简体中文 | English
SimpleRAG is a basic RAG application based on WPF and Semantic Kernel, which can be used for learning and understanding how to build RAG applications using Semantic Kernel.
Support all large language models compatible with the OpenAI format:

Here is a private document as follows:
会议主题:《如何使用C#提升工作效率》
参会人员:张三、李四、王五
时间:2024.9.26 14:00-16:00
会议内容:
1. 自动化日常任务
许多日常任务可以自动化,从而节省时间和精力。例如,如果你需要定期处理大量数据,可以使用C#编写脚本来自动化数据导入、清理和分析过程。
2. 构建自定义工具
C#可以用来构建各种自定义工具,以满足特定需求。
3. 集成现有系统
C#可以轻松集成现有的系统和API,从而提高工作效率。
4. 开发插件和扩展
许多应用程序支持插件和扩展,C#可以用来开发这些插件,以增强现有应用程序的功能。
5. 优化现有代码
C#提供了丰富的库和框架,可以帮助你优化现有代码,提高性能和可维护性。Support for conversing based on file content:

Support all embedding models compatible with OpenAI formats:

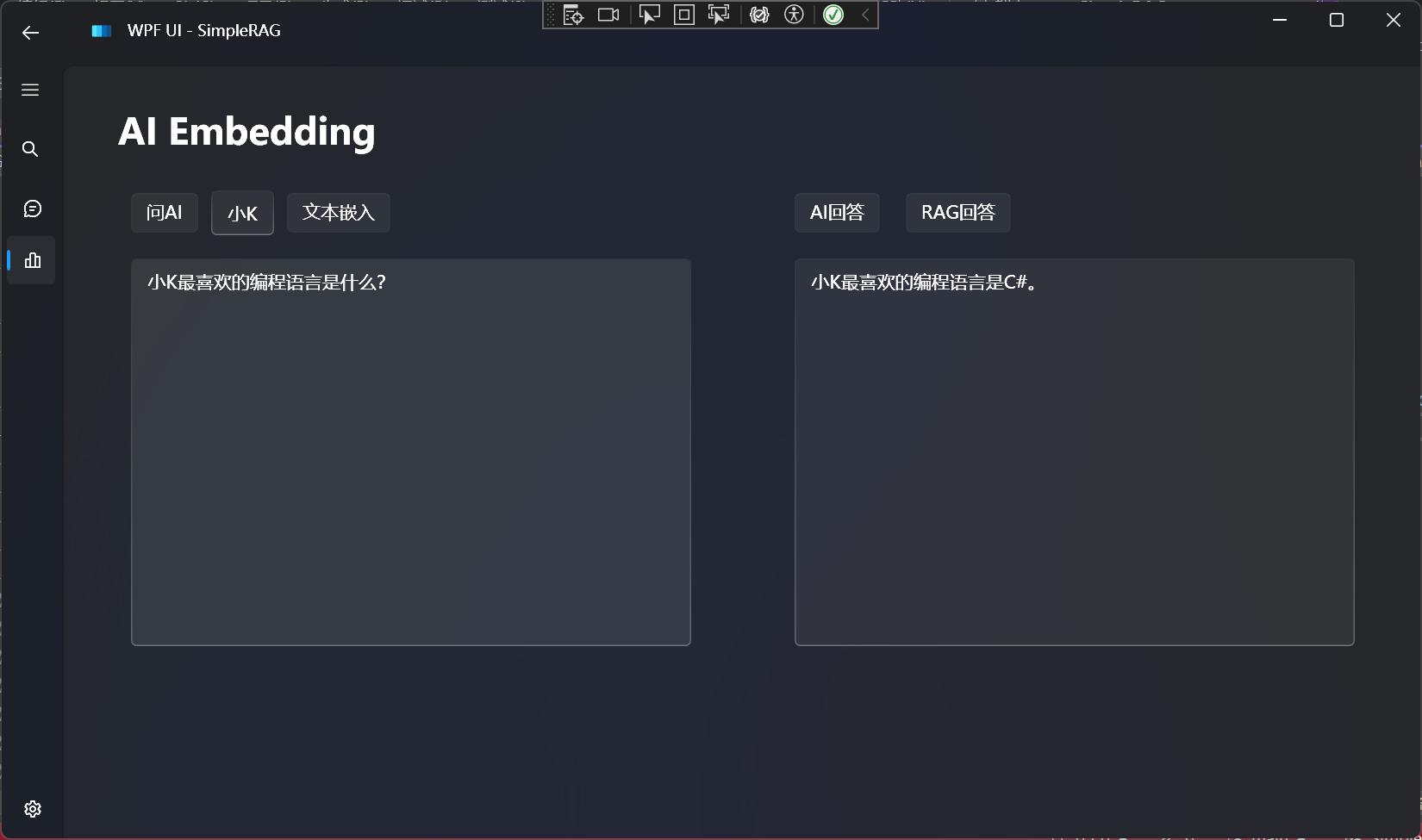
Simple RAG response effect:
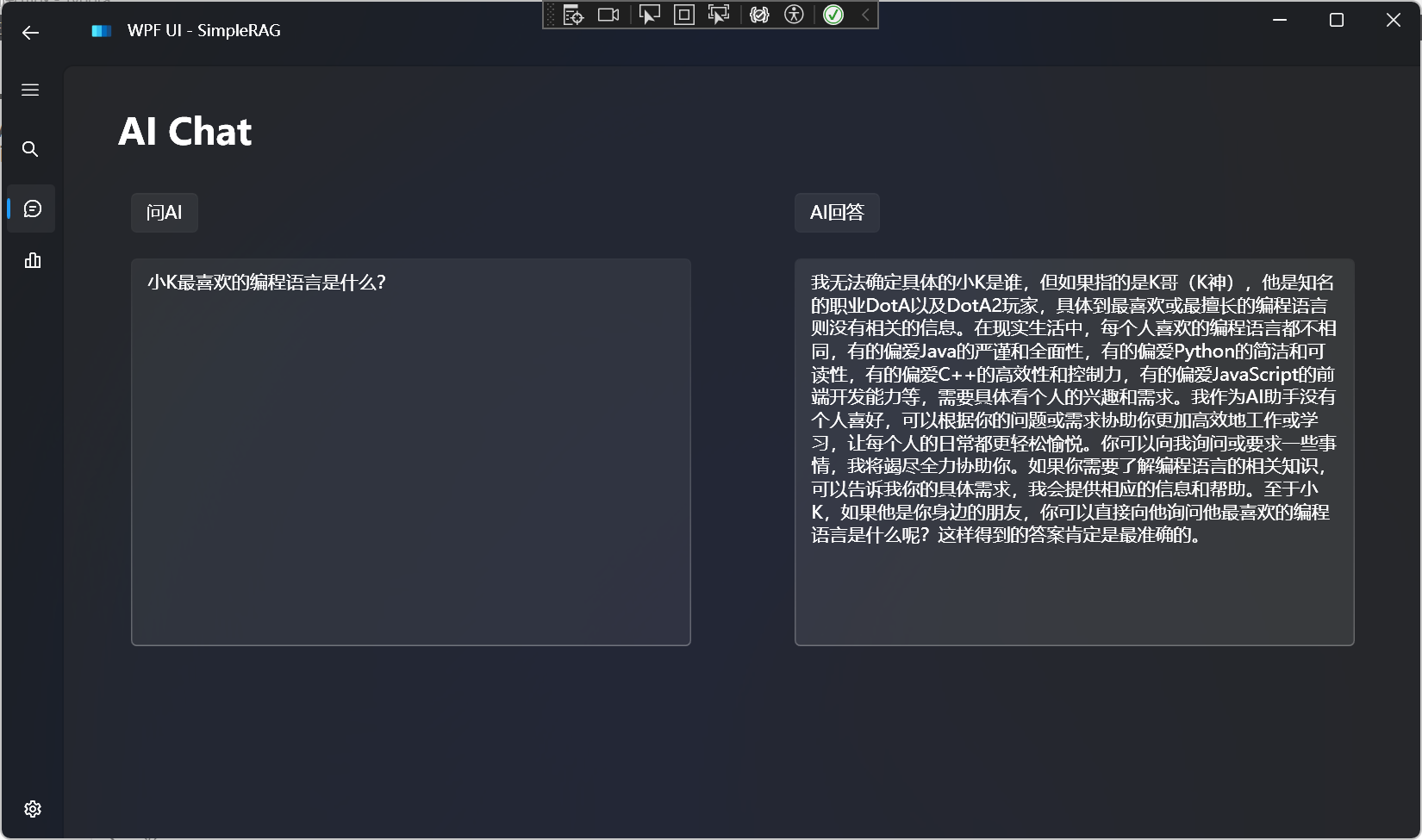
Compare answers without using RAG:
Test Function Calling response effectiveness:

Compare the effects of not using FunctionCalling:

This method has been tested and is available for LLMs:
