基于SiFive Inclusive Cache的硬件数据预取综合研究
- 阅读Chipyard源码,写了Chipyard代码导读
- 阅读约100篇硬件数据预取相关论文,写了硬件数据预取论文阅读
- 在SiFive Inclusive Cache上实现了通用的预取框架,并且提供可以运行时配置的MMIO接口和性能计数器
- 正确实现了3个经典的预取器:Next-Line,BOP,SPP
- 使用SPEC2006进行性能评测,并分析了预取的准确率、覆盖率、及时性等指标
- 本项目需要Chipyard版本为
1.5.0的Docker镜像,您可以在进入Chipyard容器后运行如下命令确认Chipyard的版本$ cd /root/chipyard $ git describe --tags # 1.5.0
由于FPGA的核心频率较低(50MHz),甚至低于DDR3内存(800MHz),导致访存周期数偏小,与真实处理器不符;为此我写了一个位于System Bus和L2 Cache之间的小模块,通过一个大小为8的buffer和一个宽度为100的shift register高效地实现了100个周期的延迟。
- 见
Makefile,把BankedL2Params.scala映射到Chipyard镜像的/root/chipyard/generators/rocket-chip/src/main/scala/subsystem/BankedL2Params.scala - 不需要改其他地方,然后
make就可以了
- 先把整个仓库完整clone下来
$ cd l2proj $ git submodule update --init --recursive - 见
Makefile,把sifive-cache/design映射到Chipyard镜像的/root/chipyard/generators/sifive-cache/design - 不需要改其他地方,然后
make就可以了
我提供了一些简单的C程序(均以_bm.c结尾),用于测试Next-Line、BOP和SPP预取器以及L2性能计数器的API。
- 编译,需进入Chipyard容器
$ BM=/root/chipyard/software/coremark/riscv-coremark/riscv64-baremetal $ CFLAGS="-Os -mcmodel=medany -nostdlib -nostartfiles -T$BM/link.ld $BM/syscalls.c $BM/crt.S" $ riscv64-unknown-elf-gcc $CFLAGS -o test_seq_bm test_seq_bm.c $ riscv64-unknown-elf-gcc $CFLAGS -o test_step_bm test_step_bm.c $ riscv64-unknown-elf-gcc $CFLAGS -o perm_step_bm perm_step_bm.c $ riscv64-unknown-elf-gcc $CFLAGS -o test_matmul_bm test_matmul_bm.c
- 运行,需退出容器
$ build/simulator-chipyard-MediumBoomConfig hwd-prefetch-study/example/test_seq_bm # cycle: 124898 # train : 176 # trainHit : 1 # trainMiss: 174 # trainLate: 0 # pred : 0 # predGrant: 0 $ build/simulator-chipyard-MediumBoomConfig hwd-prefetch-study/example/test_step_bm # begin # ------------------- # dummy work (best) : 44228 # no prefetch (worst): 140663 # hand prefetch +0 : 148231 # hand prefetch +1 : 104518 # hand prefetch +2 : 103848 # ... $ build/simulator-chipyard-MediumBoomConfig hwd-prefetch-study/example/perm_step_bm # begin # -------------------- # prefetch.sel: 0 # cycle: 103220 # trains : 415 # trainHit : 12 # trainMiss: 402 # ... $ build/simulator-chipyard-MediumBoomConfig hwd-prefetch-study/example/test_matmul_bm # begin # cycle: 1821076 # trains : 18249 # trainHit : 17477 # trainMiss: 185 # trainLate: 101 # preds : 6047 # predGrant: 584
我提供了一个简单的随机访存的C程序,用于探究数组大小与平均访存延迟的关系;它会输出数组大小和总访存周期,你可以用Python脚本分析结果。
- 编译
$ riscv64-unknown-linux-gnu-gcc -Os -o test_latency example/test_latency.c
- 在FGPA上运行
$ ./test_latency # begin # {"loop":625000,"n":1024,"cycle":35176796} # {"loop":500000,"n":1280,"cycle":53220544} # {"loop":416666,"n":1536,"cycle":35102682} # ...
