Gesture-Nauts - Invokes the spirit of exploration and adventure in the realm of gesture-based technology
The idea of our project is to implement a 3D gesture recognition system that provides corresponding animations upon recognition.
The current backdrop is characterized by the frequent use of smart devices to simplify our lives. Various new technologies leveraging AI emphasize interaction with humans to unlock new functionalities. Gesture recognition, historically a fundamental cognitive function in humans, is now being automated through the rise of AI technologies. This advancement in computer technology is gradually implemented in various smart devices, such as smartphones, smart home systems, and virtual reality (VR) setups. This integration enables more intuitive and efficient ways for users to interact with technology, allowing for gesture-based commands that can control everything from music playback to complex navigation within virtual environments. As a result, gesture recognition is not only redefining the boundaries of human-computer interaction but is also paving the way for more personalized and seamless digital experiences.
HaGRID - HAnd Gesture Recognition Image Dataset
HaGRID size is 716GB and dataset contains 552,992 FullHD (1920 × 1080) RGB images divided into 18 classes of gestures. Also, some images have
no_gestureclass if there is a second free hand in the frame. This extra class contains 123,589 samples. The data were split into training 92%, and testing 8% sets by subject user-id, with 509,323 images for train and 43,669 images for test.
The dataset contains 34,730 unique persons and at least this number of unique scenes. The subjects are people from 18 to 65 years old. The dataset was collected mainly indoors with considerable variation in lighting, including artificial and natural light. Besides, the dataset includes images taken in extreme conditions such as facing and backing to a window. Also, the subjects had to show gestures at a distance of 0.5 to 4 meters from the camera.
The annotations consist of bounding boxes of hands with gesture labels in COCO format
[top left X position, top left Y position, width, height]. Also, annotations have 21landmarksin format[x,y]relative image coordinates, markups ofleading hands(leftofrightfor gesture hand) andleading_confas confidence forleading_handannotation. We provideuser_idfield that will allow you to split the train / val dataset yourself.
In our project, we use the subsample of the above dataset as the whole dataset is too big and slow for us to train. Subsample has 100 items per gesture class (~2.5GB) and the annotations of subsample (~1.2MB).
The subsample, the feature generated from the mediapipe's hands model, the keypoint classifier and keypoint_classifier_label can be found here.
We add some data augmentation to our subsample dataset (flip,scale,rotate, etc.) to help us train a more robust model.

- Keypoint Classifier Model Structure

- Keypoint classifier train/val curve


- Keypoint Classifier Confusion Matrix

- Keypoint Class Mapping
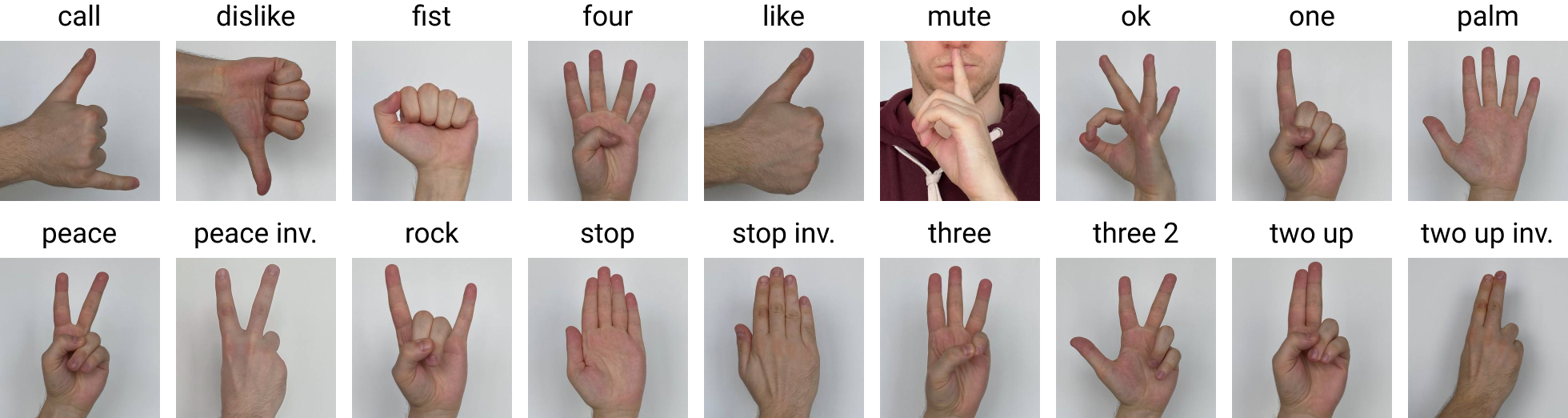
| Index | class |
|---|---|
| 0 | call |
| 1 | dislike |
| 2 | fist |
| 3 | four |
| 4 | like |
| 5 | mute |
| 6 | ok |
| 7 | one |
| 8 | stop_inverted |
| 9 | rock |
| 10 | peace_inverted |
| 11 | stop |
| 12 | palm |
| 13 | peace |
| 14 | three |
| 15 | three2 |
| 16 | two_up |
| 17 | two_up_inverted |
- Keypoint Classification_report