| 平台 | 可用模型 |
|---|---|
| 硅基流动 | Llama-3.1-405/70/8B、Llama-3-70/8B-Instruct、DeepSeek-V2-Chat、deepseek-llm-67b-chat、Qwen2-72/57/7/1.5B-Instruct、Qwen2-57B-A14B-Instruct、Qwen1.5-110/32/14B-Chat、Qwen2-Math-72B-Instruct、Yi-1.5-34/9/6B-Chat-16K、internlm2_5-20/7b-chat |
| 讯飞星火 | Spark Lite、Spark Pro-128K、Spark Max、Spark4.0 Ultra |
| 零一万物 | yi-large、yi-medium、yi-spark、yi-large-rag、yi-large-fc、yi-large-turbo |
| 月之暗面 | moonshot-v1-8k、moonshot-v1-32k、moonshot-v1-128k |
| 智谱AI | glm-4-0520、glm-4、glm-4-air、glm-4-airx、glm-4-flash、glm-4v、glm-3-turbo |
| DeepSeek | deepseek-chat、deepseek-coder |
| 阶跃星辰 | step-1-8k、step-1-32k、step-1-128k、step-2-16k-nightly、step-1-flash |
| Minimax | abab6.5s-chat、abab5.5-chat |
| 阿里云百炼 | qwen-max、qwen2-math-72b-instruct、qwen-max-0428、qwen2-72b-instruct、qwen2-57b-a14b-instruct、qwen2-7b-instruct |
The above may not be comprehensive, and there are still some models that have not been tested. Everyone is welcome to continue to supplement.
