This repo is the implementation of the following paper:
Augmenting Reinforcement Learning with Transformer-based Scene Representation Learning for Decision-making of Autonomous Driving
Haochen Liu, Zhiyu Huang, Xiaoyu Mo, Chen Lv
AutoMan Research Lab, Nanyang Technological University
[Paper] [arXiv] [Project Website]
- CARLA Environment is now available;
- Model Framework Overview:
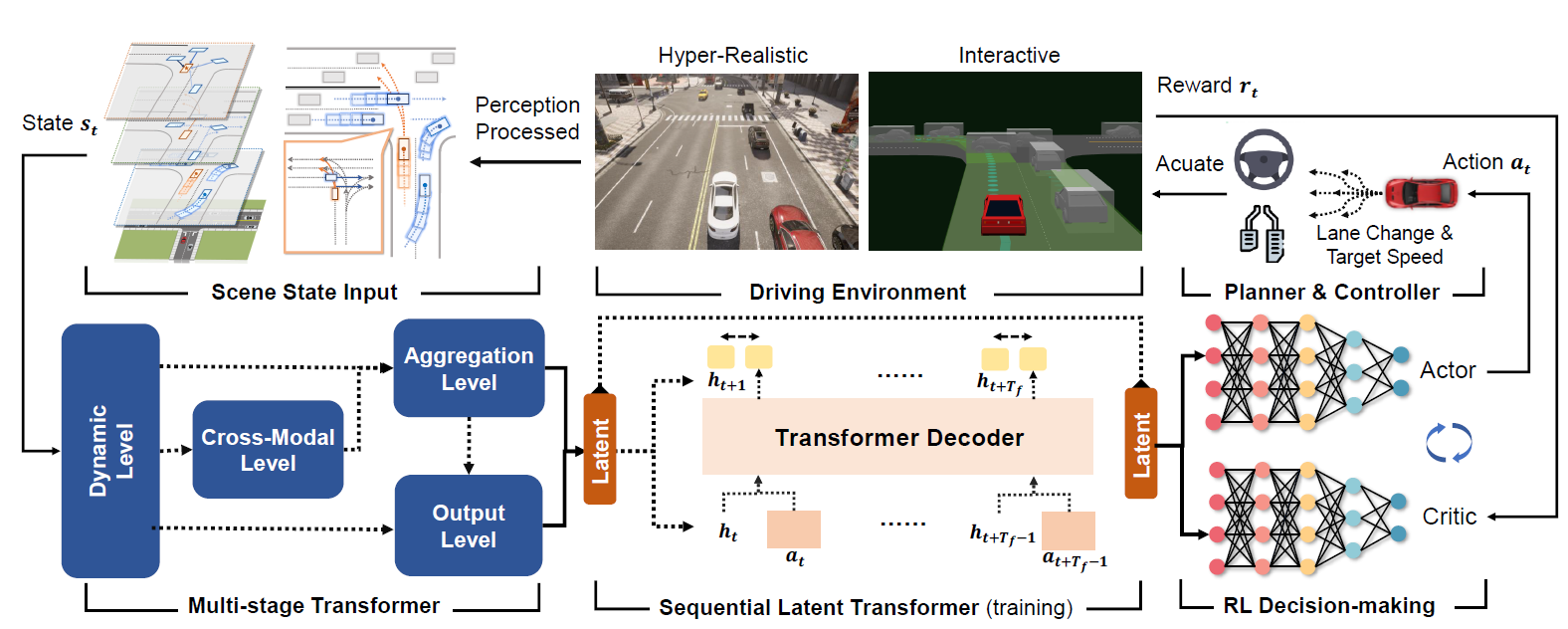

- Clone this repository and navigate to the directory:
https://github.com/georgeliu233/Scene-Rep-Transformer.git && cd Scene-Rep-Transformer
- Download required packages:
pip install -r requirements.txt
[NOTE] The requirements lists all the required packages, so you may try to build the simulator first in the case of compatible issues on your devises.
We keep the independent code strcutures for CARLA and SMARTS, so that you can also choose either of one to install and run:
-
Download all sources of CARLA
v0.9.13via this link -
Navigate to
envs/carla/carla_env.py, add folder path of the installed CARLA in system PATH in line 18-19:
# append sys PATH for CARLA simulator
# assume xxx is your path to carla
sys.path.append('xxx/CARLA_0.9.13/PythonAPI/carla/dist/carla-0.9.13-py3.7-linux-x86_64.egg')
sys.path.append('xxx/CARLA_0.9.13/PythonAPI/carla/')
-
Download & build SMARTS according to its repository
-
[NOTE] The current scenarios are built upon SMARTS
v0.4.18, so you may build from source. Ensure that SMARTS is successfully built. -
Download SMARTS Scenarios:
wget https://github.com/georgeliu233/Scene-Rep-Transformer/releases/download/v1.0.0/smarts_scenarios.tar.gz
- We offered the checkpoints with
train_logsfor all scenarios:
wget https://github.com/georgeliu233/Scene-Rep-Transformer/releases/download/v1.0.0/data.tar.gz
- unzip the ckpts and scenarios:
bash ./tools/download_build.sh
- run the scenario test by following example commands:
cd tools
python3 test.py \
--scenario=left_turn # testing scenarios: [left_turn, cross, carla, ..., etc.]
--algo=scene_rep # proposed methods
More testing results in [Project Website]
We adopt two extra reward functions for comprehensive testing:
| Scenario | Left turn | Double Merge | CARLA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | Succ. | Col. | Step(s) | Succ. | Col. | Step(s) | Succ. | Col. | Step(s) |
| PPO-R1 | 0.48 | 0.38 | 20.4 | 0.38 | 0.62 | 33.7 | 0.44 | 0.20 | 22.1 |
| DrQ-R1 | 0.70 | 0.30 | 27.3 | 0.66 | 0.14 | 38.3 | 0.74 | 0.24 | 17.6 |
| Ours-R1 | 0.90 | 0.10 | 11.7 | 0.84 | 0.16 | 21.2 | 0.76 | 0.22 | 19.4 |
| PPO-R2 | 0.38 | 0.62 | 31.2 | 0.46 | 0.54 | 34.7 | 0.50 | 0.20 | 24.8 |
| DrQ-R2 | 0.82 | 0.08 | 13.9 | 0.72 | 0.28 | 18.7 | 0.78 | 0.12 | 18.5 |
| Ours-R2 | 0.94 | 0.04 | 11.6 | 0.88 | 0.10 | 27.7 | 0.78 | 0.16 | 21.3 |
RL implementations are based on tf2rl
Official release for the strong baselines: DrQ; Decision-Transformer