This repository helps us to capture retail sales events and provide us forecasted sales. Classical ML algorithms such as xgboost regression is utilized to predict these demand nos. There are methodologies which plays vital roles in generating these models such as product category level seasonality, cannibalistic price ratios and lags at product category level, trend featrues, etc.
- General Information
- Project Flow
- Technologies Used
- Features
- Setup
- Dataset Utilized
- Usage
- Project Status
- Room for Improvement
- References
- Contact
- The aim of this repository is to implement a ML Retail Sales Pipeline which covers vital pointers to capture trends, seasonality, pricing ratios, pricing lags, etc in sales data by incorporating Feature Engineering script, Training Script and Inferencing Script.
- This work will help Data Science professionals gather knowledge on capturing retail based events and provide an idea on to how you can approach any ML based approach for capturing business insights from retail point of sales (POS) data.
- The code based could be further improved to feature engineer other interaction level features so as to capture excise duty changes, weather information, customer profiling data (geographics, professional details, demographics, etc), product distribution data.
It is the process of predicting what the demand for certain products will be in the future. This helps manufacturers to decide what they should produce and guides retailers toward what they should stock for days to come.
It focussess mainly on following processes:
- Supplier relationship management
- Customer relatonship management
- Order fulfillment and logistics
- Marketing campaigns
- Manufacturing flow management

There are quantitative and qualitative demand assessment methods. The above-listed traditional sales forecasting methods have been tried and tested for decades. With Artificial Intelligence development, they are now upgraded by modern forecasting methods using Machine Learning (ML).
Machine learning techniques allows for predicting the amount of products/services to be purchased during a defined future period. In this case, a software system can learn from data for improved analysis. Compared to traditional demand forecasting methods, a machine learning approach allows you to:
- Accelerate data processing speed
- Provide a more accurate forecast
- Automate forecast updates based on the recent data
- Analyze more data
- Identify hidden patterns in data
- Create a robust system
- Increase adaptability to changes
 The most unique section of this repository is how the feature engineering and traning scripts have been bifurcated to 2 separate versions -
The most unique section of this repository is how the feature engineering and traning scripts have been bifurcated to 2 separate versions -
a. The first version feature engineering script and training script are developed in such a way that at the end we have only one model for the entire data and the training data is very extensive in nature.
b. The second version feature engineering script and training script are developed in such a way so as to generate separate models for each product category (Accessories, Gaming Consoles, Books, etc). This seems to be a much more practical approach and a real time one.
The EDA remains same for both approaches however pre-processing, feature engineering and training methods are completely different.
-
EDA:
EDA covered certain sections such as:
a. Data Sourcing
b. Data Cleaning - (Handling Missing Values, Handling Duplicated Values, Handling outliers)
c. Univariate Analysis
d. Bivariate Analysis
e. Multivariate Analysis -
Pre-Processing (Approach 1):
Following steps are being followed for preprocessing the sales data before feature enginnering part is run:
a. Based on unique dates (date_block_num), grid is formed among unique shop ids and item ids.
b. Sales are brought from daily level to montly level aggregation where item count is "summed" and price of an item is "averaged" out.
c. Dataframes obtained from step (a) & (b) are merged together and wherever item count per month is 'NA', they are filled up with 0.
d. item categories are also added to dataframe from step (c). -
Feature Engineering (Approach 1):
9 feature engineering steps are compiled together to generate the train ready dataset and if they are used or not: a. Adding previous item sold for each shop as feature starting from month 1 to month 12. - Groupby (date_block_num) - ✅
b. Adding previous sales for each item as feature starting from month 1 to month 12. - Groupby (date_block_num & item_id) - ✅
c. Adding previous shop for each item price as feature starting from month 1 to month 12. - Groupby (shop_id & item_id & date_block_num) - ✅
d. Adding previous item price as feature starting from month 1 to month 12. - Groupby (item_id & date_block_num) - ✅
e. Mean encodings for shop per item pairs / Mean item counts are extracted for shop item pairs wrt week 32 and 33. - Groupby (shop_id & item_id) - ✅
f. Mean encodings for item pairs / Mean item counts are extracted wrt week 32 and 33. - Groupby (item_id) - ✅
g. Month number from last sale of each shop item pair. - 🔶
h. Month number from last sale of each item. - 🔶
i. Utilize top 25 features based on item name. - ✅ -
Pre-Processing (Approach 2):
Following steps are being followed for preprocessing the sales data before feature engineering part is run:
a. Sales are brought from daily level to week level aggregation where item count is "summed" and price of an item is "averaged" out.
