This repository contains scripts and data for scraping articles from the GoV.UK website. The project aims to extract the date, content, and title of approximately 6000 articles from GoV.UK. The extracted data is stored in a JSON format and can be further processed for analysis.
Before running the scripts, ensure that you have the following dependencies installed:
- Python 3
requestslibrarybeautifulsoup4librarypandaslibrarynltklibrarywordnetcorpus (fromnltk)omw-1.4corpus (fromnltk)
You can install the required libraries by running the following command: pip install -r Requirements.txt
myspider.py: Uses Scrapy framework to scrape the GoV.UK articles and extract the title, content, and URL of each article.web_scrapper.py: Uses BeautifulSoup and requests to scrape the GoV.UK articles, extract the text and date, and update the JSON data.preprocess.py: Preprocesses the data stored inarticles.jsonfor further analysis.URLs.json: Contains the URLs of the GoV.UK articles to be scraped.articles.json: Contains the scraped article data including the title, content, and date.
The myspider.py script uses the Scrapy framework to crawl the GoV.UK website, extract the title, content, and URL of each article, and store the data in the articles.json file.
To run the script, execute the following command: scrapy runspider myspider.py -o articles.json
The web_scrapper.py script uses BeautifulSoup and requests libraries to scrape the GoV.UK articles listed in the URLs.json file. It extracts the text and date from each article and updates the JSON data in the articles.json file.
To run the script, execute the following command: python web_scrapper.py URLs.json
The preprocess.py script preprocesses the scraped JSON data stored in the articles.json file. It performs various text processing steps, such as converting to lowercase, removing punctuation, numbers, and stopwords, lemmatizing, stemming, and removing specific words. It also filters the data based on the date and converts the date column to year-month periods.
To run the script, execute the following command: python preprocess.py articles.json
-
Using Scrapy to scrape GoV.UK articles:
-
Make sure the
URLs.jsonfile contains the URLs of the GoV.UK articles to be scraped. -
Run the following command to start the Scrapy spider and save the extracted data in the
articles.jsonfile:scrapy runspider myspider.py -o articles.json
-
-
Using BeautifulSoup and requests to scrape GoV.UK articles:
-
Make sure the
URLs.jsonfile contains the URLs of the GoV.UK articles to be scraped. -
Run the following command to scrape the articles and update the JSON data in the
articles.jsonfile:python web_scrapper.py URLs.json
-
Contributions to this repository are welcome. If you encounter any issues or have suggestions for improvement, please open an issue or submit a pull request.
