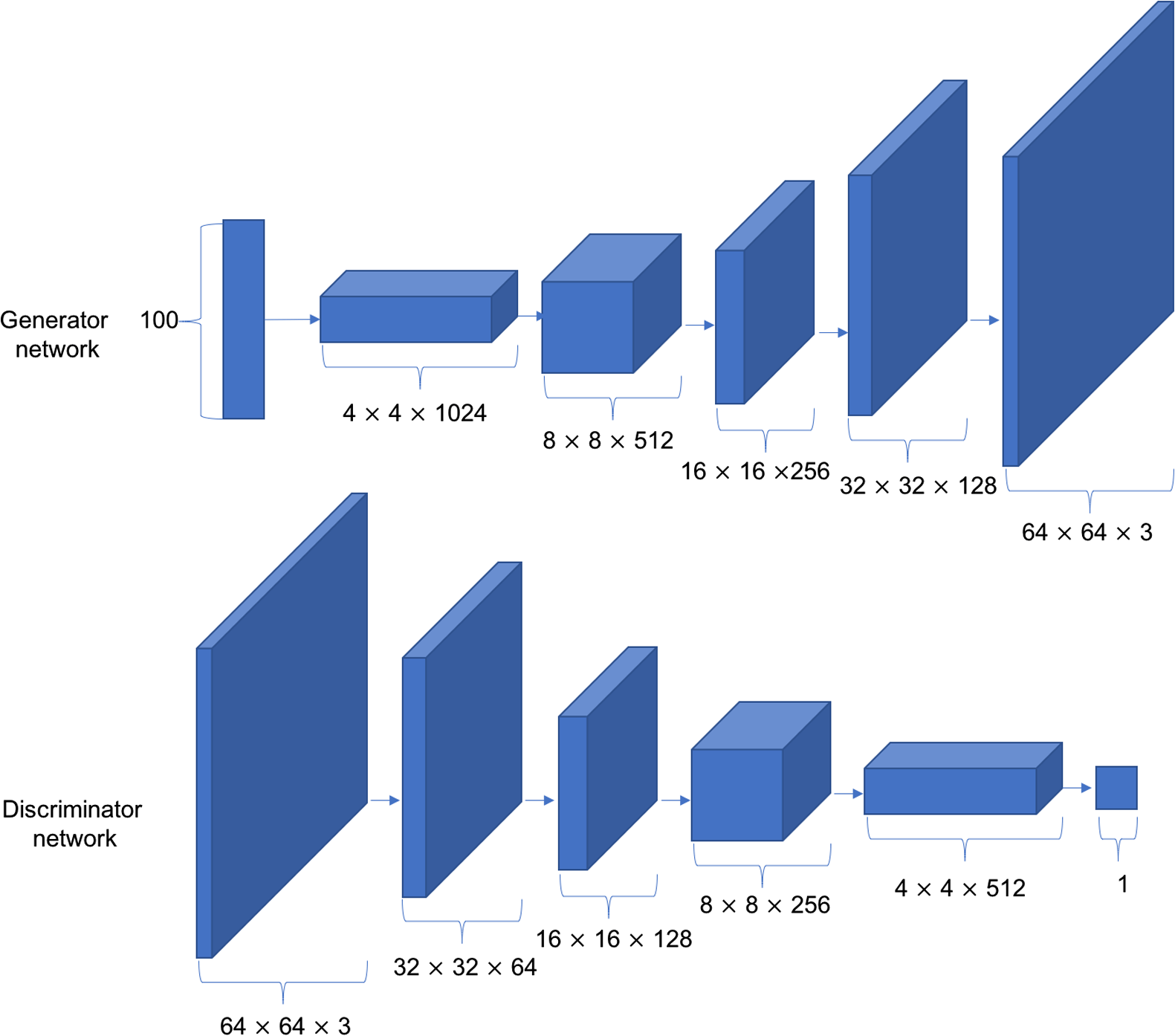
- 2016 年——DCGAN:深度卷积生成对抗网络(Deep Convolution Generative Adversarial Networks,简称DCGAN),其中包含判别器和生成器两部分。生成器 G 由 5 个转置卷积层单元堆叠而成,实现特征图高宽的层层放大,特征图通道数的层层减少。每个卷积层中间插入 BN 层来提高训练稳定性。判别器 D 与普通的分类网络相同,最后通过一个全连接层获得二分类任务的概率。GAN 的不稳定主要体现在超参数敏感和模式崩塌。超参数敏感:网络结构、学习率、初始化状态等这些都是超参数,这些超参数的一个微小的调整可能导致网络的训练结果截然不同;模式崩塌(Mode Collapse):是指模型生成的样本单一,多样性很差的现象。由于鉴别器只能鉴别单个样本是否采样自真实分布,并没有对样本多样性进行约束,导致生成模型倾向于生成真实分布的部分区间中的少量高质量样本,以此来在鉴别器中获得较高的概率值,而不会学习到全部的真实分布。该项目自己搭建了 DCGAN 网络(包括生成器与判别器两部分)并在 Image Production 项目中得到了应用。
- 2017 年——Mask-RCNN:Mask-RCNN 是 ICCV2017 best paper, 是 FAIR 团队的 Kaiming 大神和 RBG 大神的强强联手之作,是在 Faster R-CNN 的基础上添加了一个预测分割 mask 的分支。Mask R-CNN = Faster R-CNN + FCN。通过在 Faster-RCNN 的基础上添加一个分支网络,在实现目标检测的同时,把目标实例分割。什么是 Instance segmentation,就是将一幅图像中所有物体框出来,并将物体进行像素级别的分割提取。

- 2019 年——MobileNet-v3:这是 Google 在 2019 年 3 月 21 日提出的网络架构,也是继 MobileNet-v2 之后的又一力作,MobileNet-v3 small 在 ImageNet 分类任务上,较 MobileNet-v2,精度提高了大约 3.2%,时间却减少了 15%,MobileNet-v3 large 在 imagenet 分类任务上,较 MobileNet-v2,精度提高了大约 4.6%,时间减少了 5%,MobileNet-v3 large 与 v2 相比,在 COCO 上达到相同的精度,速度快了 25%,同时在分割算法上也有一定的提高。论文还有一个亮点在于,网络的设计利用了 NAS(network architecture search)算法以及 NetAdapt algorithm 算法。并且,论文还介绍了一些提升网络效果的 trick,这些 trick 也提升了不少的精度以及速度。