b. For dataframes obtained from step (a), wherever item count per month is 'NA', they are filled up with 0.
c. Certain categories are removed from the sales data if number of datapoints are less than 10 in number.
d. Parent Categories are extracted for each data point. -
Feature Engineering (Approach 2):
7 feature engineering steps are compiled together for each parent category to generate the train ready dataset and if they are used or not:
a. Adding shop level feature, extracting total no of items sold from each shop for each category. - Groupby (shop_id & item_category_id & week_start_date) - ✅
b. Adding shop level feature, extracting mean price of each category sold from each shop. - Groupby (shop_id & item_category_id & week_start_date) - ✅
c. Adding price lags, extracting price lags for 1, 4, 12 and 24 weeks for each item. - Groupby (item_id & week_start_date) - ✅
d. Adding price lags, extracting price lags for 1, 4, 12 and 24 weeks for each item sold from each shop. - Groupby (shop_id & item_id & week_start_date) - ✅
e. Adding seasonality index for each category at monthly level - ✅
f. Adding parent category level price ratios at weekly level - ✅
g. Adding item category level price ratios at weekly level - ✅
- XGBoost
- Python
List the ready features here:
- Exploratory Data Analysis (EDA) Script - Done
- Feature Engineering Script - Done
- Modelling Script - Done
- Inferencing Script - To Be Started
- git clone https://github.com/ManashJKonwar/ML-Retail-Sales.git (Clone the repository)
- python3 -m venv MLPricingVenv (Create virtual environment from existing python3)
- activate the "MLPricingVenv" (Activating the virtual environment)
- pip install -r requirements.txt (Install all required python modules)
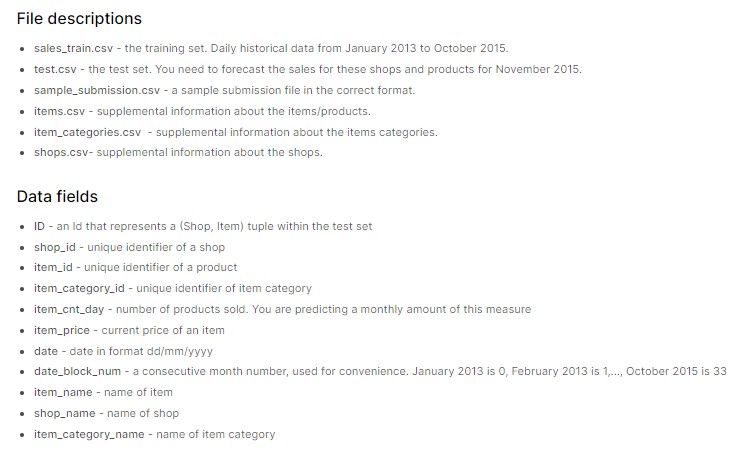
- Retail Dataset is obtained from Kaggle and competition name is Predict Future Sales.
- Please refer to screenshot below for dataset descriptions and data fields within this dataset.

- python preprocessing_pipeline\eda.ipynb
- python modelling_pipeline\feature_engg_script_v01.ipynb (For Methodology 1)
- python modelling_pipeline\feature_engg_script_v02.ipynb (For Methodology 2)
- python modelling_pipeline\training_script_v01.ipynb (For Methodology 1)
- python modelling_pipeline\training_script_v02.ipynb (For Methodology 2)
Project is: _in progress
Room for improvement:
- Generate sku level lag features
- Generate sku level price ratios
- Build feature selection methodology
- Build model selection methodology
To do:
- Finish developing inferencing scripts/notebooks for both methodologies
[1] https://mobidev.biz/blog/machine-learning-methods-demand-forecasting-retail
Created by @ManashJKonwar - feel free to contact me!