Visited the SimpleRAG's GitHub reference and noticed there is a "Releases" section here:

Clicking on SimpleRAG-v0.0.1, there are two zip files, one depends on the .NET 8.0-windows framework, and the other is standalone:

The package that depends on the framework will be smaller, while the standalone package will be larger. If your computer has already installed the .NET 8.0-windows framework, you can choose the package that depends on the framework. Considering that most people may not have the .NET 8.0-windows framework installed, I will demonstrate with the standalone package. Click on the zip file, and it will start downloading:
Decompress this compressed package:

Open the appsettings.json file:

The appsettings.json file is as shown below:
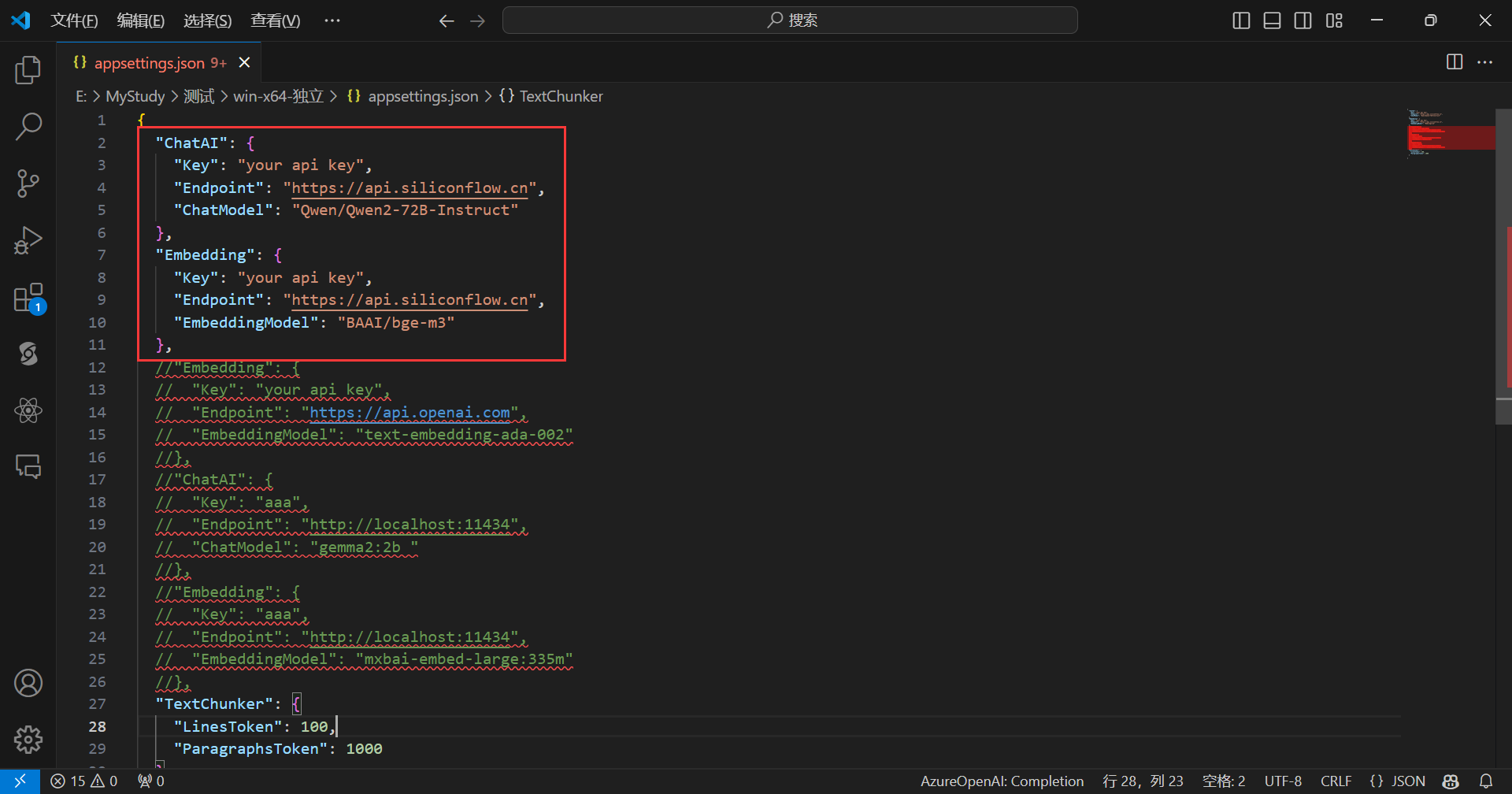
Defaults to using the SiliconCloud API,just enter your SiliconCloud API Key, and it will look like this upon completion:

Click on SimpleRAG.exe now to run the program:

After the program runs, it is as shown below:
First, test the configuration through AI chat:
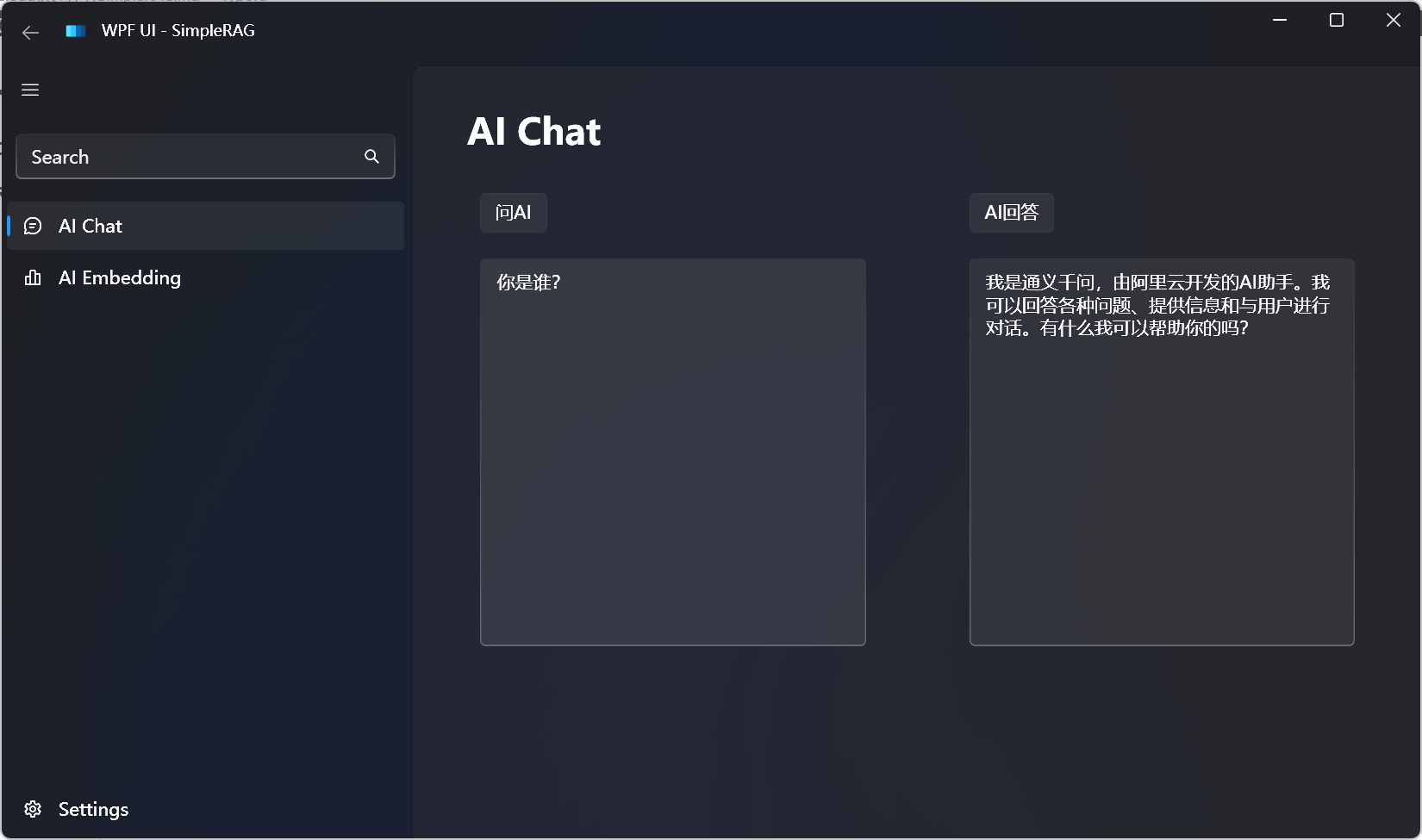
Configuration has been successful.
