Описание задания 2 - в конце readme.
После загрузки репозитория на локальный диск первым делом необходимо установить все требуемые пакеты. Для этого:
- открыть консоль в папке со скриптом
- ввести команду:
pip install -r requirements.txt
Для работы скрипта необходимо настроить такие вещи, как api_key, secret_key, а также конфигурацию подключения к БД Postgres. Откройте config.py и введите соответсвующие ключи:

Note! Лучшей практикой является хранение секретных ключей в переменных окружения.
В тестовом задании я использовал следующую модель БД:
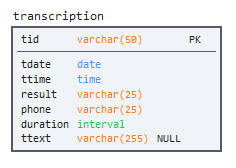
Сниппет sql-кода для ее создания лежит тут
Далее, необходимо сконфигурировать подключение к БД. Для этого в dbwork вписываем соответсвующие параметры:
Скрипт готов к работе!
Для вызова справки по скрипту необходимо вызвать следующую команду:
python transcriptor.py --help
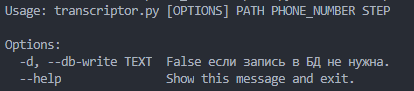
Единственный опциональный параметр - запись в бд (True по умолчанию; -d False чтобы отключить).
Использование скрипта выглядит следующим образом:
transcriptor.py [OPTIONS] PATH PHONE_NUMBER STEP
- PATH - путь до wav-файла.
- PHONE_NUMBER - телефонный номер.
- STEP - этап. Принимает два значения: 1 - распознования автоответчика; 2 - распознование положительной/отрицательной реакции.
Примеры:


У стандартной библиотеки Python для логирования logging есть ряд проблем - логи разных уровней (ERROR, INFO, WARNING, etc.) записываются в один файл, нет возможности выбрать кодировку записи. Поэтому в дополнение к ней был решено использовать библиотеку loguru. С помощью нее ведется лог ошибок скрипта. Лог с информацией (script.log) выглядит следующим образом:
28-Aug-20 15:25:19 - 89851c52-e929-11ea-8992-d43d7e49fa06 - АО - 88005553535 - 5.700s - вас приветствует автоответчик оставьте сообщение после сигнала
В логе ошибок (error.log) предоставляется детальная информация об ошибке (от интерпритатора Python).
А вот так результат выполнения скрипта выглядит в БД:

Хоть это работает, но это далеко не лучшая практика! В моей реализации проверка текста на ключевые фразы работает с помощью спискового включения. В серьезных проектах для этого используется векторная модель. Слова представляются в виде векторов, схожие слова имеют близкие координаты. С помощью, например, коэфициента Отиаи находятся близкие по значению распознанные слова. И не придется составлять список с положительными/отрицательными реакциями. Буду рад поработать над подобными задачами!
Единственная явно обрабатываемая ошибка в данном скрипте - отсутствующий файл. Если Вы пытаетесь обработать оный, скрипт предупредит Вас. Но что если Вы вводите номер несуществующей страны? Или аномально длинный телефонный номер? Скрипт продолжит свое исполнение. Поэтому будет разумно в серьезном коде добавить валидацию вводимых данных на тех же регулярных выражениях.
В тестовых аудио для данного задания были аудиозаписи с довольно низким количеством Hz. В настройках скрипта было достаточно выставить 8000Hz для отличного распознования. Естественно я попробовал записать свои аудио и распознать их. И естественно распознавание на 8000Hz не вышло. Как только была выставлена частота 96000Hz, мои аудио стали распознаваться, а тестовые аудио - нет. Из этого можно сделать вывод: хорошей практикой будут попытки распознования одной аудиозаписи разными кодеками(?). Наверно, в продакшен-коде так оно и есть.
В скрипте есть взаимозаменяемые этапы - Этап 1 и Этап 2. Я задал их выполнение явно с помощью условий, что не является хорошей практикой. Для данной задачи отлично подойдет поведенческий паттерн Стратегия.
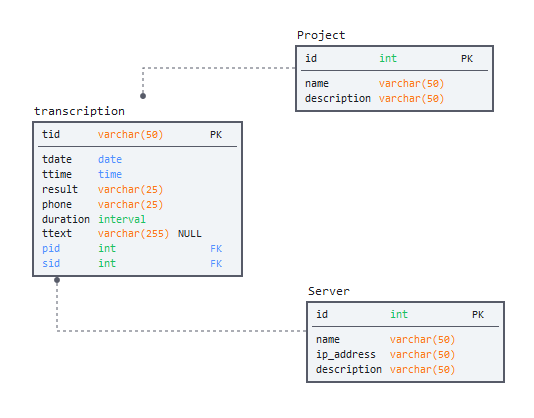
SQL-запрос для задания 2 лежит тут В верхней части файла - сам запрос. В нижней - сниппет схемы БД, на которой проводились тесты. Визуально она выглядит следующим образом:
Результаты выполнения запроса:

Запрос выводит дату распознавания, ее результат, затем общее количество схожих результатов в одном проекте и на одном сервере, общую их длительность, затем имя проекта и имя сервера.