This project involves setting up a complete data pipeline using Microsoft Azure services, including Azure Data Factory (ADF), Azure Data Lake Storage Gen 2 (ADLS Gen 2), Azure Databricks, and dbt (Data Build Tool). The pipeline processes data from an SQL database, transforms it, and stores it in different layers (Bronze, Silver, and Gold) in a Delta Lake format.
Project architecture:

- Project Overview
- Technologies Used
- Setup and Installation
- Usage
- Instructions
- Project Structure
- Features
- Contributing
- License
The Medallion Project demonstrates the implementation of a data pipeline that ingests data from an SQL database (medallion-db) and processes it into three layers: Bronze, Silver, and Gold. The pipeline uses Azure Data Factory to dynamically extract table names from the source database and bulk copy the data into the Bronze layer using Azure Databricks to create Delta tables. The data is then transformed and loaded into the Silver and Gold layers using dbt.
- Azure Data Factory: Orchestrates the data pipeline and handles dynamic data extraction and loading.
- Azure Data Lake Storage Gen 2: Stores data in the Bronze, Silver, and Gold layers.
- Azure Databricks: Performs the initial data transformation and stores the data as Delta tables.
- dbt (Data Build Tool): Transforms and loads data into the Silver and Gold layers.
- Azure Key Vault: Secures sensitive information, such as connection strings and credentials.
- SQL Database (medallion-db): Source of the data.
Ensure you have the following installed:
- Azure account with necessary services (Key Vault, Storage Account, Data Factory, Databricks)
- Local environment with dbt installed
- Azure CLI for resource management
- Docker (optional, if using containers)
-
Clone the repository
git clone https://github.com/yourusername/medallion_project.git cd medallion_project -
Configure Azure Services
- Set up the Azure resources (Storage Account, Data Factory, Key Vault, Databricks) using the provided ARM templates or manually through the Azure Portal.
-
Configure ADF Pipeline
- Use the lookup function in ADF to fetch table names from the medallion-db.
- Implement a
ForEachloop in ADF to dynamically process each table and copy data to the Bronze layer in ADLS Gen 2. - Pipeline:
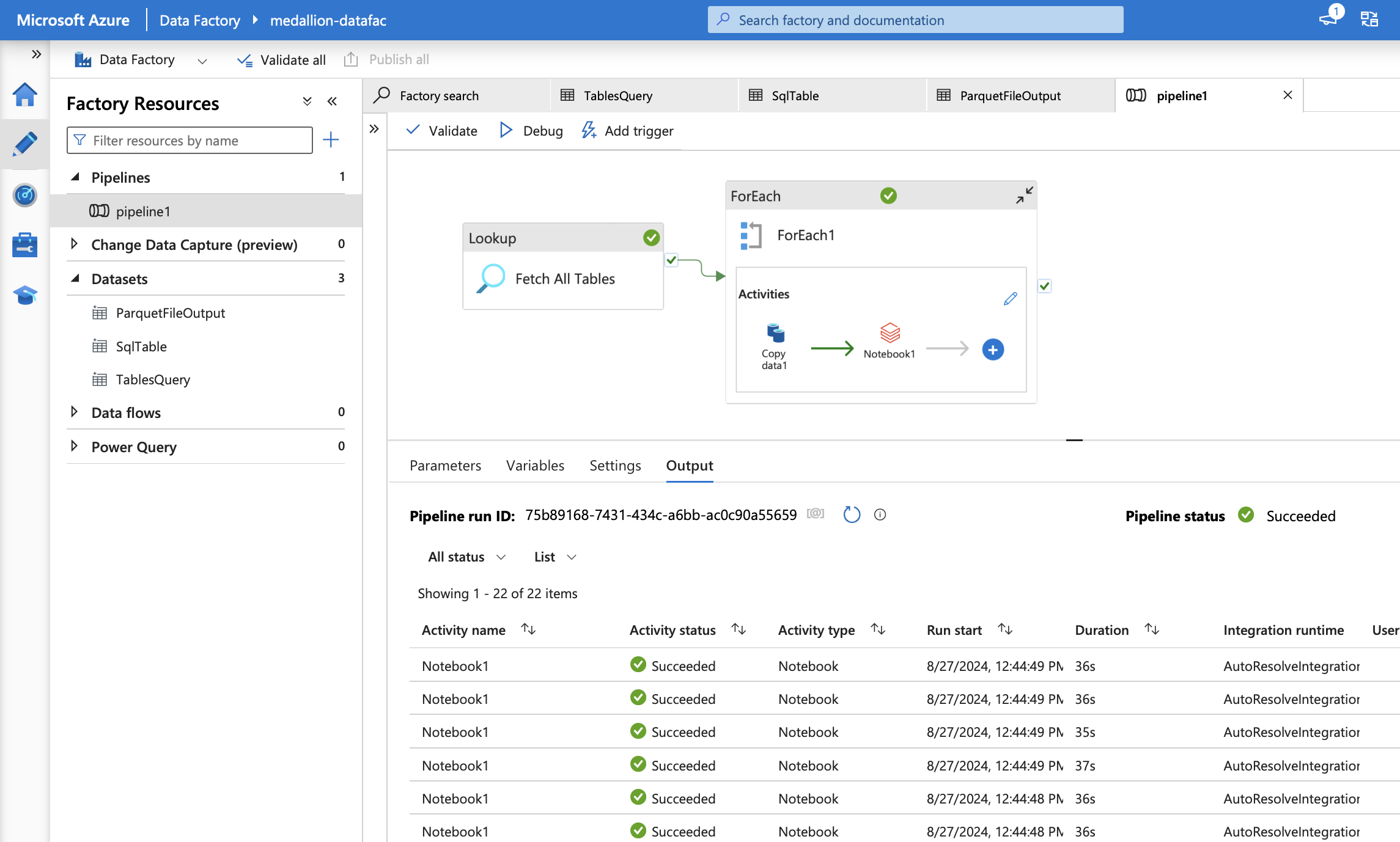
-
Set up Databricks
- Create a Databricks cluster and configure it to work with the ADLS Gen 2 storage.
