DanceTrack is a benchmark for tracking multiple objects in uniform appearance and diverse motion.
DanceTrack provides box and identity annotations. It contains 100 videos, 40 for training(annotations public), 25 for validation(annotations public) and 35 for testing(annotations unpublic). For evaluating on test set, please see CodaLab(Old CodaLab). We also have a Project Page for exhibition.

DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion
- (05/2023) We list some awesome research papers and projects here you may find interesting. Welcome new pull request to add new links !
- (04/2022) We are organizing Multiple Object Tracking and Segmentation in Complex Environments Workshop, ECCV 2022.
| Title | Intro | Description | Links |
|---|---|---|---|
| SUSHI |  |
Unifying Short and Long-Term Tracking with Graph Hierarchies | [Github] |
| MOTRv2 | 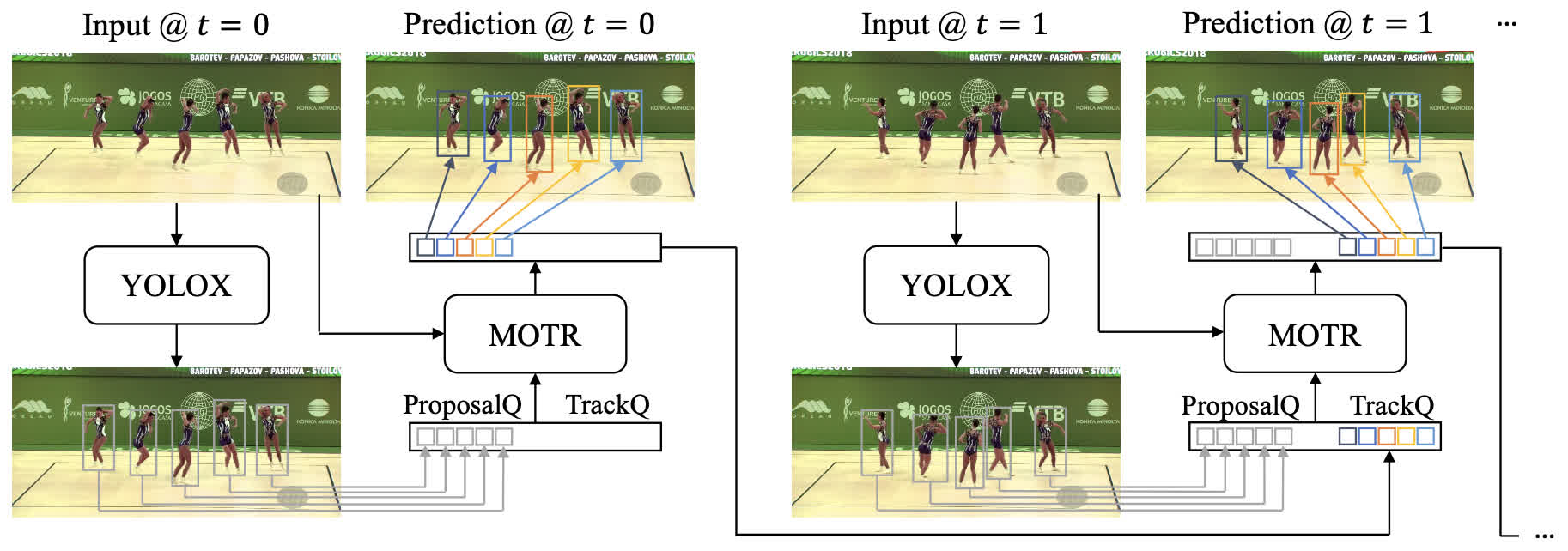 |
MOTRv2: Bootstrapping End-to-End Multi-Object Tracking by Pretrained Object Detectors | [Github] |
| MOT_FCG | Multiple Object Tracking from appearance by hierarchically clustering tracklets | Multiple Object Tracking from appearance by hierarchically clustering tracklets | [Github] |
| OC-SORT |  |
Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking | [Github] |
| StrongSORT |  |
StrongSORT: Make DeepSORT Great Again | [Github] |
| MOTR |  |
MOTR: End-to-End Multiple-Object Tracking with TRansformer | [Github] |
Download the dataset from Google Drive or Baidu Drive (code:awew).
Organize as follows:
{DanceTrack ROOT}
|-- dancetrack
| |-- train
| | |-- dancetrack0001
| | | |-- img1
| | | | |-- 00000001.jpg
| | | | |-- ...
| | | |-- gt
| | | | |-- gt.txt
| | | |-- seqinfo.ini
| | |-- ...
| |-- val
| | |-- ...
| |-- test
| | |-- ...
| |-- train_seqmap.txt
| |-- val_seqmap.txt
| |-- test_seqmap.txt
|-- TrackEval
|-- tools
|-- ...
We align our dataset annotations with MOT, so each line in gt.txt contains:
<frame>, <id>, <bb_left>, <bb_top>, <bb_width>, <bb_height>, 1, 1, 1
We use ByteTrack as an example of using DanceTrack. For training details, please see instruction. We provide the trained models in Google Drive or or Baidu Drive (code:awew).
To do evaluation with our provided tookit, we organize the results of validation set as follows:
{DanceTrack ROOT}
|-- val
| |-- TRACKER_NAME
| | |-- dancetrack000x.txt
| | |-- ...
| |-- ...
where dancetrack000x.txt is the output file of the video episode dancetrack000x, each line of which contains:
<frame>, <id>, <bb_left>, <bb_top>, <bb_width>, <bb_height>, <conf>, -1, -1, -1
Then, simply run the evalution code:
python3 TrackEval/scripts/run_mot_challenge.py --SPLIT_TO_EVAL val --METRICS HOTA CLEAR Identity --GT_FOLDER dancetrack/val --SEQMAP_FILE dancetrack/val_seqmap.txt --SKIP_SPLIT_FOL True --TRACKERS_TO_EVAL '' --TRACKER_SUB_FOLDER '' --USE_PARALLEL True --NUM_PARALLEL_CORES 8 --PLOT_CURVES False --TRACKERS_FOLDER val/TRACKER_NAME
| Tracker | HOTA | DetA | AssA | MOTA | IDF1 |
|---|---|---|---|---|---|
| ByteTrack | 47.1 | 70.5 | 31.5 | 88.2 | 51.9 |
Besides, we also provide the visualization script. The usage is as follow:
python3 tools/txt2video_dance.py --img_path dancetrack --split val --tracker TRACKER_NAME