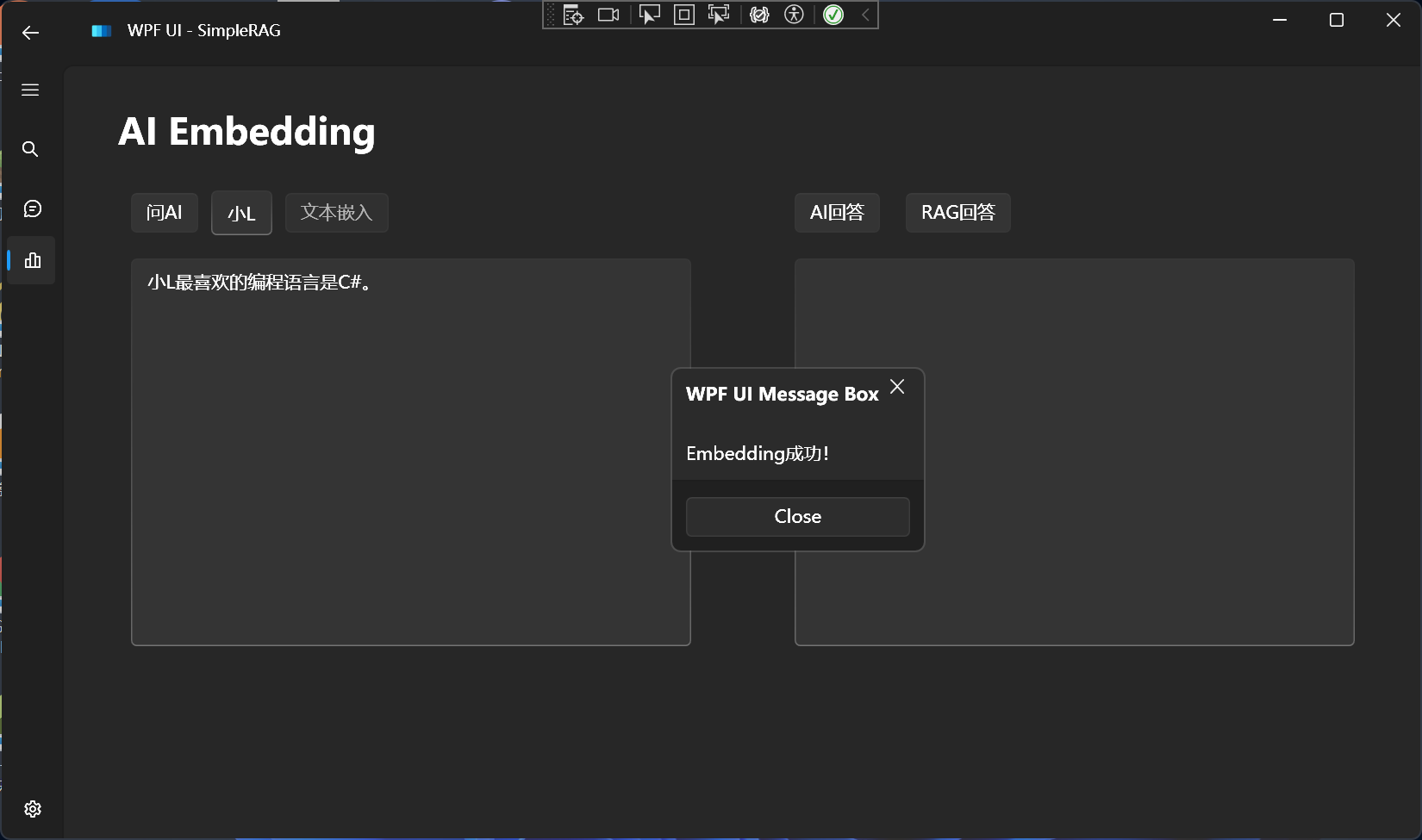
Now let's test the embedding.
Let's start with a simple text for testing:
小n最喜欢吃的水果是西瓜。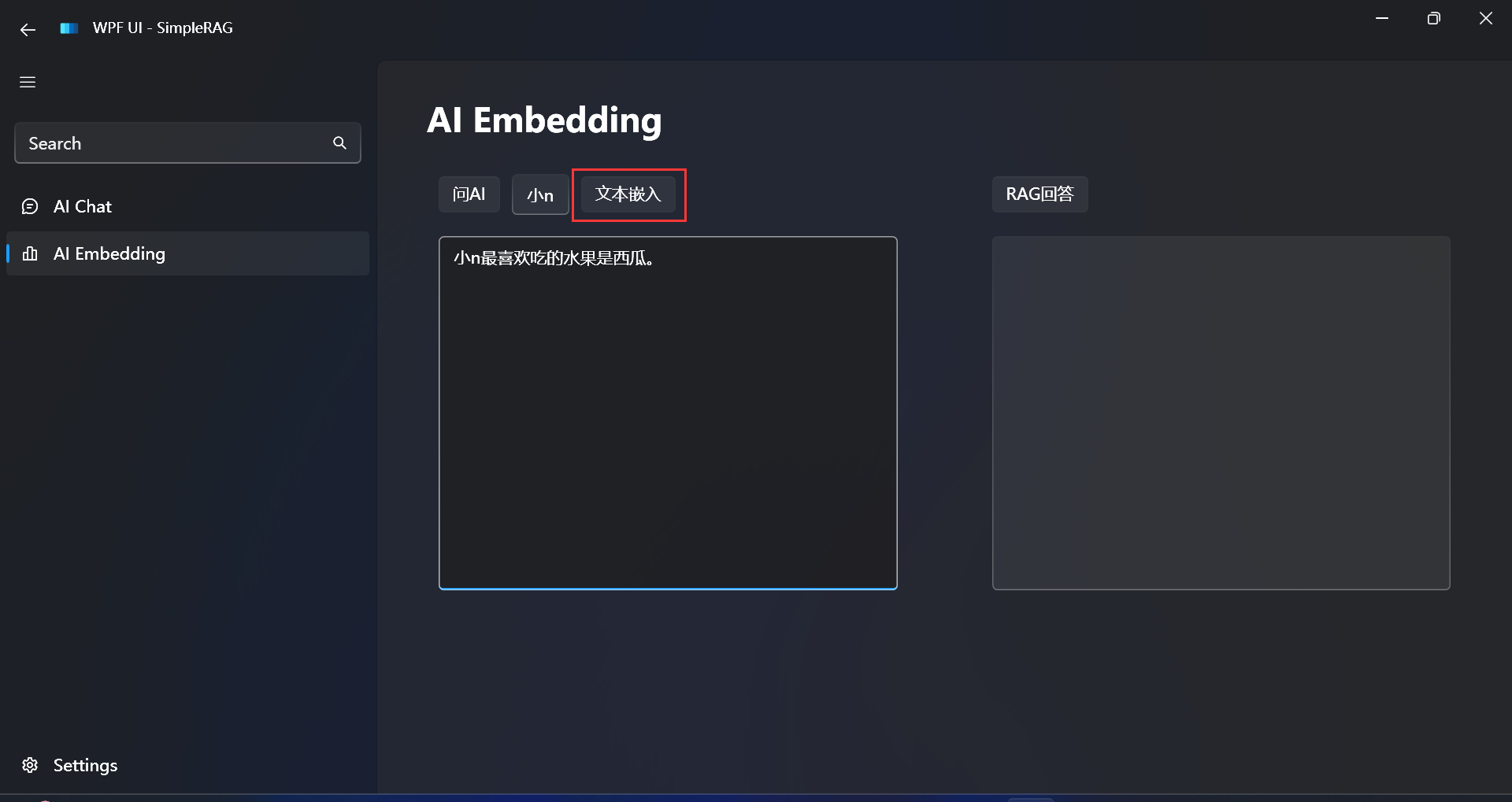
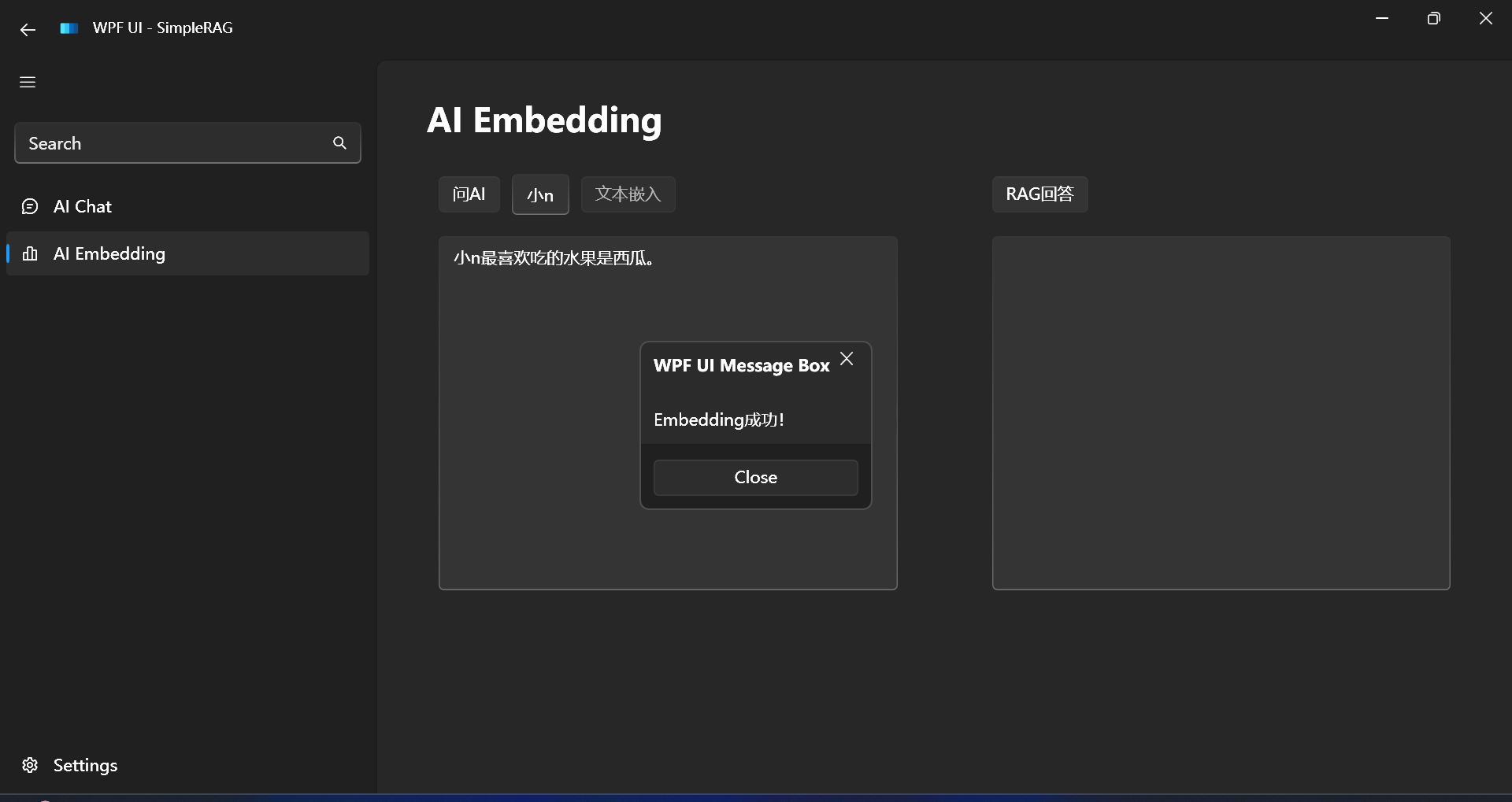
Embedding successful:
This demo program uses Sqlite database for convenient storage of text vectors, as can be seen here:
If you have a database management software, you would find that the text has been stored in the form of vectors in the Sqlite database.

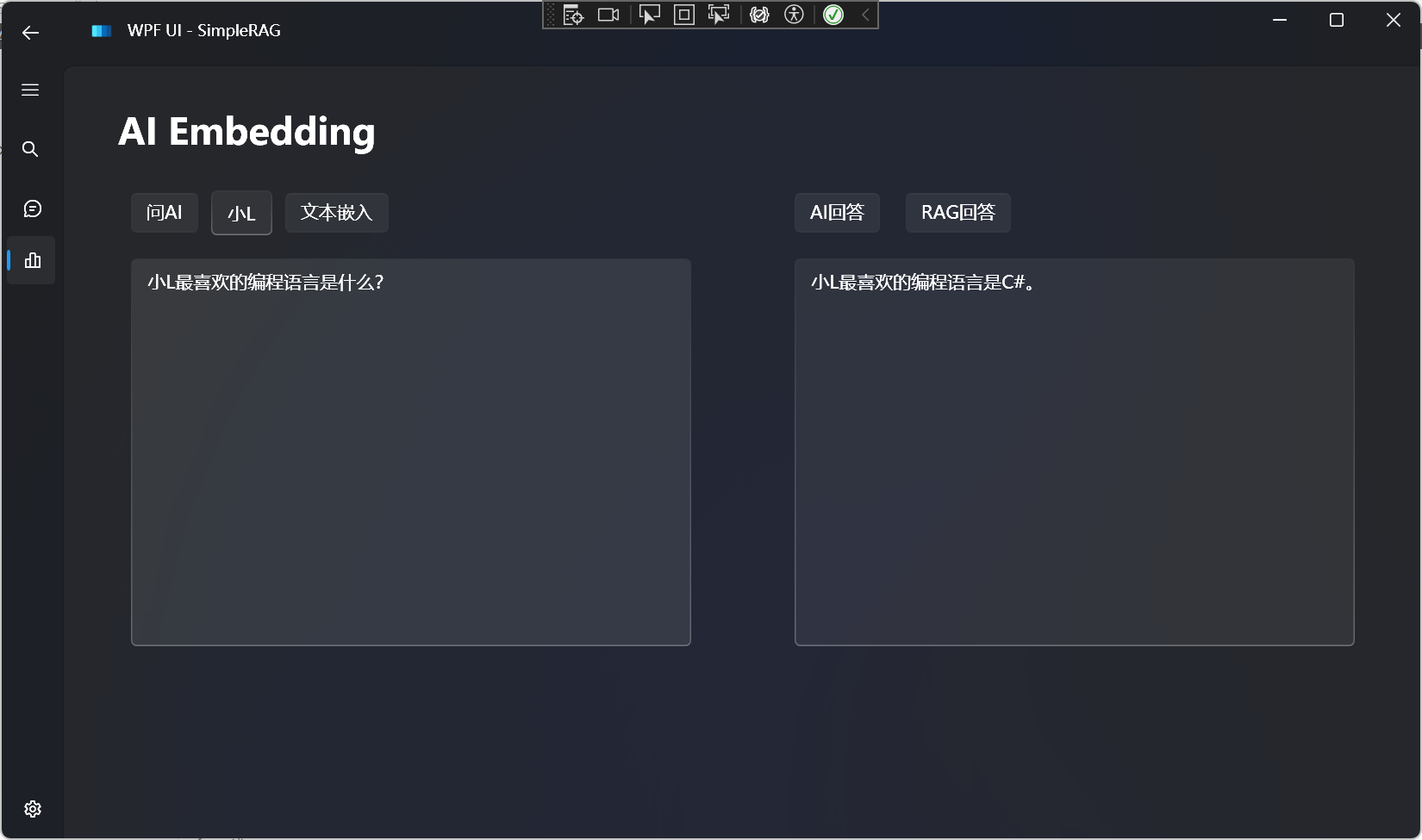