我的预取器提供了直接内存控制(MMIO)接口,即可以通过修改某处物理内存的内容来选择预取器和设置参数。我提供了一个使用这个接口的C程序,它通过映射操作系统的/dev/mem文件访问物理内存,因此需要root权限。
- 编译
$ riscv64-unknown-linux-gnu-gcc -Os -o l2ctl example/l2ctl.c
- 在FGPA上运行,请使用root或sudo
$ l2ctl on # 开启L2预取 # prefetch on $ l2ctl off # 关闭L2预取 # prefetch off $ l2ctl config # 查看L2配置 # banks : 1 # ways : 8 # sets : 1024 # blockBytes: 64 $ l2ctl status # 查看L2预取性能性能计数器 # prefetch : off # trains : 1823464953 # trainHits : 468795141 # preds : 1148053842 # predGrants: 743084171
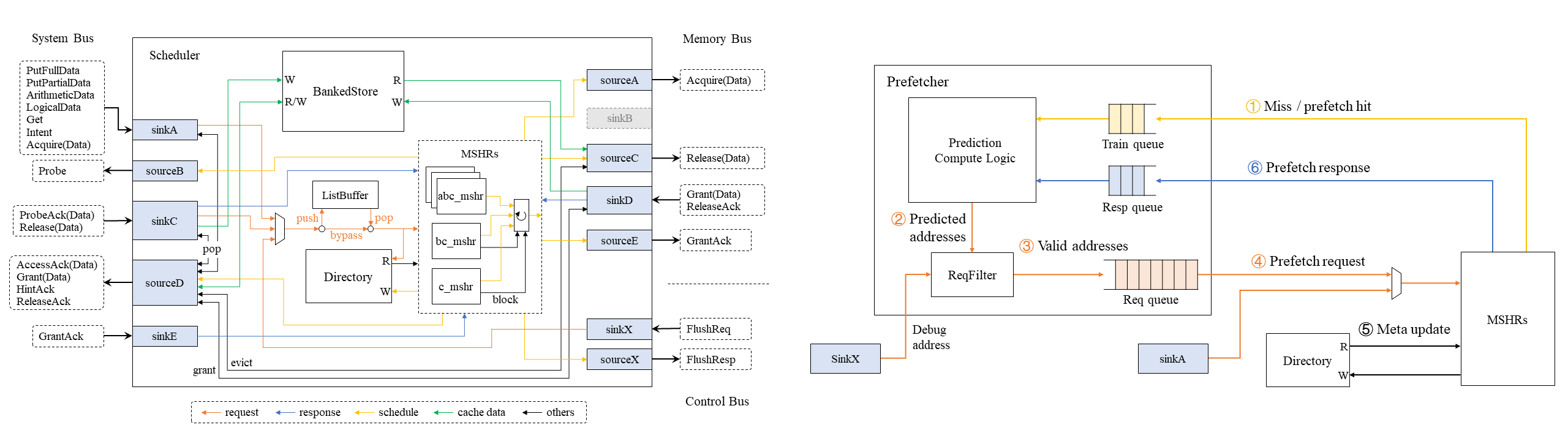
此处为缩略图,详见Chipyard代码导读第7.3节
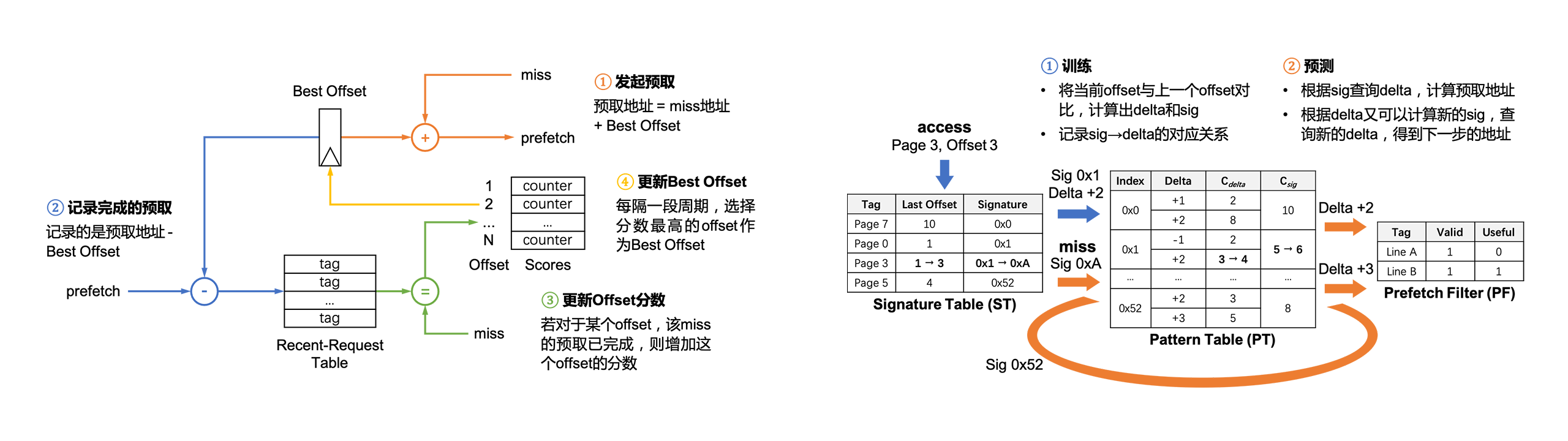
此处为缩略图,详见2022年秋季学期工作进展-硬件数据预取第3章
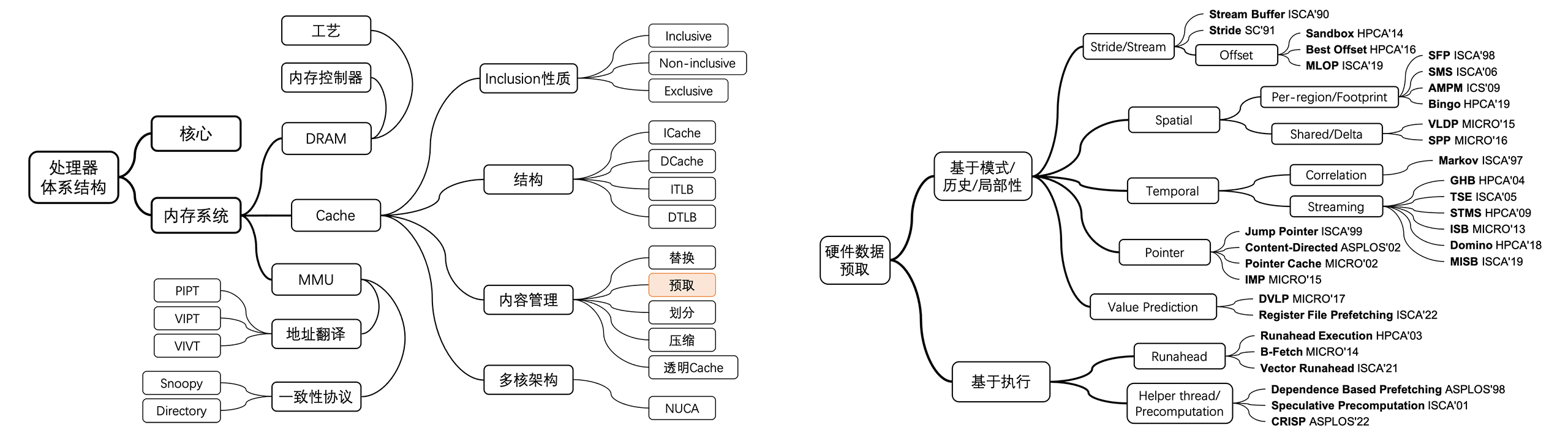
此处为缩略图,详见硬件数据预取论文阅读




- 预取可以真实提升处理器的性能
- 对访存序列的有效建模是取得良好结果的前提
- 所谓建模,就是对访存序列的潜在规律的认识
- BOP和SPP的建模更加合理和周全,故效果比朴素的Next-Line好
- 现有预取器在Coverage上还有很大提高空间
- 3个预取器的Coverage都是50%左右,即还有一半的miss没有被覆盖
- 虽说Accuracy和Timeliness也很重要,但是Coverage是可预测性的关键