
-
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
📌 Take a quick look at our MobileVLM V2 architecture
We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs’ performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale.
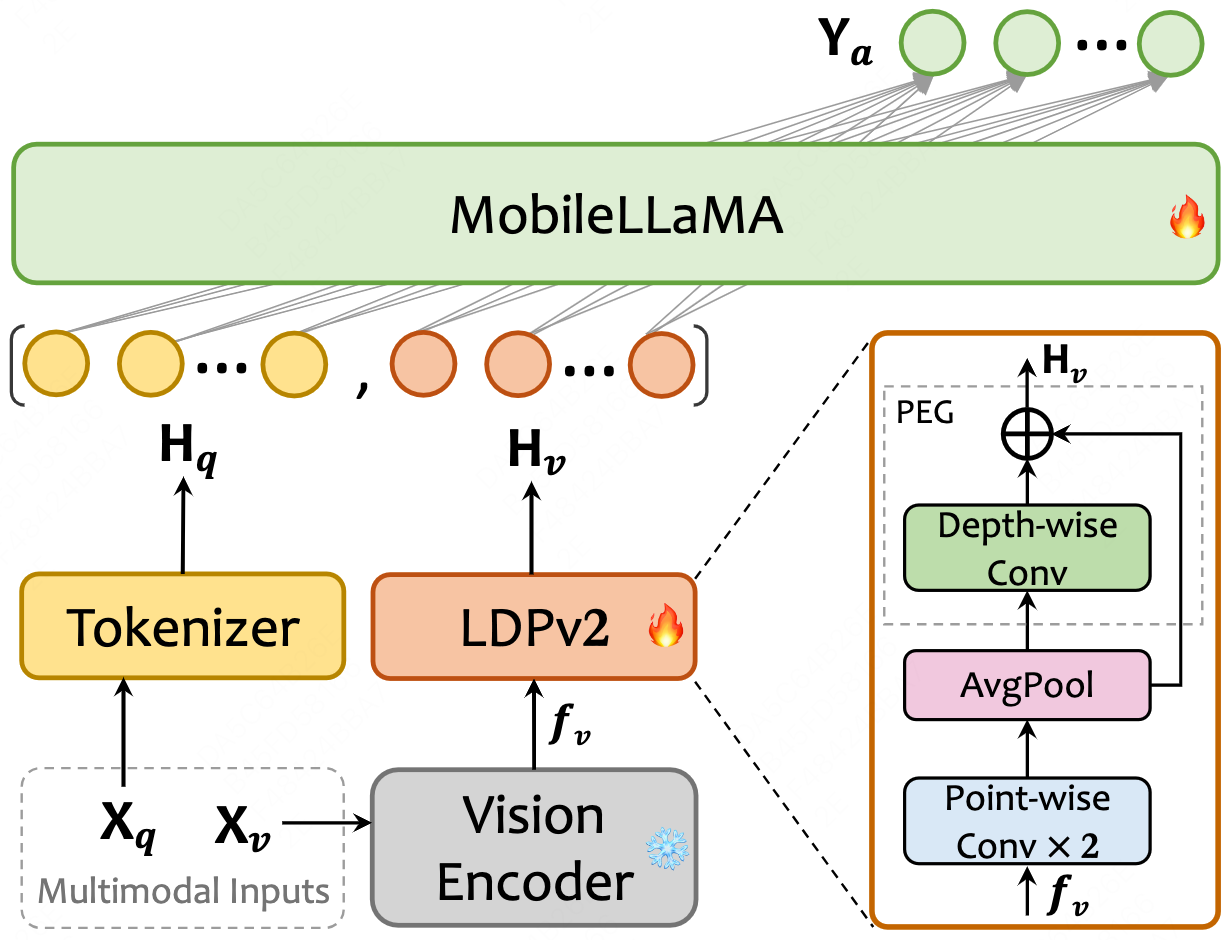
MobileVLM V2’s architecture. Xv and Xq indicate image and language instruction, respectively, and Ya refers to the text response from the language model MobileLLaMA. The diagram in the lower right corner is a detailed description of LDPv2, i.e., the lightweight downsample projector v2.
-
MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices
📌 Take a quick look at our MobileVLM architecture
We present MobileVLM, a competent multimodal vision language model (MMVLM) targeted to run on mobile devices. It is an amalgamation of a myriad of architectural designs and techniques that are mobile-oriented, which comprises a set of language models at the scale of 1.4B and 2.7B parameters, trained from scratch, a multimodal vision model that is pre-trained in the CLIP fashion, cross-modality interaction via an efficient projector. We evaluate MobileVLM on several typical VLM benchmarks. Our models demonstrate on par performance compared with a few much larger models. More importantly, we measure the inference speed on both a Qualcomm Snapdragon 888 CPU and an NVIDIA Jeston Orin GPU, and we obtain state-of-the-art performance of 21.5 tokens and 65.3 tokens per second, respectively.
