- Introduction
- Citing
- Getting Started
- VGGSound Recipe
- AudioSet Recipe
- Audio-Visual Embedding Analysis (Figure 3 of the UAVM Paper)
- Audio-Visual Retrieval Experiments (Figure 4 of the UAVM paper)
- Attention Map Analysis (Figure 5 of the UAVM Paper)
- Pretrained Models
- Contact
This paper will be presented as an oral paper at the ICASSP Audio for Multimedia and Multimodal Processing Session at 6/6/2023 10:50:00 (Eastern European Summer Time).
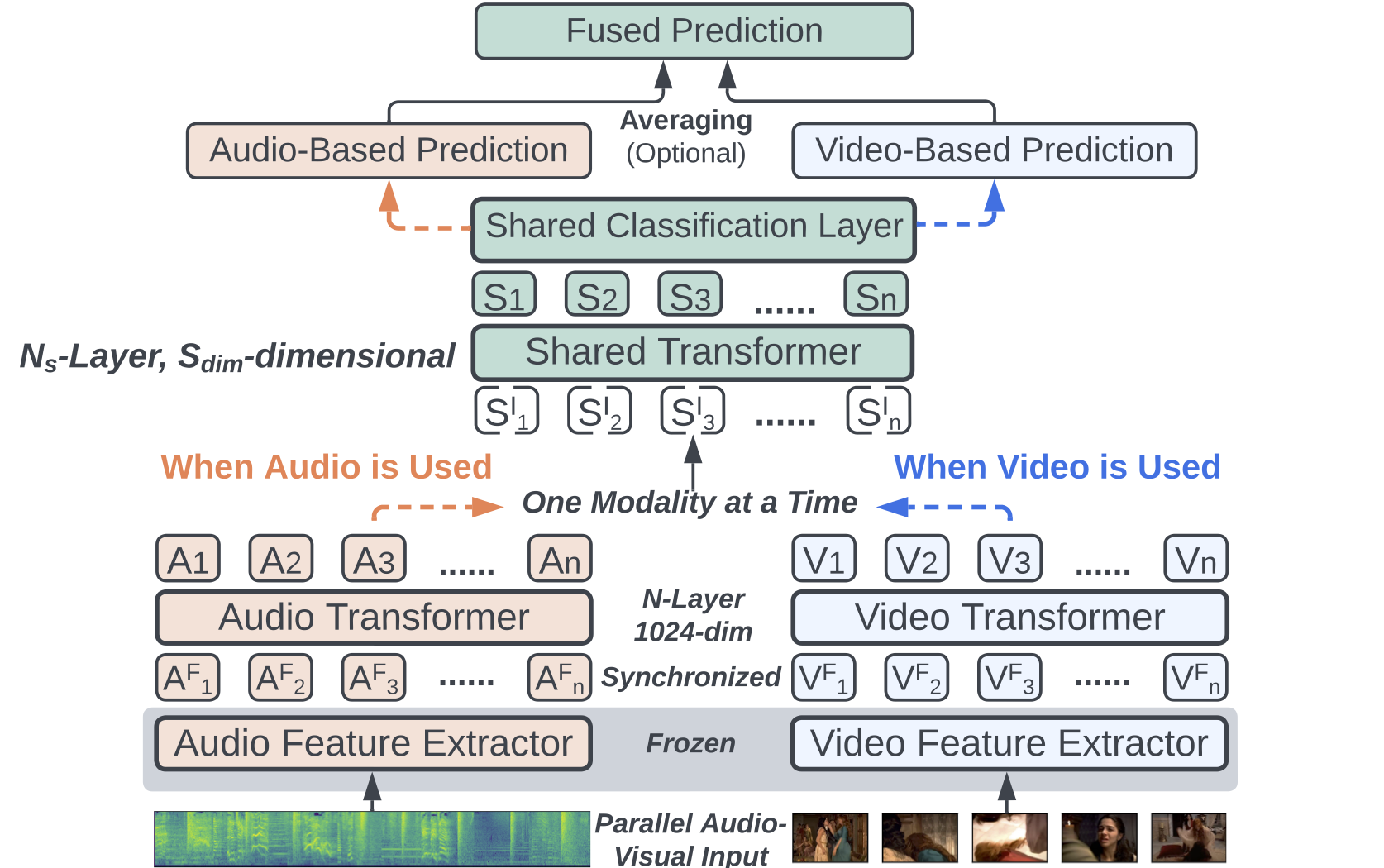
This repository contains the official implementation (in PyTorch) of the models and experiments proposed in the IEEE Signal Processing 2022 paper UAVM: Towards Unifying Audio and Visual Models (Yuan Gong, Alexander H. Liu, Andrew Rouditchenko, James Glass; MIT CSAIL). [IEEE Xplore] [arxiv]
Conventional audio-visual models have independent audio and video branches. In this work, we unify the audio and visual branches by designing a Unified Audio-Visual Model (UAVM). The UAVM achieves a new state-of-the-art audio-visual event classification accuracy of 65.8% on VGGSound. More interestingly, we also find a few intriguing properties of UAVM that the modality-independent counterparts do not have.
Performance-wise, our model and training pipeline achieves good results (SOTA on VGGSound):
To help better understand the pros and cons of this work, we have attached the anonymous reviews and our responses here. We thank the associate editor and anonymous reviewers' invaluable comments.
Please cite our paper if you find this repository useful.
@ARTICLE{uavm_gong,
author={Gong, Yuan and Liu, Alexander H. and Rouditchenko, Andrew and Glass, James},
journal={IEEE Signal Processing Letters},
title={UAVM: Towards Unifying Audio and Visual Models},
year={2022},
volume={29},
pages={2437-2441},
doi={10.1109/LSP.2022.3224688}}
Clone or download this repository and set it as the working directory, create a virtual environment and install the dependencies.
cd uavm/
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt
- The UAVM model, modality-independent model, and cross-modality attention model scripts are in
