- 1. Building Blocks
- 2. Setup External Services
- 3. Install & Usage
- 4. Video lectures
- 5. License
- 6. Contributors & Teachers
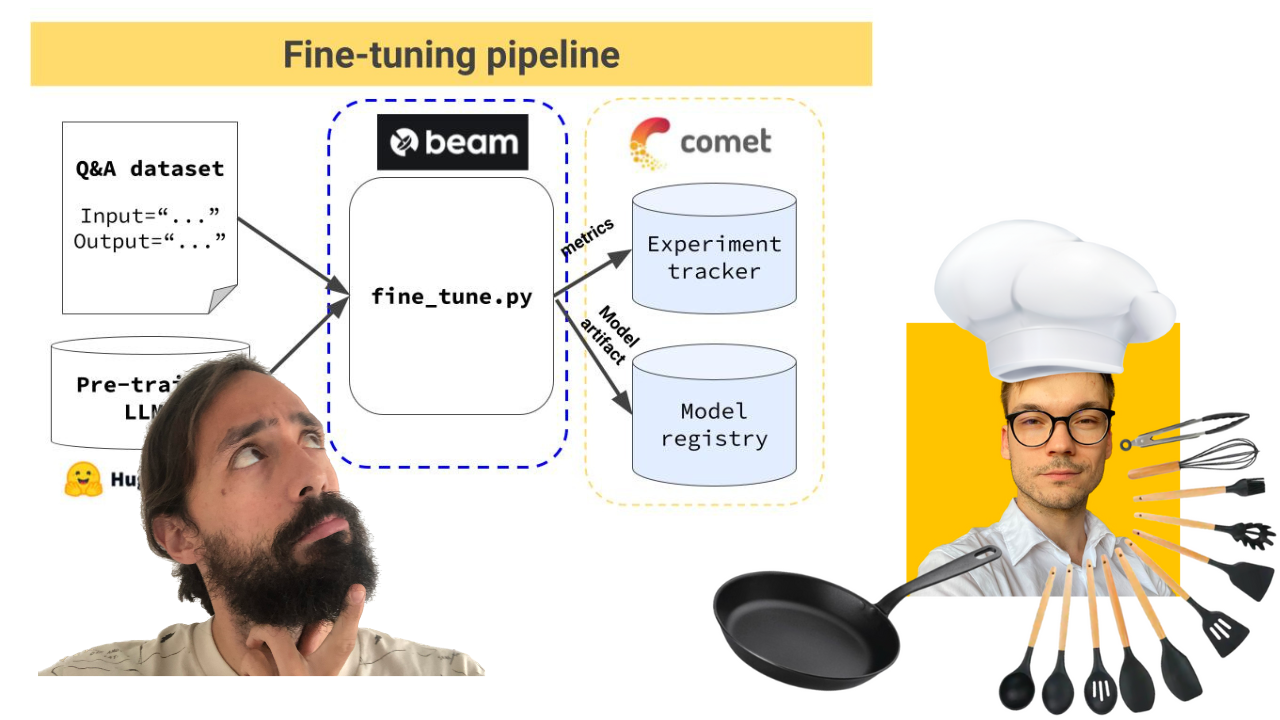
Training pipeline that:
- loads a proprietary Q&A dataset
- fine-tunes an open-source LLM using QLoRA
- logs the training experiments on Comet ML's experiment tracker & the inference results on Comet ML's LLMOps dashboard
- stores the best model on Comet ML's model registry
The training pipeline is deployed using Beam as a serverless GPU infrastructure.
-> Found under the modules/training_pipeline directory.
Real-time feature pipeline that:
- ingests financial news from Alpaca
- cleans & transforms the news documents into embeddings in real-time using Bytewax
- stores the embeddings into the Qdrant Vector DB
The streaming pipeline is automatically deployed on an AWS EC2 machine using a CI/CD pipeline built in GitHub actions.
-> Found under the modules/streaming_pipeline directory.
Inference pipeline that uses LangChain to create a chain that:
- downloads the fine-tuned model from Comet's model registry
- takes user questions as input
- queries the Qdrant Vector DB and enhances the prompt with related financial news
- calls the fine-tuned LLM for financial advice using the initial query, the context from the vector DB, and the chat history
- persists the chat history into memory
- logs the prompt & answer into Comet ML's LLMOps monitoring feature
The inference pipeline is deployed using Beam as a serverless GPU infrastructure, as a RESTful API. Also, it is wrapped under a UI for demo purposes, implemented in Gradio.
-> Found under the modules/financial_bot directory.

Before diving into the modules, you have to set up a couple of additional external tools for the course.
NOTE: You can set them up as you go for every module, as we will point you in every module what you need.
financial news data source
Follow this document to show you how to create a FREE account and generate the API Keys you will need within this course.
Note: 1x Alpaca data connection is FREE.
serverless vector DB
Go to Qdrant and create a FREE account.
After, follow this document on how to generate the API Keys you will need within this course.
Note: We will use only Qdrant's freemium plan.
serverless ML platform
Go to Comet ML and create a FREE account.
After, follow this guide to generate an API KEY and a new project, which you will need within the course.
Note: We will use only Comet ML's freemium plan.
serverless GPU compute | training & inference pipelines
Go to Beam and create a FREE account.
After, you must follow their installation guide to install their CLI & configure it with your Beam credentials.
To read more about Beam, here is an introduction guide.
Note: You have ~10 free compute hours. Afterward, you pay only for what you use. If you have an Nvidia GPU >8 GB VRAM & don't want to deploy the training & inference pipelines, using Beam is optional.
When using Poetry, we had issues locating the Beam CLI inside a Poetry virtual environment. To fix this, after installing Beam, we create a symlink that points to Poetry's binaries, as follows:
export COURSE_MODULE_PATH=<your-course-module-path> # e.g., modules/training_pipeline
cd $COURSE_MODULE_PATH
export POETRY_ENV_PATH=$(dirname $(dirname $(poetry run which python)))
ln -s /usr/local/bin/beam ${POETRY_ENV_PATH}/bin/beamcloud compute | feature pipeline
Go to AWS, create an account, and generate a pair of credentials.
After, download and install their AWS CLI v2.11.22 and configure it with your credentials.
Note: You will pay only for what you use. You will deploy only a t2.small EC2 VM, which is only ~$0.023 / hour. If you don't want to deploy the feature pipeline, using AWS is optional.
Every module has its dependencies and scripts. In a production setup, every module would have its repository, but in this use case, for learning purposes, we put everything in one place:
Thus, check out the README for every module individually to see how to install & use it:


This course is an open-source project released under the MIT license. Thus, as long you distribute our LICENSE and acknowledge our work, you can safely clone or fork this project and use it as a source of inspiration for whatever you want (e.g., university projects, college degree projects, etc.).
 |
Pau Labarta Bajo | Senior ML & MLOps Engineer Main teacher. The guy from the video lessons. Twitter/X Youtube Real-World ML Newsletter Real-World ML Site |
 |
Alexandru Razvant | Senior ML Engineer Second chef. The engineer behind the scenes. Neura Leaps |
 |
Paul Iusztin | Senior ML & MLOps Engineer Main chef. The guys who randomly pop in the video lessons. Twitter/X Decoding ML Newsletter Personal Site | ML & MLOps Hub |