Table of Contents

Recent advancements in deep learning have led to the development of powerful language models (LMs) that excel in various tasks. Despite these achievements, there is still room for improvement, particularly in enhancing reasoning abilities and incorporating multimodal data. This report investigates the potential impact of combining Chain-of-Thought (CoT) reasoning and Visual Question Answering (VQA) techniques to improve LMs’ accuracy in solving multiple-choice questions. By employing TextVQA and ScienceQA datasets, we assessed the effectiveness of three text embedding methods and three visual embedding approaches. Our experiments aimed to fill the gap in current research by investigating the combined impact of CoT and VQA, contributing to the understanding of how these techniques can improve the reasoning capabilities of state-of-the-art models like GPT-4. Results from our experiments demonstrated the potential of these approaches in enhancing LMs’ reasoning and question-answering capabilities, providing insights for further research and development in the field, and paving the way for more accurate and reliable AI systems that can handle complex reasoning tasks across multiple modalities.\
The primary objective of this research is to explore the synergistic effects of CoT and VQA on LMs' performance. CoT involves generating rationales for each choice, providing a logical explanation for the model's decision-making process. VQA includes using images as additional information to answer questions. By combining these techniques, we aim to demonstrate substantial improvements in LMs' reasoning and question-answering capabilities.
To assess these techniques' effectiveness, we experimented with three text embedding methods and three visual embedding approaches. Current research primarily focuses on CoT and VQA individually. Our project aims to fill the gap by investigating the combined impact of CoT and VQA, contributing to the understanding of how these techniques can improve the reasoning capabilities of state-of-the-art models like GPT-4 [14] .
The datasets utilized in our experiments are TextVQA [19] and ScienceQA [17] . TextVQA consists of 45,336 questions based on 28,408 images from the Open Images dataset, requiring reasoning and reading about text in the image. ScienceQA contains 21,208 multimodal multiple-choice science questions collected from elementary and high school science curricula, covering a wide range of subjects and offering a rich diversity of domains.
By employing these datasets and combining CoT and VQA techniques, we strive to demonstrate the potential of these approaches in improving LMs' reasoning and question-answering capabilities. The successful integration of these techniques will contribute to the understanding of deep learning models' underlying mechanisms, ultimately leading to the development of more efficient and accurate LMs for a wide range of applications.
The primary objective of this project is to explore the synergistic effects of CoT and VQA on LMs' performance. CoT involves generating rationales for each choice, providing a logical explanation for the model's decision-making process [20] . VQA includes using images as additional information to answer questions [18] . By combining these techniques, we aim to demonstrate substantial improvements in LMs' reasoning and question-answering capabilities.
To assess these techniques' effectiveness, we experimented with three text embedding methods and three visual embedding approaches. Current research primarily focuses on CoT and VQA individually [20] [18] . Our project aims to fill the gap by investigating the combined impact of CoT and VQA, contributing to the understanding of how these techniques can improve the reasoning capabilities of state-of-the-art models like GPT-4 [21] .
The datasets utilized in our experiments are TextVQA and ScienceQA [19] [17] . TextVQA consists of 45,336 questions based on 28,408 images from the Open Images dataset, requiring reasoning and reading about text in the image [18] . ScienceQA contains 21,208 multimodal multiple-choice science questions collected from elementary and high school science curricula, covering a wide range of subjects and offering a rich diversity of domains [8]
We set up the following text embedding models for our experiments: 1) a simple QA model using DistilBERT as a baseline [15] ; 2) T5 with reasoning without image captions [9] }; and 3) T5 with reasoning and image captions [9] . For visual embedding models, we considered: 1) a baseline VQA model [11] ; 2) integrating visual embeddings with textual embeddings for the baseline textual model [13] ; and 3) visual embedding with textual embeddings for the T5 model [10] .
We thought this would be a fruitful approach since VQA and CoT individually already improved model performance substantially on similar benchmarks [20] [18] . Using VQA together with CoT is a new approach, which we aimed to explore in this study [21] .