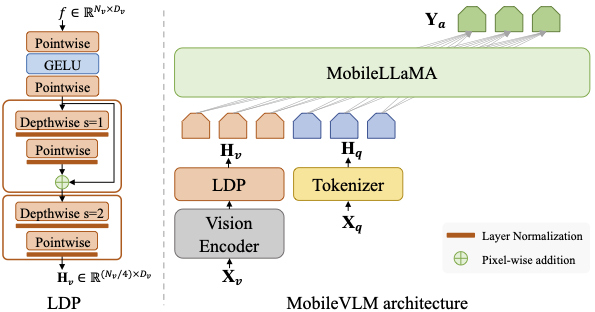
The MobileVLM architecture (right) utilizes MobileLLaMA as its language model, intakes Xv and Xq which are image and language instructions as respective inputs and gives Ya as the output language response. LDP refers to a lightweight downsample projector.


- ⏳ MobileLLaMA Pre-training code.
Feb. 26th, 2024: MobileVLM V2 training data and code are available now! Follow the instructions below to train your own mobileVLM V2 model !Feb. 06th, 2024: 🔥🔥🔥 MobileVLM V2 is out! Paper here! The inference code of MobileVLM V2 is available now! Our MobileVLM V2 weights are publicly available on the HuggingFace website. Enjoy them !Feb. 06th, 2024: The SFT code and dataset of MobileLLaMA are released now! You can train your own chat model.Jan. 23rd, 2024: 🚀🚀🚀 MobileVLM is officially supported byllama.cppnow ! Have a try !Jan. 15th, 2024: Customizedllama.cppfor MobileVLM and its deployment instruction on mobile devices.Jan. 11st, 2024: The training and evaluation codes of MobileVLM are available now! Follow these step-by-step instructions below to easily train your own mobileVLM in 5 hours ⚡️ !Dec. 31st, 2023: Our MobileVLM weights are uploaded on the HuggingFace website. We also provide inference examples for the MobileLLaMA/MobileVLM model so that anyone can enjoy them early.Dec. 29th, 2023: Our MobileLLaMA weights are uploaded on the HuggingFace website. Enjoy them !Dec. 28th, 2023: 🔥🔥🔥 We release MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices on arxiv. Refer to our paper for more details !
| Model | LLM | GQA | SQAI | VQAT | POPE | MMEP | MMBdev | Avg. |
|---|---|---|---|---|---|---|---|---|
| 56.1 | 57.3 | 41.5 | 84.5 | 1196.2 | 53.2 | 58.7 | ||
| MobileVLM V2 1.7B | MobileLLaMA 1.4B | 59.3 | 66.7 | 52.1 | 84.3 | 1302.8 | 57.7 | 64.2 |
| MobileVLM-3B | MobileLLaMA 2.7B | 59.0 | 61.2 | 47.5 | 84.9 | 1288.9 | 59.6 | 62.8 |
| MobileVLM V2 3B | MobileLLaMA 2.7B | 61.1 | 70.0 | 57.5 | 84.7 | 1440.5 | 63.2 | 68.1 |
| MobileVLM V2 7B | Vicuna-7B | 62.6 | 74.8 | 62.3 | 85.3 | 1560.7 | 69.2 | 72.1 |
🔔 Usage and License Notices: This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses. This project is licensed permissively under the Apache 2.0 license and does not impose any additional constraints. LLaVA
-
Clone this repository and navigate to MobileVLM folder
git clone https://github.com/Meituan-AutoML/MobileVLM.git cd MobileVLM -
Install Package
conda create -n mobilevlm python=3.10 -y conda activate mobilevlm pip install --upgrade pip pip install -r requirements.txt
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM
model_path = 'mtgv/MobileLLaMA-1.4B-Chat'
tokenizer = LlamaTokenizer.from_pretrained(model_path)
model = LlamaForCausalLM.from_pretrained(
model_path, torch_dtype=torch.float16, device_map='auto',
)
prompt = 'Q: What is the largest animal?\nA:'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
generation_output = model.generate(
input_ids=input_ids, max_new_tokens=32
)
print(tokenizer.decode(generation_output[0]))- For more advanced usage, please follow the transformers LLaMA documentation.
from scripts.inference import inference_once
# model_path = "mtgv/MobileVLM-1.7B" # MobileVLM
model_path = "mtgv/MobileVLM_V2-1.7B" # MobileVLM V2
image_file = "assets/samples/demo.jpg"
prompt_str = "Who is the author of this book?\nAnswer the question using a single word or phrase."