src/models/mm_trans.py(UnifiedTrans,SeperateTrans, andFullAttTrans). - The training and test scripts are in
src/run.pyandsrc/traintest.py. - The ConvNext audio feature extractor model script is in
src/models/convnext.py. - The ConvNext audio feature extractor model training scripts are in
src/run_feat.pyandsrc/traintest_feat.py. - Audio and visual feature extraction scripts are in
src/gen_audio_feat/andsrc/gen_video_feat/, respectively. - The VGGSound recipe is in
egs/vggsound. - The AudioSet recipe is in
egs/audioset. - The probing test and plot scripts for UAVM paper figure 3, 4, and 5 are in
src/{embedding, retrieval, attention_diff}, respectively.
This part of code is in egs/vggsound/.
We recommend to start with one_click_recipe.sh that loads our pretrained features, do all preprocessing, and train the UAVM model first. It should report a SOTA accuracy on VGGSound.
Alternatively, you can also start from scratch. We provide everything you would need to do so. Note: You can skip step 0-4 and directly go to step 5 if you don't want to download the dataset by yourself and train your own feature extractor.
- Download the VGGSound dataset, create json datafiles to include the wav path, see samples at [here], generate sample weight file using
./datafile/gen_weight_file. - Train an audio feature extractor with the VGGSound audio data using
run_feat_extractor.sh, which will callsrc/run_feat.py, which will callsrc/traintest_feat.py. (You can skip this step by using our pretrained feature extractor from [this link]). - Generate audio features and save them on disk using
src/gen_audio_feat/gen_audio_feature.py. (You can skip step 1&2 by using our pretrained audio features from [this link]). - Generate visual features and save them on disk using scripts in
src/gen_video_feat. (You can skip this step by using our pretrained visual features from [this link]). - Create json datafiles to include the path of audio/visual feature path and label information, see samples at [here], generate sample weight file using
./datafile/gen_weight_file. - Train the uavm, cross-modality attention model, and modality-independent model using
run_uavm.sh,run_fullatt_trans.sh, andrun_ind_trans.sh, respectively.