Anticipated problems included limitations with computational resources, and we encountered some models returning surprisingly poor performance (RoBERTa) contrary to expectations [12] . The very first thing we tried did not work, but we iteratively refined our approach to address these issues.\
We did not use any code from repositories, but we used the following for reference:
- Document Question Answering [2]
- Question Answering With T5 [1]
- Towards Data Science: Adding Custom Layers on Top of a Hugging Face Model [16]
- Multiple choice [3]
By combining CoT and VQA techniques, we strive to demonstrate the potential of these approaches in enhancing the reasoning and question-answering capabilities of LMs. Our experiments may pave the way for further research and development in the field, leading to more accurate and reliable AI systems that can handle complex reasoning tasks across multiple modalities.
By integrating CoT and VQA, we hope to leverage the strengths of both approaches, enabling LMs to reason more systematically and accurately when provided with textual and visual information. This combined approach could be particularly useful for real-world applications where data comes in various forms and requires the integration of multiple sources of information for effective decision-making.
Moreover, our research could inspire future work on novel architectures and algorithms that capitalize on the synergies between CoT and VQA, pushing the boundaries of what is possible with current AI technology. Our findings may also contribute to the development of more interpretable models, as generating rationales for each choice can help explain the model's decision-making process, making it more transparent and understandable for human users.
To evaluate the success of our proposed approach, we conducted a series of experiments using various models and configurations. We then compared the results, both quantitatively and qualitatively, to assess the effectiveness of our approach in enhancing the reasoning and question-answering capabilities of LMs.
The memory and computational requirements needed for creating scalable VQA models constrained us with using models that use both image and text features for question answering. We tried a couple of multi-modal frameworks like ViLT [5] and VisualBERT [7] . We fine-tuned the ViLT model on the ScienceQA dataset by manually creating domain-specific vocabulary and annotations with scores for probable answers. The model, however, did not perform well on the dataset as it was constrained to generating single-word answers and lacked the capability of generating coherent reasoning like Text-to-Text Language models (T5 [4] ).
We started with a textual question-answering task to evaluate the reasoning capabilities of our models. The following models were used in our experiments:- Baseline: A simple QA model based on DistilBERT and RoBERTa. These models were chosen due to their relatively small size, making them suitable for training with our computational resources. Moreover, they have been shown to perform decently on multiple-choice questions.
- T5 without reasoning: We trained a T5-small model without any reasoning capabilities to assess the impact of adding CoT reasoning.
- T5 with reasoning: We further trained a T5-small model with reasoning capabilities, integrating the CoT approach.
- T5 with reasoning and image captions: To assess the potential benefits of adding image information, we trained a T5-small model with reasoning capabilities and image captions.
- Fine-tuned VQA model on Science QA Dataset: We fine-tuned the pre-trained ViLT(Vision & Language Transformer) model for visual question answering. We created domain-specific vocabulary and annotations using the ScienceQA dataset and used the ViLT model to generate answers. The ViLT model, however, did not perform well on the dataset as it was constrained to generating single-word answers and lacked the capability of generating coherent reasoning like Text-to-Text Language models (T5).
- We also attempted to integrate the visual embeddings from models like DETR into the VisualBert model. However, we were not successfully able to concatenate the visual and text features to re-train the VisualBert model. This was due to the varying hidden dimension of the textual encodings for different downstream task models in VisualBert.
- Integrated model with T5 textual embeddings: We generated image captions from a Vision Transformer model (ViT-GPT2 [6] ) and used that along with textual input to T5-small model and experimented with different training strategies and settings to assess the impact of adding reasoning capabilities and image context.
We ran our experiments for answer generation on both TextVQA and ScienceQA dataset along with setting up the training for Answer and Explanation generation solely on the ScienceQA dataset where we had ground truth explanations (solutions) for which we measured the Rogue F1 scores.
We set-up our experiments on Google Cloud Platform using GPU setting for the training and evaluation of our models. For the experiments with the T5 model, we used the Adam Optimizer for training with a learning rate of 1e-5. We also used a linear learning rate scheduler with number of training steps as 10000 and a number of warm up steps as 500. We set the max input and output length depending on the downstream task we attempted to solve (128 for answer generation and 256 for explanation generation).
We also explored gradient clipping to avoiding exploding gradient in the training strategy. We monitored both the training and validation loss after each epoch with the total number of epochs finally set to 10.
To measure the performance of the models, we used the following metrics:
- Accuracy: We computed the accuracy by comparing the model’s predictions with the ground truth answers.
