BloomBlog https://github.com/Agelessbaby/BloomBlog
A backend social media project using Kitex + Hertz + RPC + Kubernetes,supporting functionalities for publishing posts, adding comments, liking posts, and dynamically retrieving them in a feed-like manner
- 1:Main Features
- 2:Description
- 3:Database Schema
- 4:Code Arch
- 5:Logical Arch
- 6:Physical Arch
- 7:How to Use?
-
Using Kitex as micro services framework and Hertz as HTTP Api gateway(both open sourced by bytedance)
-
Using AWS S3 as object storage
-
Using rabbitmq as message queue
-
Using Docker and Kubernetes as deployment
| Service | Description | Techniques | Protocol | service registry |
|---|---|---|---|---|
| api | Routing HTTP request to RPC Services | Gorm Kitex Hertz |
http |
CoreDNS |
| user | User Management | JWT |
proto3 |
CoreDNS |
| relation | User Following Management | - | - | CoreDNS |
| feed | Posts Stream | - | - | CoreDNS |
| favorite | Favorite Management | - | - | CoreDNS |
| comment | Comment Management | rabbitmq |
- | CoreDNS |
| publish | Posts Publish Management | AWS S3 |
- | CoreDNS |
| dal | Data Access Layer | MySQL gorm |
- | CoreDNS |


| Directory | Sub Directory | Description | Remarks |
|---|---|---|---|
| cmd | api | api gateway | |
| comment | comment service | ||
| favorite | favorite service | ||
| feed | feed service | ||
| publish | publish service | ||
| relation | relation service | ||
| user | user service | ||
| config | Config file for services and infrastructure | ||
| dal | db | Including Gorm operations and initialization | |
| pack | Packing Gorm struct into RPC struct | ||
| idl | protobuf idl file | ||
| kitex_gen | Code generated by Kitex | ||
| util | mq | Message queue used in comment service(could be expanded to other services) | |
| errno | error code | ||
| jwt | Using SHA256 and BASE64 | ||
| oss | AWS S3 oss, compatible with minio | ||
| config | Viper Reading configurations | ||
| config | Config file for each service and infrasctructures | ||
| kubernetes | Kubernetes description yaml files | ||
| script | Shell Scripts for kubernetes deployment, setting up Kind cluster and executing some needed sql operations(not creating database or tables) | ||
| kubernetes | Shell files that create and deploy kubernetes cluster, building and loading images, etc |



- Docker
- Using a Linux or Mac machine(Win is ok but you need to change the scripts)
- Having a AWS account and adjust the S3 Endpoint and bucket name to yours(in config/ossConfig.yaml)
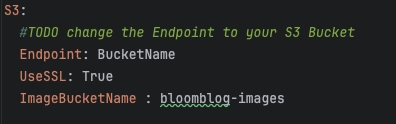
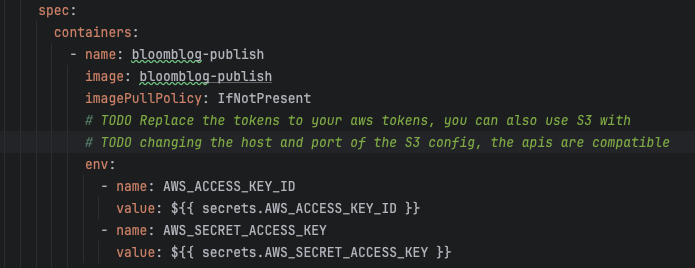
- Overwrite your AWS tokens in config/kubernetes/services/publish.yaml,make sure your IAM role has the access to S3
- Install Swagger
Verify
go install github.com/swaggo/swag/cmd/swag@latest
Init Api fileswag --version
swag init -g cmd/api/main.go


-
Make sure you have installed Docker on your machine
-
Install Kind - Kubernetes IN Docker
For Macbrew install kind
For Ubunut
sudo apt install kind
Verify Installation
kind --version
-
Grant executable permission to the .sh files
chmod -R +x script/* -
Create Kubernetes Cluster
kind create cluster --config ./config/kubernetes/cluster-bloomblog.yaml
Verify creating cluster
kubectl cluster-info --context kind-bloomblog
You should see output like

-
Build Docker images
./script/kubernetes/build_images.sh
-
Loading images into Kubernetes cluster
./script/kubernetes/kind/load_images.sh
-
Deploy Infra(Mysql,Rabbitmq)
./script/kubernetes/deploy-infra.sh
-
Deploy Services
./script/kubernetes/deploy.sh
-
Start a kubernetes job
kubectl apply -f config/kubernetes/infra/jobs/add_casscade.yaml
-
Verify Deployment
Verify Pods

kubectl get podVerify Services
kubectl get service- Use Swagger to debug
Swagger
For Publish service, Swagger doesn't support multi files upload, youcan use this postman link
Postman
- You can build your own frontend based on this project, the frontend is still developing
- I intended to build this project using cloud native solution, however the price for Amazon Mq and NAT is so expensive, you can build it yourself if the budget permits
- Now there is only RDBMS, decided that to later apply nosql to build a cache aside architecture
- The logstash filter is a little bit hard, still working on it.This is for to collect the database queries that exceed the time threshold