This part of code is in egs/audioset/.
The AudioSet recipe is almost identical with the VGGSound recipe, expect that we cannot provide pretrained features.
- Download the AudioSet dataset, create json datafiles to include the wav path, see samples at [here], generate sample weight file using
./datafile/gen_weight_file. - Train an audio feature extractor with the AudioSet audio data using
run_feat_extractor.sh, which will callsrc/run_feat.py, which will callsrc/traintest_feat.py. (You can skip step 1&2 by using our pretrained audio feature extractor [here]) - Generate audio features and save them on disk using
src/gen_audio_feat/gen_audio_feature.py. (For full AudioSet-2M, this process needs to be parallelized so that it can be finished in reasonable time). - Generate visual features and save them on disk using scripts in
src/gen_video_feat. (For full AudioSet-2M, this process needs to be parallelized so that it can be finished in reasonable time). - Create json datafiles to include the path of audio/visual feature path and label information, see samples at [here], generate sample weight file using
./datafile/gen_weight_file. - Train the uavm, cross-modality attention model, and modality-independent model using
run_uavm.sh,run_fullatt_trans.sh, andrun_ind_trans.sh, respectively.
This part of code is in src/embedding/.
This is to reproduce Figure 3 of the UAVM Paper which analyzes the embedding of the unified models.
- Generate the intermediate representations of a model using
gen_intermediate_representation.py(this script does more than that, but you can ignore other functions, we have also released these intermediate representations if you don't want to do yourself, please see below). - Build a modality classifier and record the results using
check_modality_classification_summary.py, which will generate amodality_cla_summary_65_all.csv(65is just internal experiment id, you can ignore it, we have include this file in the repo). - Plot the modality classification results using
plt_figure_2_abc.py(Figure 2 (a), (b), and (c) of the UAVM paper). - Plot the t-SNE results using
plt_figure_2_d.py(Figure 2 (d) of the UAVM paper).
Note: you can of course train your own model using our provide scripts and do analysis based on the models. But for the purpose of easier reproduction and analysis without re-training the models, we also release all models and corresponding intermediate representations of the models [here], it is very large at around 30GB.
This part of code is in src/retrieval/.
1.Generate the retrieval performance results R@5 and R@10 using gen_rep_vggsound_retrieval2_r5_summary.py and gen_rep_vggsound_retrieval2_r10_summary.py, which will generate output retrieval_summary_final_r5.csv and retrieval_summary_final_r10.csv respectively.
2.Plot the figure using plt_retrieval.py, which reads the result from retrieval_summary_final_r5.csv and retrieval_summary_final_r10.csv.
Note: You can download all pretrained models needed to reproduce this result at [here].
This part of code is in src/attention_diff/.
This is to show the interesting results of the audio/visual attention map and audio-visual attention difference (Figure 5 of the UAVM paper).
1.Generate the attention map of models using gen_att_map_vggsound_summary.py and gen_att_map_vggsound_full_att_summary.py for unified model and modality-independent model, and cross-modality attention model, respectively. gen_att_map_vggsound_summary.py also calculates the difference between audio and visual attention maps
2.Plot the attention maps of unified model, modality-independent model, and cross-modality attention model using plt_attmap_unified.py and plt_attmap_baseline.py.
Note: you can of course train your own model using our provide scripts and do analysis based on the models. But for the purpose of easier reproduction and analysis without re-training the models, we also release pretrained model and attention maps [here].
AudioSet-2M pretrained ConvNext-Base
VGGSound pretrained ConvNext-Base
We use torchvision official ImageNet pretrained ConvNext-Base as our visual feature extractor.
Cross-Modality Attention Model
Cross-Modality Attention Model
Audio Features (~20GB)
Video Features (~10GB)
If you have a question, please bring up an issue (preferred) or send me an email yuangong@mit.edu.