- ROUGE
$F_{1}$ score: These metrics evaluate the quality of the generated text by comparing it to the reference text. They provide a quantitative measure of the model’s performance. The$F_{1}$ score was chosen as it provides a balance between precision and recall.
Table below depicts Evaluation metrics for models on the generation downstream tasks on ScienceQA Dataset :
| Model | Generation Task | Train Accuracy | Validation Accuracy | Rouge-1 F1 | Rouge-2 F1 | Rouge-L F1 |
|---|---|---|---|---|---|---|
| Model 1 | Answer | - | 48.74% | - | - | - |
| Model 2 | Answer | 45.66% | 43.65% | - | - | - |
| Model 3 | Answer, Explanation | 41.32% | 39.09% | 0.41 | 0.298 | 0.375 |
| Model 4 | Answer, Explanation | 48.54% | 45.84% | 0.451 | 0.331 | 0.408 |
| Model 5 | Answer (Input Explanation) | 45.01% | 41.99% | - | - | - |
| Model 6 | Answer (Input Explanation) | 51.76% | 48.86% | - | - | - |
Descriptions of Individual Models and Associated Loss Curve:
-
Model 1: Baseline pre-trained T5 model fine-tuned for the task of answer generation without the usage of image captions.
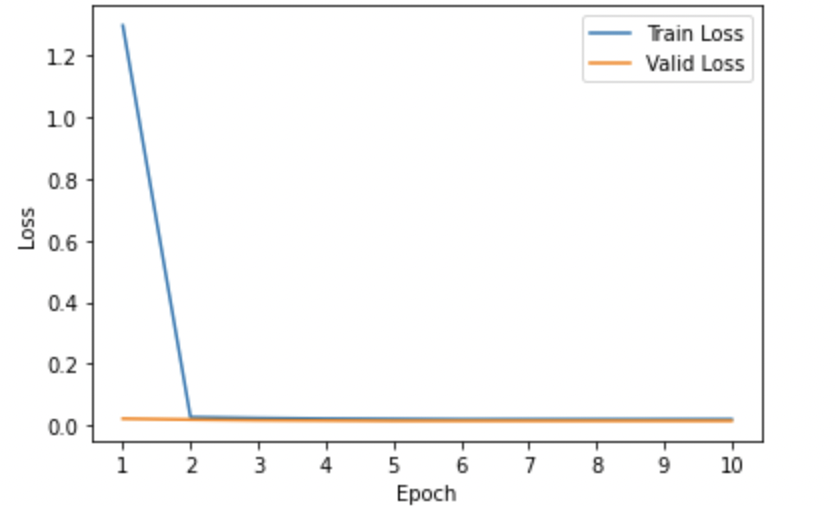
-
Model 2: Baseline pre-trained T5 model fine-tuned for the task of answer generation with the usage of image captions.
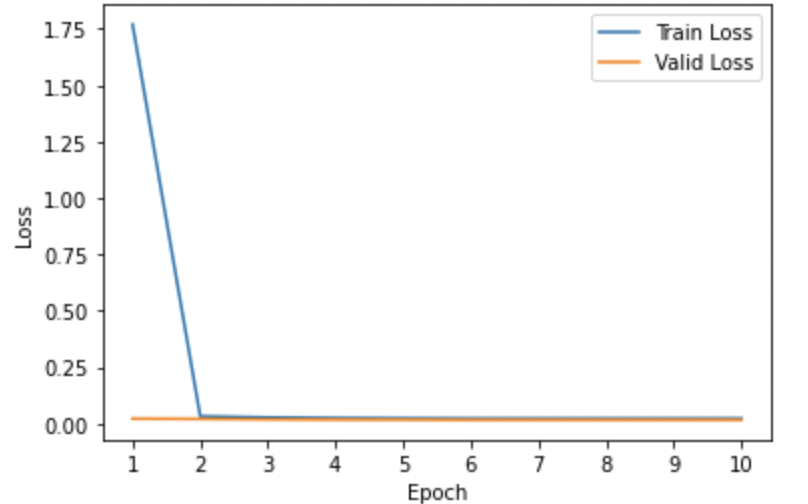
-
Model 3: Baseline pre-trained T5 model fine-tuned for the task of answer and explanation generation with the image captions.