# (or) What is the title of this book?
# (or) Is this book related to Education & Teaching?
args = type('Args', (), {
"model_path": model_path,
"image_file": image_file,
"prompt": prompt_str,
"conv_mode": "v1",
"temperature": 0,
"top_p": None,
"num_beams": 1,
"max_new_tokens": 512,
"load_8bit": False,
"load_4bit": False,
})()
inference_once(args)The training process of MobileVLM V2 is divided into two stages:
- stage I: pre-training
- ❄️ frozen vision encoder + 🔥 learnable LDP V2 projector + 🔥 learnable LLM
- this training process takes around 3~5 hours for MobileVLM V2-1.7B/3B on 8x A100 (80G) with a batch size of 256 and an average of approximately 38G/51G of GPU memory required.
- stage II: multi-task training
- ❄️ frozen vision encoder + 🔥 learnable LDP V2 projector + 🔥 learnable LLM
- this training process takes around 9~12 hours for MobileVLM V2-1.7B/3B on 8x A100 (80G) with a batch size of 128 and an average of approximately 45G/52G of GPU memory required.
- note: if you are interest in MobileVLM V1 training recipe, please refer to our previous README.
Similar to MobileVLM, please firstly download MobileLLaMA chatbot checkpoints from huggingface website (🤗 1.7B, 2.7B). Please note that this is optional (it depends on your working environment), run the training script we provide below and the model will be automatically downloaded by the transformers library.
-
For convenience, assume your working directory
/path/to/project/mobilevlmaswork_dir:cd ${work_dir} && mkdir -p data/pretrain_data data/finetune_data data/benchmark_data
-
prepare pre-training data
cd ${work_dir}/data/pretrain_data- download the ShareGPT4V-PT from here, which is provided by ShareGPT4V team.
-
prepare multi-task training data
cd ${work_dir}/data/finetune_data- download the annotation of our MobileVLM_V2_FT_Mix2M data from huggingface here, and download the images from constituting datasets: Text-VQA, IConQA, SQA, SBU, follow ShareGPT4V to download images from: LAION-CC-SBU-558K, COCO, WebData, SAM, GQA, OCR-VQA, TextVQA, VisualGnome (Part1, Part2)
-
prepare benchmark data
-
We evaluate models on a diverse set of 6 benchmarks, i.e. GQA, MMBench, MME, POPE, SQA, TextVQA. We do not evaluate using beam search to make the inference process consistent with the chat demo of real-time outputs. You should follow these instructions to manage the datasets.
-
Data Download Instructions
- download some useful data/scripts pre-collected by us.
unzip benchmark_data.zip && cd benchmark_databmk_dir=${work_dir}/data/benchmark_data
- gqa
- download its image data following the official instructions here
cd ${bmk_dir}/gqa && ln -s /path/to/gqa/images images
- mme
- download the data following the official instructions here.
cd ${bmk_dir}/mme && ln -s /path/to/MME/MME_Benchmark_release_version images
- pope
- download coco from POPE following the official instructions here.
cd ${bmk_dir}/pope && ln -s /path/to/pope/coco coco && ln -s /path/to/coco/val2014 val2014
- sqa
- download images from the
data/scienceqafolder of the ScienceQA repo. cd ${bmk_dir}/sqa && ln -s /path/to/sqa/images images
- download images from the
- textvqa
- download images following the instructions here.
cd ${bmk_dir}/textvqa && ln -s /path/to/textvqa/train_images train_images
- mmbench
- no action is needed.
- download some useful data/scripts pre-collected by us.
