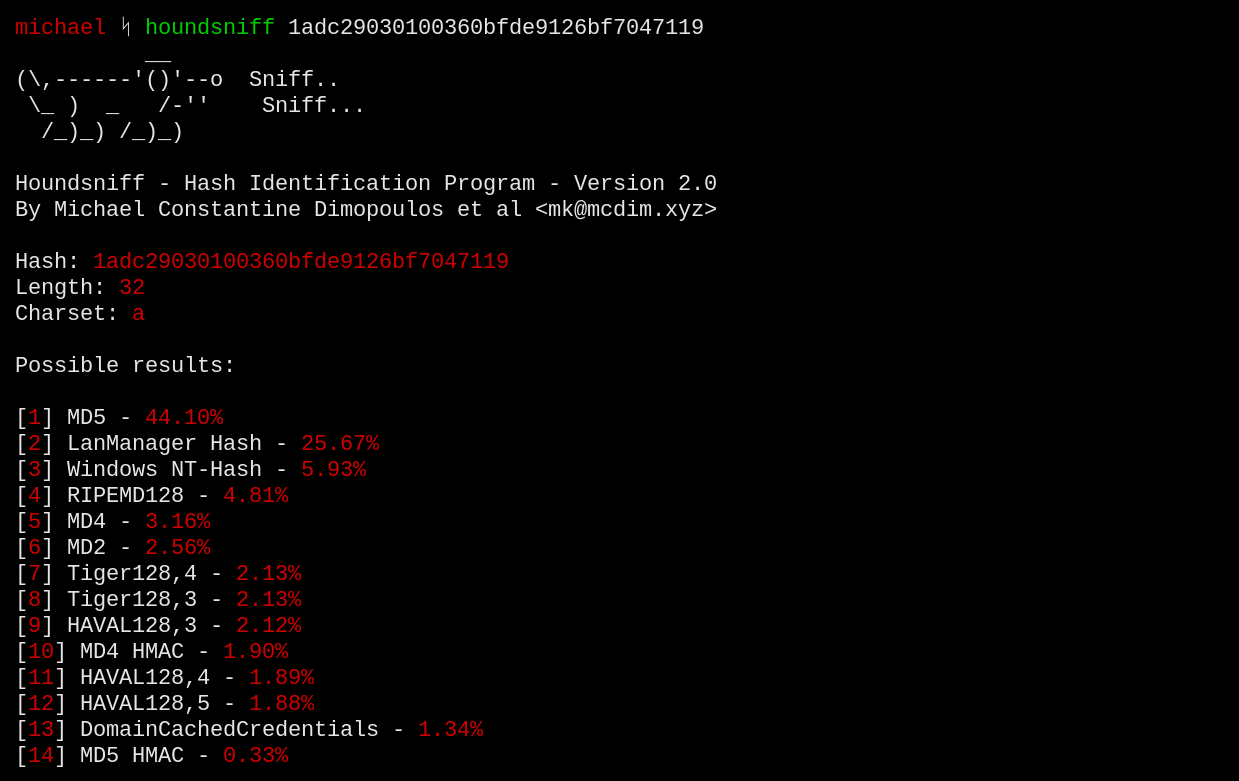
Houndsniff is a minimal hash identification tool written in C that uses a database to compare a hash's features to characteristics of other common hashing algorithm results. It also prints out the percentages of likelihood for each hashing alogirthm to be the one that produced the hash based on their popularity. Email hashes that I missed at mk@mcdim.xyz
Website: https://mcdim.xyz/projects/hs.html
By Michael Constantine Dimopoulos, et al
with significant contributions by Christopher Wellons and revisions & suggestions by Martin K. as well as tuu and fizzie on ##c on Freenode.
Current version: 2.1
Dependencies:
- readline -
sudo apt install libreadline-devfor Debian &sudo pacman -S readlinefor Arch
$ git clone https://github.com/michaeldim02/houndsniff.git && cd houndsniff/src
$ sudo make install
houndsniff [HASH]
or, alternatively you can use the interactive shell:
houndsniff -i
You can exit with ^C.
You can also use scripting mode, which allows houndsniff to get hashes from stdin and print to stdout without much eye-candy:
echo "$hash" | houndsnif -s
Thanks a lot to tuu and fizzie, as well as kurahaupo on ##c @ freenode for their revisions and suggestions! (even though I've yet to implement everything). I truly appreciate the help.

More donation options on the website: mcdim.xyz
It is impossible to mathematically and algorithmically determine which specific algorithm produced a certain hash, and that's definitely not houndsniff is claiming to be able to do. A hash of a specific length and characterset could have been generated by a number of different hashing algorithms, and the hash itself doesn't give further information for one to determine whether or not it was produced by i.e MD5 or RIPEMD128, since both of these algorithms produce 128 bit hashes.
The only effective way to distinguish between two hashing algorithms that produce hashes of the same characteristics is through the popularity of each hashing algorithm. This is how the percentages are calculated.
The percentages are not arbitrary or random. They are hardcoded in the program in select.c, which may give the impression that they are random. This is not the case. They are determined through web search engine results. The numbers are combined into a sum which is then split accordingly into percentages. This process is done semi-automatically with the use a script.
So, generally, regarding the percentages:
- houndsniff is not meant to give the impression that the percentages are calculated in real time. The percentages are hardcoded into the program.
- Still, the percentages aren't random or arbitrary. I chose to hardcode them in because it would make the tool a lot lighter, easier to maintain, so that it wouldn't require an internet connection to run, and so that it wouldn't randomly bruteforce websites. Hash algorithm popularity does not change overnight, and if it did we would just update houndsniff, so there's no reason why the percentages should be calculated in real time, and not just hardcoded in.
- the percentages are truncated to 2 decimal digits, so they may not add up to 100 exactly.
- only known hashing algorithms are taken into consideration when calculated them.
- and lastly, the percentages are, of course, only as accurate as the web search engine results.