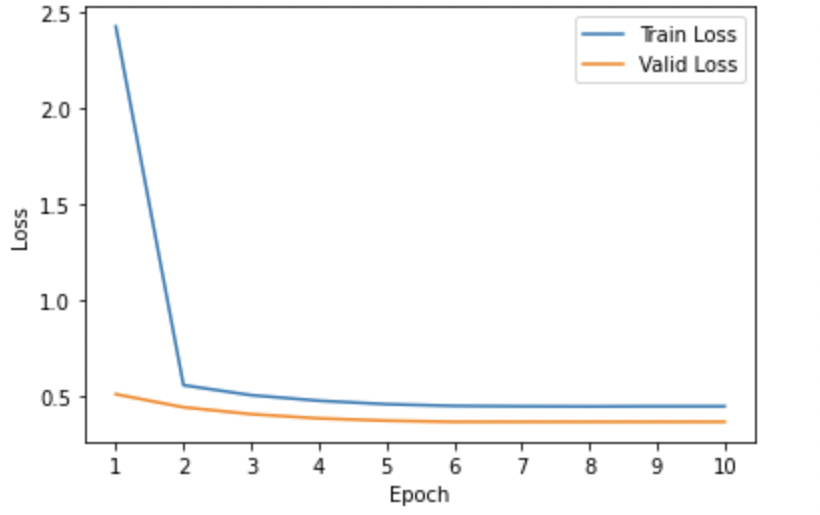
-
Model 4: Model fine-tuned for the task of generating both answers and explanations using the fine-tuned model for answer generation.
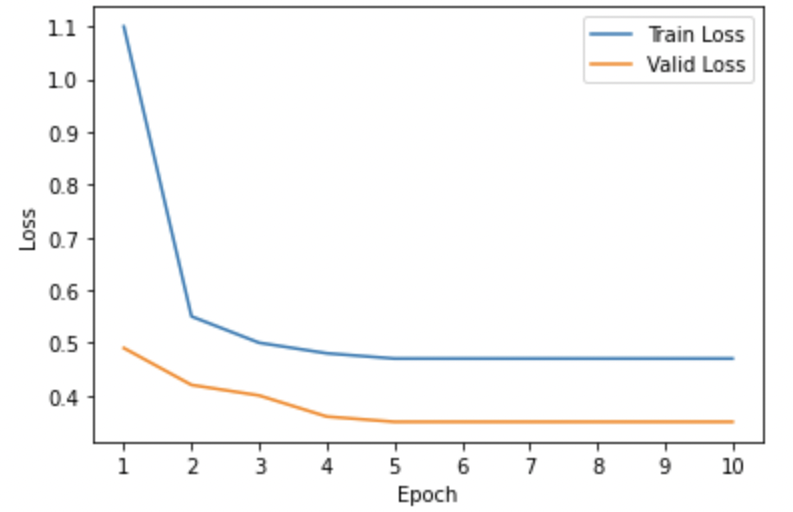
-
Model 5: Baseline pre-trained T5 model fine-tuned for the task of answer generation with the model generated explanation as input.
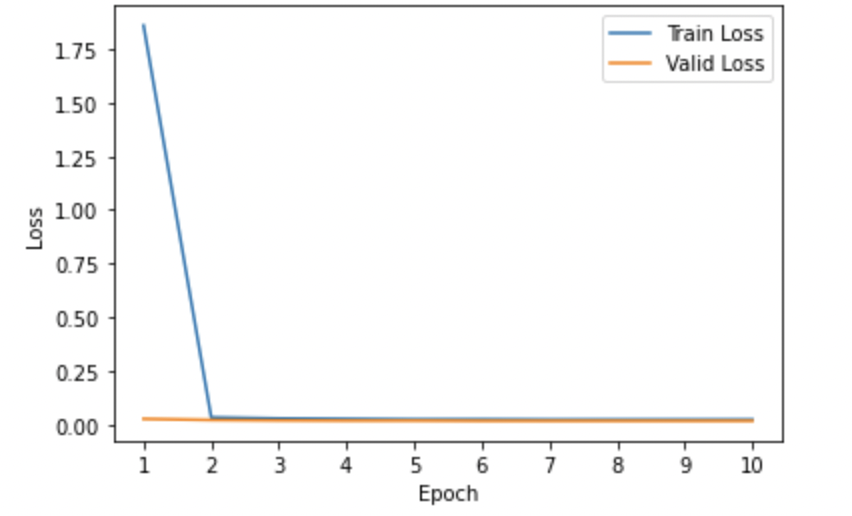
-
Model 6: fine-tuned Model 2 for the task of answer generation with the model-generated explanation as input.
