The music streaming company, Sparkify, wants to automate and monitor their data warehouse ETL pipelines using Apache Airflow. Our goal is to build high-grade data pipelines that are dynamic and built from reusable tasks, can be monitored and allow easy backfills. We also want to improve data quality by running tests against the dataset after the ETL steps are complete in order to catch any discrepancies.
The source data is in S3 and needs to be processed in Sparkify's data warehouse in Amazon Redshift. The source data are CSV logs containing user activity in the application and JSON metadata about the songs the users listen to.
We will create custom operators to perform tasks such as staging the data, filling the data warehouse and running checks. The tasks will need to be linked together to achieve a coherent and sensible data flow within the pipeline.
The log data is located at s3://udacity-dend/log_data and the song data is located in s3://udacity-dend/song_data.
- There are three major components of the project:
- Dag template with all imports and task templates.
- Operators folder with operator templates.
- Helper class with SQL transformations.
- Add
default parametersto the Dag template as follows:- Dag does not have dependencies on past runs
- On failure, tasks are retried 3 times
- Retries happen every 5 minutes
- Catchup is turned off
- Do not email on retry
- The task dependencies should generate the following graph view:
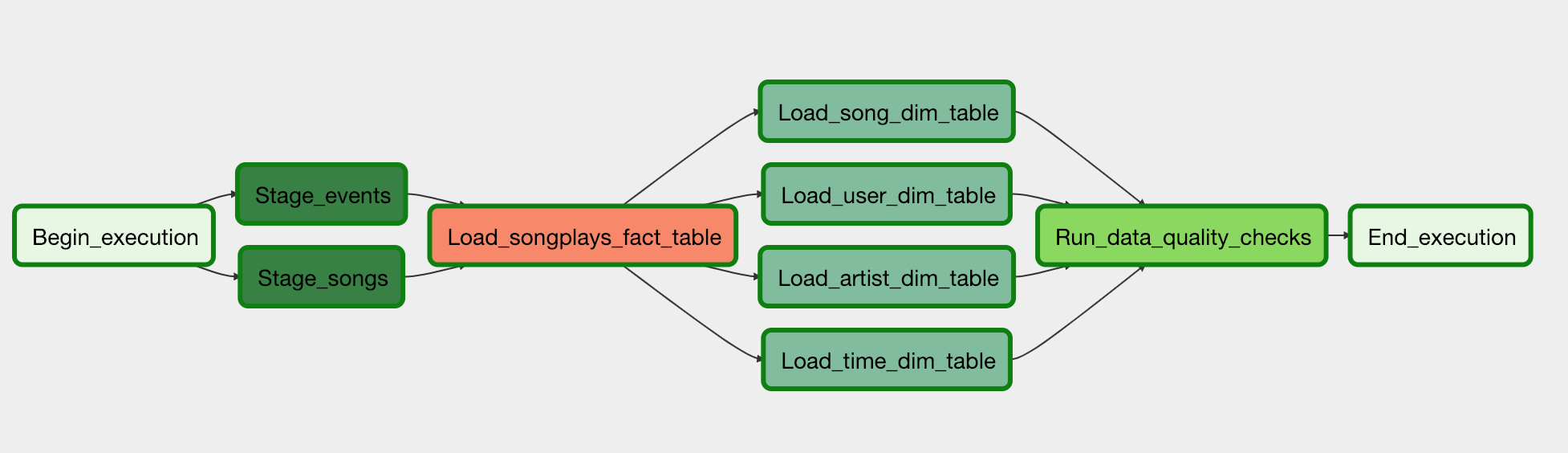
- There are four operators:

- Stage operator
- Loads JSON and CSV files from S3 to Amazon Redshift
- Creates and runs a
SQL COPYstatement based on the parameters provided - Parameters should specify where in S3 file resides and the target table
- Parameters should distinguish between JSON and CSV files
- Contain a templated field that allows it to load timestamped files from S3 based on the execution time and run backfills
- Fact and Dimension Operators
- Use SQL helper class to run data transformations
- Take as input a SQL statement and target database to run query against
- Define a target table that will contain results of the transformation
- Dimension loads are often done with truncate-insert pattern where target table is emptied before the load
- Fact tables are usually so massive that they should only allow append type functionality
- Data Quality Operator
- Run checks on the data
- Receives one or more SQL based test cases along with the expected results and executes the tests
- Test result and expected results are checked and if there is no match, operator should raise an exception and the task should retry and fail eventually
Run /opt/airflow.start.sh to start the Airflow server. Access the Airflow UI by clicking Access Airflow button. Note that Airflow can take up to 10 minutes to create the connection due to the size of the files in S3.