A model to visualize the history of fingertip coordinates. We did not train this on ourselves since we have to manually collect the dataset. Instead, we use a pretrained point_history classifier to visualize the history.
If you run python app.py, you can press "h" to enter the mode to save the history of fingertip corrdinates (displayed as "MODE:Logging Point History").
python app.py
-
--device
Specifying the camera device number (Default:0)
-
--width
Width at the time of camera capture (Default:960)
-
--height
Height at the time of camera capture (Default:540)
-
--use_static_image_mode
Whether to use static_image_mode option for MediaPipe inference (Default:Unspecified)
-
--min_detection_confidence
Detection confidence threshold (Default:0.5)
-
--min_tracking_confidence
Tracking confidence threshold (Default:0.5)
Run the following command to view it
python web.py
-
mediapipe 0.8.1
-
OpenCV 3.4.2 or Later
-
Tensorflow 2.3.0 or Later
-
tf-nightly 2.5.0.dev or later
-
scikit-learn 0.23.2 or Later
-
matplotlib 3.3.2 or Later
We also provide our requirement.txt file. So all you need to do is:
pip install -r requirements.txt
There might be some differences between Mac and Windows for TensorFlow packages, so when there is a conflict, you have to resolve it manually.
-
Download the HaGRID's image & annotation subset from HaGRID kaggle webpage or our google drive. If you download from google drive, we are refer to the
ori_datasetandann_subsamplefolder. Put both of these inside theGesture-Nauts > datasetfolder -
Run
dataset_generator.ipynbinside theGesture-Nauts > datasetfolder to get the 43 dimension feature map where the 1st dimension is the label and the following 42 dimensions is the location information we extract from our dataset image using the pretrained mediapipe's hands model. -
After running step 2, we get 2 csv file
keypoint.csvandkeypoint_classifier_label.csvwherekeypoint.csvis kind of feature map andkeypoint_classifier_label.csvis the dataset labels. These 2 csv file can be found in the dataset folder after running step 2. And we need to make a copy and place the copy inside themodel/fine_tune_keypoint_classifierfolder. -
We run
keypoint_classification.ipynbfile inside themodel/fine_tune_keypoint_classifierfolder to train our classifier adapter based on our dataset. This file trains our classifier and generate its corresponding checkpoints, which can be found inmodel/keypoint_classifier/keypoint_classifier.tflitefile. -
Run
python app.py, which serves as pipeline to use our trained model to detect gesture generation.
Todo: description about history classifier: will do that later.
We plan on working equally across X aspects of the project:
-
Dataset generator: Chen Wei
-
Design the model: Together
-
Model Architecture: Chen Wei
- Feature Generator (Use mediapipe's hands pretrained model)
- Keypoint classifier
- Point history classifier
- Evaluation and and Visualization: Kangyu Zhu
- Fine-tune the model, change the structure and parameters: Together
- Model Training: Together
- Local Model Demo: Zhongzheng Xu
- Write the report and make the poster: Together
Our project ultimately turned out to be ok and our model works as expected. It can classify gestures that are acceptable and coherent although not being perfect.
Current issues:
- Our model performs well for some classes, while it does not perform well for others. We have tried various types of model combinations to solve this problem.
- The combination include (1)using dense layer + no data augmentation (2) using dense layer + data augmentation (3) using convolution layer + no data augmentation (4) using convolution layer + data augmentation. More details can be found in our final report.
If we have more time, we could implement:
- Besides data augmentation, we can use a bigger dataset to train our model.
- Try more hyperparameter settings.
- Manually collect the point_history data and also train the point_history_classifier based on our model.