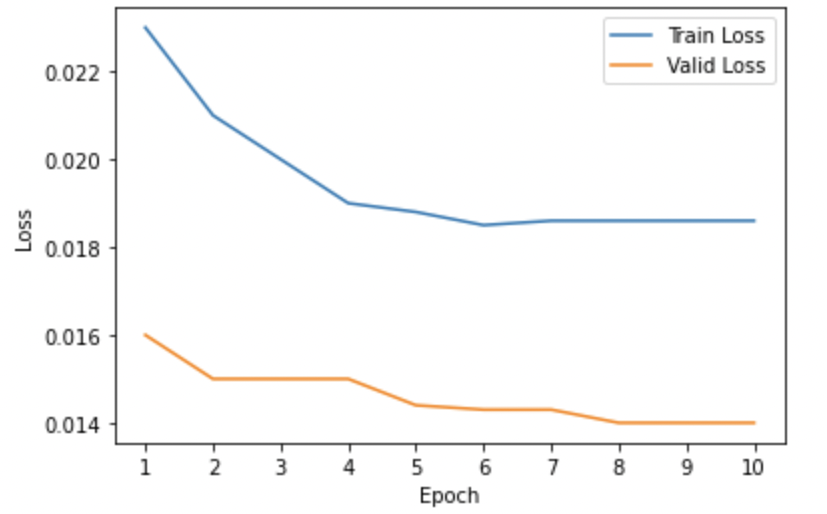






- Training and Validation Loss Curves: We analyzed the loss curves specific to all 6 model variants illustrated using Figures 1-6 respectively. Most of the curves showed a sharp dip in the training loss in the first epoch suggesting that the pre-trained T5 model was pretty quick in re-adjusting its weights to better align with the domain-specific examples. The validation losses in most cases were pretty low from the initial get-go. Also, we observed convergence in the training and validation losses for almost all model variants suggesting that running the model for more than 10 epochs would pose the risk of running into an overfitting problem. Also, for (Model6) which we found to be the best-performing model, we could see pretty low values of both training and validation losses when compared to other models from initial epochs.
- The models that were trained using image captions along with context and hint (Model 2) did not outperform the model without the image captions (Model 1) when compared on the validation dataset. This was slightly counter-intuitive but the reason for it might be that the model suffered from information overload and could not specifically utilize the captions when provided along with hint and context. This also highlights the importance of working with models that can exploit the mutual synergies of different modalities like text and vision features with an attention mechanism to generate coherent reasoning. The idea of using the image features as textual image captions did not yield enhanced performance.
- The model that was trained to generate answers and explanations simultaneously (Model3) was outperformed by the model trained on just generating answers (Model2). This emphasizes the fact that task-specific training gives better results and prevents the model from information load.
- The models that were directly fine-tuned from the pre-trained T5 conditional model on generating both answers and explanations simultaneously (Model3) was outperformed by the model (Model4) which was fine-tuned first on generating answers and then using that model checkpoint to generate answers and explanations. This makes sense as it emphasizes that the fine-tuned model on a domain-specific dataset could leverage its previous learnings to perform well on subsequent runs.
- Knowledge Distillation with teacher training: We found that the models which utilized the generated explanations from the same model in the previous run (Model5, Model 6) outperformed the model trained on directly generating answers respectively (Model2). This is also intuitive as using the model-generated explanations acts as positive feedback as the model learns to better its prediction on the answers using that as additional input.
- For the downstream task of answer generation, we also see that the T5-small model trained on the TextVQA dataset outperformed the other models tested on the ScienceQA dataset with a training accuracy of 65.92% and an accuracy of 62.66%. This is in accordance with our hypothesis as this dataset had more training examples and all the examples contained images unlike the ScienceQA dataset. Additionally, a lot of the questions in the ScienceQA dataset involved very domain-specific vocabulary and trickier questions for the model to learn from given only the caption and hint which is why we wish to further explore models that take into account vision features as well.