- Write and execute notebooks to process the data and create Delta tables in the Bronze layer.
- You can use the notebook located at
azure_references/databricks/base_notebook.ipynbto accomplish this task.
-
Install dbt
- Install dbt in your local environment:
pip install dbt
- Set up the dbt project to transform and load data into the Silver and Gold layers by copying the code from the
modelsandsnapshotsdirectories in the cloned repository.
- Install dbt in your local environment:
-
Run the Pipeline
- Trigger the ADF pipeline to start the data ingestion process.
- Use dbt to transform and load data into the Silver and Gold layers by running the following commands:
dbt debug dbt run

-
ADF Pipeline Execution:
- Access Azure Data Factory and trigger the pipeline to start the data ingestion process from medallion-db to the Bronze layer.
-
Data Transformation with dbt:
- In your local environment, use dbt to run the transformation models and load data into the Silver and Gold layers.
-
Monitoring and Logging:
- Monitor the execution of the pipeline in Azure Data Factory and check logs in Azure Databricks for any issues.
-
Extract Data:
- ADF dynamically retrieves table names from medallion-db using the lookup function.
- Data is bulk copied into the Bronze layer using Databricks, creating Delta tables.
-
Transform and Load Data:
- dbt transforms the data in the Bronze layer and loads it into the Silver layer.
- Further transformations are applied using dbt models, and the data is loaded into the Gold layer.
-
Run dbt Models:
- Execute the dbt models in your local environment to perform the necessary transformations.
The project is organized as follows:
README.md: Project overview and instructionsazure_references: Azure-specific references and resourcesadf_workflow.png: Diagram of ADF workflowdatabricksbase_notebook.ipynb: Base notebook for Databricks processingcatalog.png: Catalog image reference
logs: Log filesmedallion_dbt: dbt project directoryREADME.md: Overview of the dbt projectanalyses: Folder for analysis files (currently empty)dbt_project.yml: dbt project configurationlogsdbt.log: Additional dbt log file
macros: Custom dbt macros (currently empty)models: dbt models for data transformationsmarts: Data marts for specific subject areascustomer: Customer-related modelsdim_customer.sql: SQL script for customer dimension tabledim_customer.yml: Metadata for customer dimension table
product: Product-related modelsdim_product.sql: SQL script for product dimension tabledim_product.yml: Metadata for product dimension table
sales: Sales-related modelssales.sql: SQL script for sales fact tablesales.yml: Metadata for sales fact table
staging: Staging area for raw databronze.yml: Metadata for Bronze staging layer
seeds: Seed data (currently empty)snapshots: dbt snapshots for historical data trackingaddress.sql: SQL script for address snapshotcustomer.sql: SQL script for customer snapshotcustomeraddress.sql: SQL script for customer address snapshotproduct.sql: SQL script for product snapshotproductmodel.sql: SQL script for product model snapshotsalesorderdetail.sql: SQL script for sales order detail snapshotsalesorderheader.sql: SQL script for sales order header snapshot
target: Directory for compiled and run artifactstests: Directory for dbt tests (currently empty)
project_architecture.png: Image of the project architecture
- Dynamic Data Extraction: Automatically extracts table names and processes data in bulk.
- Layered Data Architecture: Organizes data into Bronze, Silver, and Gold layers for better data management.
- Delta Lake: Uses Delta tables for efficient data storage and retrieval.
- dbt Integration: Leverages dbt for robust data transformation and version control.
Contributions are welcome! To contribute:
- Fork the repository.
- Create a new branch (
git checkout -b feature-branch). - Make your changes and commit them (
git commit -m 'Add new feature'). - Push to the branch (
git push origin feature-branch). - Open a pull request.
Please ensure your code follows the project's coding standards and includes relevant tests.
This project is licensed under the MIT License. See the LICENSE file for details.