-
-
organize the
datadirectory as follows after downloading all of them:-
Data Structure Tree
. ├── benchmark_data │ ├── gqa │ │ ├── convert_gqa_for_eval.py │ │ ├── eval.py │ │ ├── images -> /path/to/your/gqa/images │ │ ├── llava_gqa_testdev_balanced.jsonl │ │ └── testdev_balanced_questions.json │ ├── mmbench │ │ ├── convert_mmbench_for_submission.py │ │ ├── eval.py │ │ └── mmbench_dev_en_20231003.tsv │ ├── mme │ │ ├── calculation.py │ │ ├── convert_answer_to_mme.py │ │ ├── images -> /path/to/your/MME/MME_Benchmark_release_version │ │ └── llava_mme.jsonl │ ├── pope │ │ ├── coco -> /path/to/your/pope/coco │ │ ├── eval.py │ │ ├── llava_pope_test.jsonl │ │ └── val2014 -> /path/to/your/coco/val2014 │ ├── sqa │ │ ├── eval.py │ │ ├── images -> /path/to/your/scienceqa/images │ │ ├── llava_test_CQM-A.json │ │ ├── pid_splits.json │ │ └── problems.json │ └── textvqa │ ├── eval.py │ ├── llava_textvqa_val_v051_ocr.jsonl │ ├── TextVQA_0.5.1_val.json │ └── train_images -> /path/to/your/textvqa/train_images ├── finetune_data │ ├── llava_v1_5_mix665k.json │ ├── MobileVLM_V2_FT_Mix2M.json │ ├── coco │ │ ├── train2017 │ │ └── val2017 │ ├── gqa │ │ └── images │ ├── iconqa_data │ │ └── iconqa │ │ └── train │ │ ├── choose_img │ │ ├── choose_txt │ │ └── fill_in_blank │ ├── ocr_vqa │ │ └── images │ ├── sam │ │ └── images │ ├── SBU │ │ └── images │ ├── ScienceQA │ │ └── train │ ├── share_textvqa │ │ └── images │ ├── textvqa │ │ └── train_images │ ├── vg │ │ ├── VG_100K │ │ └── VG_100K_2 │ ├── web-celebrity │ │ └── images │ ├── web-landmark │ │ └── images │ └── wikiart │ └── images └── pretrain_data ├── share-captioner_coco_lcs_sam_1246k_1107.json ├── blip_laion_cc_sbu_558k.json ├── images ├── coco │ └── train2017 ├── llava │ └── llava_pretrain └── sam └── images
-
LANGUAGE_MODEL=/path/to/your/MobileLLaMA-1.4B-Chat # or 2.7B
VISION_MODEL=/path/to/your/clip-vit-large-patch14-336
bash run.sh mobilevlm_v2_1.7b pretrain-finetune-test ${LANGUAGE_MODEL} ${VISION_MODEL}
# (test-only) bash run.sh mobilevlm_v2_1.7b test /path/to/your/own/checkpoint
# (3B) bash run.sh mobilevlm_v2_3b pretrain-finetune-test ${LANGUAGE_MODEL} ${VISION_MODEL}- Note 🧭: We place all running commands in
run.shso they can be run with one click for simplification. If you would like to modify some super-parameters to observe their impact, please dive intorun.shto explore.
The SFT(supervised fine-tuning) process of MobileLLaMA:
- please refer to MobileLLaMA_SFT.md for the env, dataset and training code of our MobileLLaMA SFT.
- this training process takes around 3~5 hours for MobileLLaMA 1.4B/2.7B on 8x A100 (80G)
Note: You may skip MobileLLaMA training processes and directly start with MobileVLM, leveraging our pre-trained MobileLLaMA model from huggingface website (🤗 1.7B, 2.7B). .
MobileVLM now is officially supported by llama.cpp. We are looking for more cooperation with open-source communities on the deployment of mobile devices.
- llama.cpp: the repository of official
llama.cpp. Step-by-step deployment instructions are provided here.
- LLaVA: the codebase we built upon. Thanks for their wonderful work! 👏
- Vicuna: the amazing open-sourced large language model!
- llama.cpp: the great open-sourced framework for the inference of LLaMA model in pure C/C++!
If you find MobileVLM or MobileLLaMA useful in your research or applications, please consider giving a star ⭐ and citing using the following BibTeX:
@article{chu2023mobilevlm,
title={Mobilevlm: A fast, reproducible and strong vision language assistant for mobile devices},
author={Chu, Xiangxiang and Qiao, Limeng and Lin, Xinyang and Xu, Shuang and Yang, Yang and Hu, Yiming and Wei, Fei and Zhang, Xinyu and Zhang, Bo and Wei, Xiaolin and others},
journal={arXiv preprint arXiv:2312.16886},
year={2023}
}
@article{chu2024mobilevlm,
title={MobileVLM V2: Faster and Stronger Baseline for Vision Language Model},
author={Chu, Xiangxiang and Qiao, Limeng and Zhang, Xinyu and Xu, Shuang and Wei, Fei and Yang, Yang and Sun, Xiaofei and Hu, Yiming and Lin, Xinyang and Zhang, Bo and others},
journal={arXiv preprint arXiv:2402.03766},
year={2024}
}