-
The figure below shows the T5 model output generating answer and explanation simultaneously. It also has the example input (which is a mix of question, choices, context, and hint) and the target output which the model uses in its training phase.

-
The figure below shows the same T5 model as in Figure 1 above finetuned for the task of generating answer, explanation, and lecture simultaneously. This produces a rich expression and reasoning behind the model’s answers.

-
The figure below shows an example of hallucination. This explains the need for teacher training or feedback mechanism - i.e. using the model-generated explanations to infer the answers. A lot of times we encounter such hallucination examples where the answer generated by the model is at odds with the model-generated example. Thus, in these cases, 2-stage framework works best which incorporates the generated explanation to produce answers in the subsequent run.

-
The figure below clearly explains why the T5 model is pretty good in answering domain-specific questions after properly finetuning the model. The ViLT model for question answering produces a very generic response and is not able to output coherent sentences as it generates a probability distribution over the entire vocabulary.

- Questions: Which is this organism’s common name?
- Choices: crown-of-thorns sea star, Acanthaster planci
- Caption: a blue and white vase sitting on top of a rock
- T5 model’s answer: crown-of-thorns sea star
- ViLT Model’s Answer: fish
- Target Answer: crown-of-thorns sea star
[1] Abdokamr. Question answering with t5, Aug 2021 (https://www.kaggle.com/code/abdokamr/question-answering-with-t5)
[2] Hugging Face. Document question answering. (https://huggingface.co/docs/transformers/tasks/document_question_answering)
[3] Hugging Face. Multiple choice. (https://huggingface.co/docs/transformers/tasks/multiple_choice)
[4] Hugging Face. T5 small model. (https://huggingface.co/t5-small)
[5] Hugging Face. Vilt model documentation. (https://huggingface.co/docs/transformers/model_doc/vilt)
[6] Hugging Face. Vision transformer model documentation. (https://huggingface.co/docs/transformers/model_doc/vit)
[7] Hugging Face. Visual bert model documentation. (https://huggingface.co/docs/transformers/model_doc/visual_bert)
[8] Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361
[9] Daniel Khashabi, Tushar Chaudhary, Ayush Sen, Jing Chen, Yejin Choi, and Mirella Lapata. Unifiedqa: Crossing format boundaries with a single qa system (https://aclanthology.org/2020.findings-emnlp.171.pdf)
[10] Wonjae Kim, Kyung-Min Lee, Jin-Hwa Lee, Chanho Park, Youngeun Jang, Seonguk Park, Byeongchang Yoon, and Sung Ju Hwang. Vilt: Vision-and-language transformer without convolution or region supervision. (https://arxiv.org/pdf/2102.03334.pdf)
[11] iunian Harold Li, Yatskar Mark, Chen Da, Matt Hessel, and Dragomir Radev. Visualbert: A simple and performant baseline for vision and language (https://arxiv.org/pdf/1908.03557.pdf)
[12] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach (https://arxiv.org/pdf/1907.11692.pdf)
[13] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vil- bert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks(https://arxiv.org/pdf/1908.02265.pdf)
[14] OpenAI. Gpt-4 technical report
[15] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter (https://arxiv.org/pdf/1910.01108v4.pdf)
[16] Towards Data Science. Adding custom layers on top of a hugging face mode (https://towardsdatascience.com/adding-custom-layers-on-top-of-a-hugging-face-model-f1ccdfc257bd)
[17] ScienceQA. Scienceqa: A multimodal multiple-choice science question dataset. (https://scienceqa.github.io/)
[18] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, DSOTA23evi Parikh, and Marcus Rohrbach. Towards vqa models that can read (https://arxiv.org/pdf/1904.08920.pdf)
[19] Text VQA. Text vqa: A dataset for reasoning about text in images (https://textvqa.org/)
[20] Ji Wei, Yixin Hao, Antoine Bosselut, and Yejin Choi. Chain-of-thought prompting elicits reasoning in large language models (https://arxiv.org/pdf/2201.11903.pdf)
[21] Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of-thought reasoning in language models