Organize the results of test set as follows:
{DanceTrack ROOT}
|-- test
| |-- tracker
| | |-- dancetrack000x.txt
| | |-- ...
Each line of dancetrack000x.txt contains:
<frame>, <id>, <bb_left>, <bb_top>, <bb_width>, <bb_height>, <conf>, -1, -1, -1
Archive tracker folder to tracker.zip and submit to CodaLab. Please note: (1) archive tracker folder, instead of txt files. (2) the folder name must be tracker.
The return will be:
| Tracker | HOTA | DetA | AssA | MOTA | IDF1 |
|---|---|---|---|---|---|
| tracker | 47.7 | 71.0 | 32.1 | 89.6 | 53.9 |
For more detailed metrics and metrics on each video, click on download output from scoring step in CodaLab.
Run the visualization code:
python3 tools/txt2video_dance.py --img_path dancetrack --split test --tracker tracker
We use joint-training with other datasets to predict mask, pose and depth. CenterNet is provided as an example. For details of joint-trainig, please see joint-training instruction. We provide the trained models in Google Drive or Baidu Drive(code:awew).
For mask demo, run
cd CenterNet/src
python3 demo.py ctseg --demo ../../dancetrack/val/dancetrack000x/img1 --load_model ../models/dancetrack_coco_mask.pth --debug 4 --tracking
cd ../..
python3 tools/img2video.py --img_file CenterNet/exp/ctseg/default/debug --video_name dancetrack000x_mask.avi

For pose demo, run
cd CenterNet/src
python3 demo.py multi_pose --demo ../../dancetrack/val/dancetrack000x/img1 --load_model ../models/dancetrack_coco_pose.pth --debug 4 --tracking
cd ../..
python3 tools/img2video.py --img_file CenterNet/exp/multi_pose/default/debug --video_name dancetrack000x_pose.avi

For depth demo, run
cd CenterNet/src
python3 demo.py ddd --demo ../../dancetrack/val/dancetrack000x/img1 --load_model ../models/dancetrack_kitti_ddd.pth --debug 4 --tracking --test_focal_length 640 --world_size 16 --out_size 128
cd ../..
python3 tools/img2video.py --img_file CenterNet/exp/ddd/default/debug --video_name dancetrack000x_ddd.avi

- The annotations of DanceTrack are licensed under a Creative Commons Attribution 4.0 License.
- The dataset of DanceTrack is available for non-commercial research purposes only.
- All videos and images of DanceTrack are obtained from the Internet which are not property of HKU, CMU or ByteDance. These three organizations are not responsible for the content nor the meaning of these videos and images.
- The code of DanceTrack is released under the MIT License.
The evaluation metrics and code are from MOT Challenge and TrackEval. The inference code is from ByteTrack. The joint-training code is modified from CenterTrack and CenterNet, where the instance segmentation code is from CenterNet-CondInst. Thanks for their wonderful and pioneering works !
If you use DanceTrack in your research or wish to refer to the baseline results published here, please use the following BibTeX entry:
@article{peize2021dance,
title = {DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion},
author = {Peize Sun and Jinkun Cao and Yi Jiang and Zehuan Yuan and Song Bai and Kris Kitani and Ping Luo},
journal = {arXiv preprint arXiv:2111.14690},
year = {2021}
}