The repository provides functionality to generate various visualizations based on the scraped data. Here are some examples:
The repository provides functionality to generate various visualizations based on the scraped data. Here are some examples:
The repository provides functionality to generate various visualizations based on the scraped data. Here are some examples:
-
Word Cloud of Articles:
Generate a word cloud visualization based on the content of the articles. This visualization helps to understand the most frequently occurring words in the articles.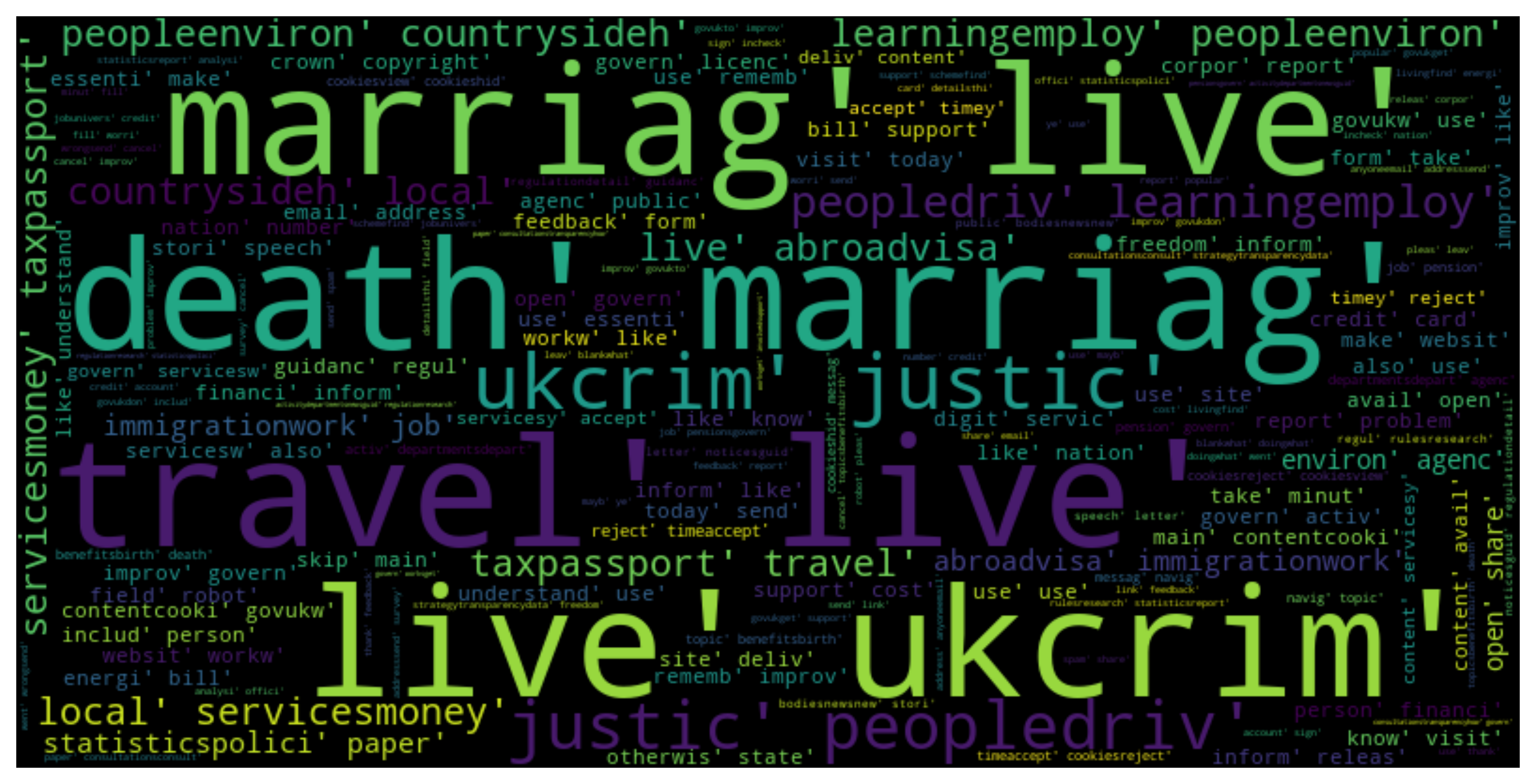
-
Word Cloud of Titles:
Generate a word cloud visualization based on the titles of the articles. This visualization helps to identify the most common words used in the titles.
-
Occurrence over Time Plot:
Generate a plot showing the occurrence of articles over time. This visualization helps to understand the distribution of articles across different time periods.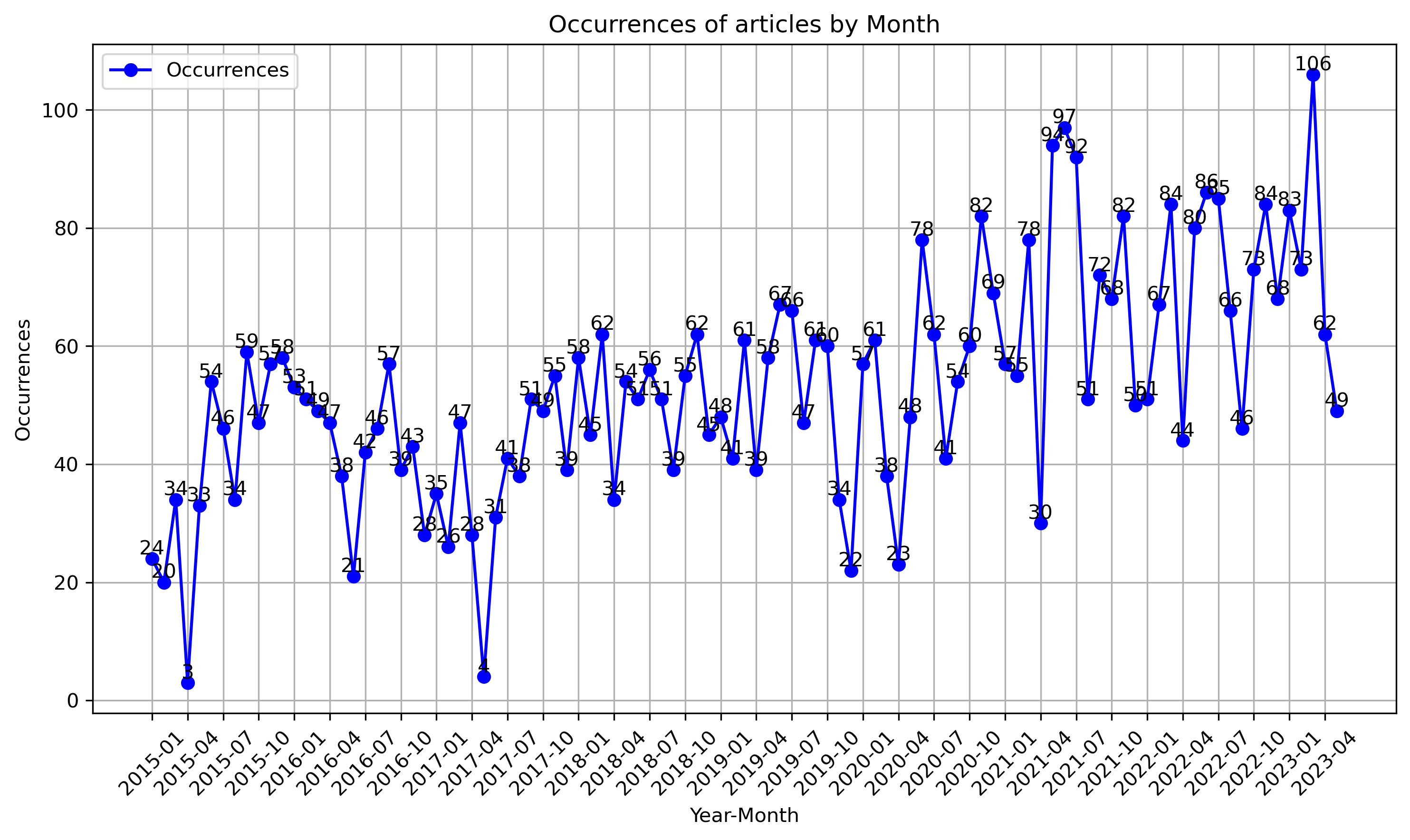
-
Distribution of Number of Words per Document:
Generate a distribution plot showing the number of words in each document. This visualization helps to understand the length distribution of the articles.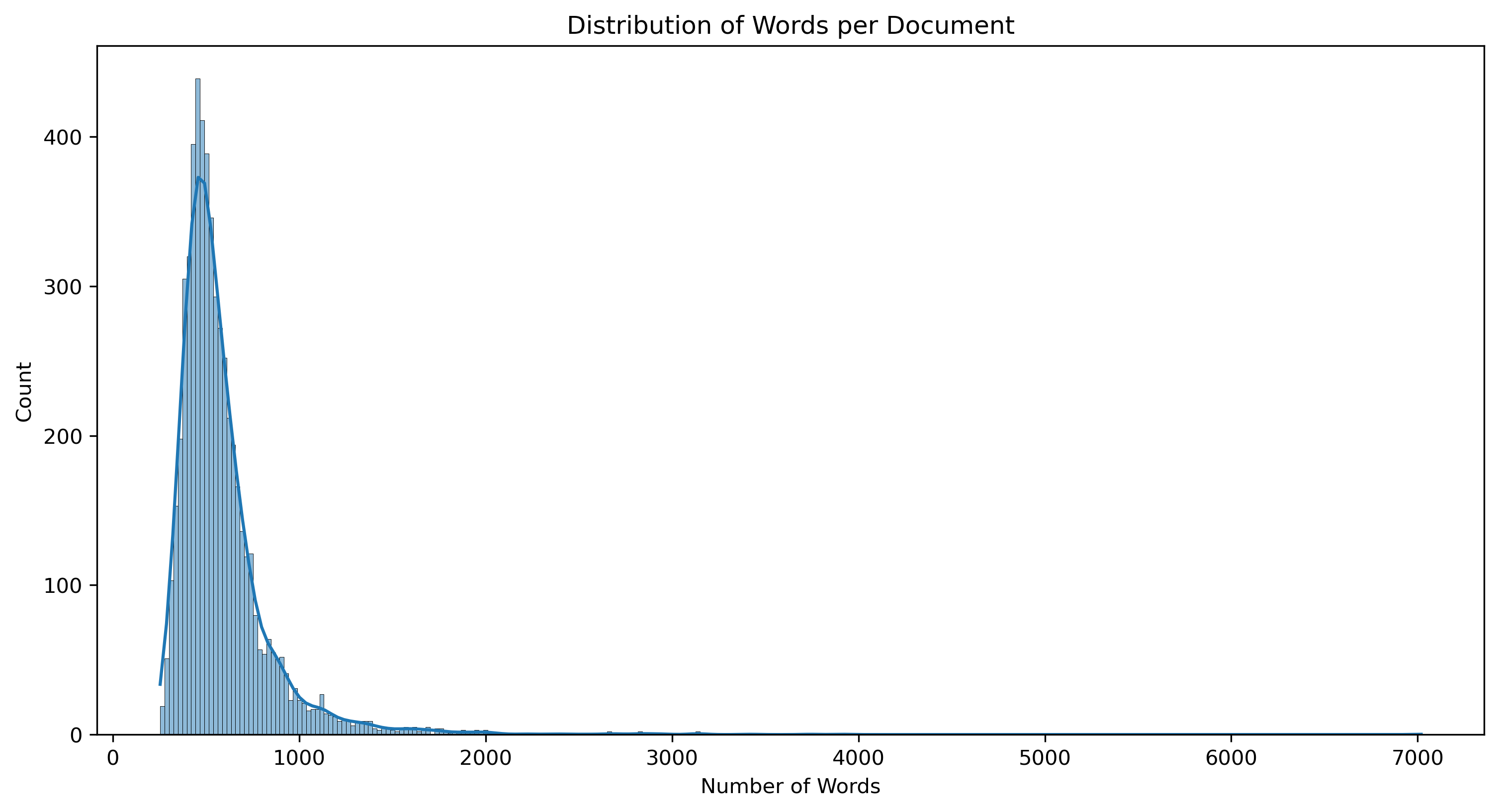




Please refer to the documentation of the above libraries for more information on their usage.