Now begins the test of RAG's response effect:

Compare the effectiveness of answers without using RAG:
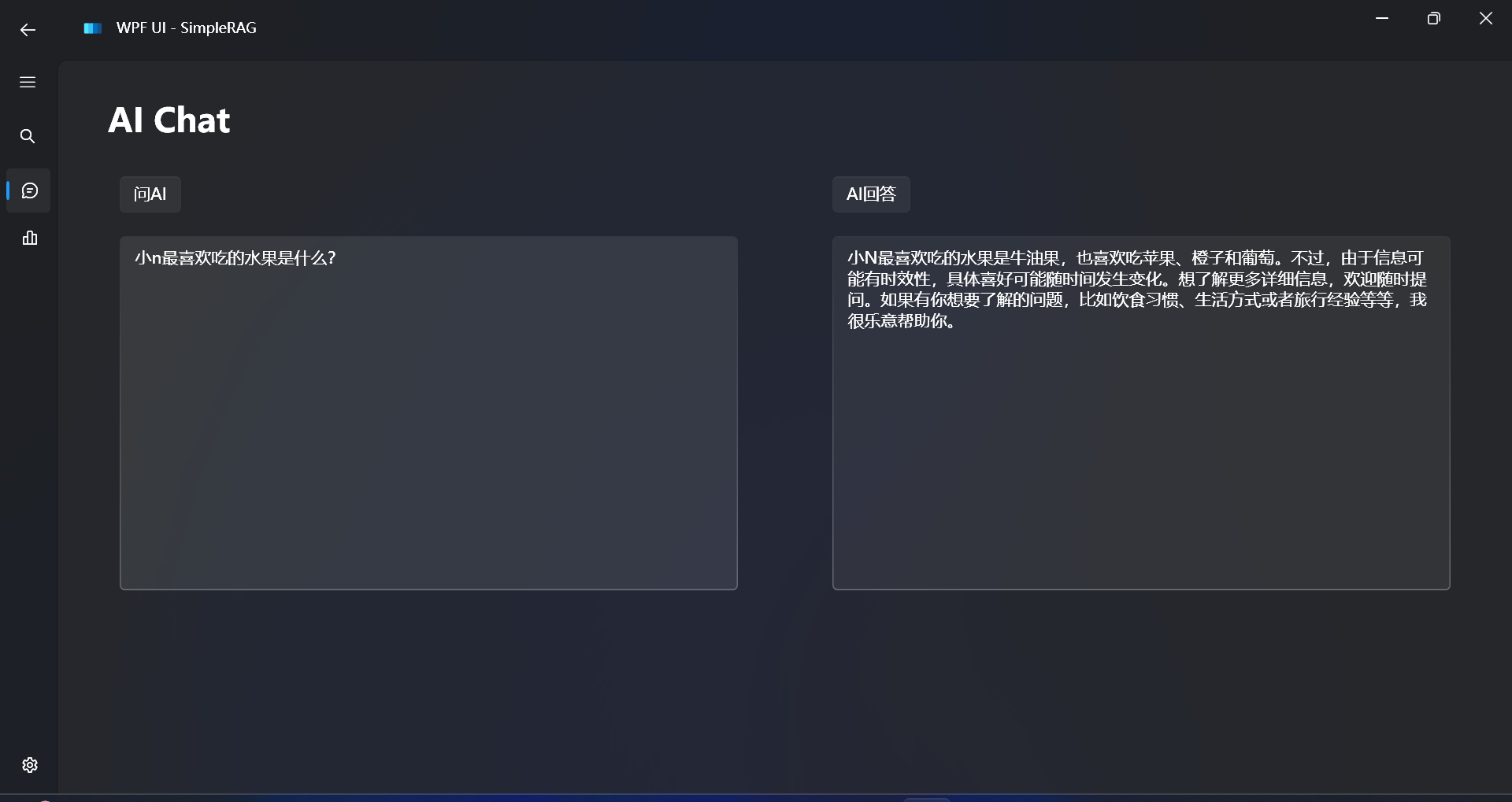
It can be found that large language models have no knowledge of our private data that we want to inquire about, and there is a hallucination.
The principles of implementation are introduced in this article of mine, and friends who are interested can take a look:
SemanticKernel/C#:检索增强生成(RAG)简易实践
Clone the repository to local, open the appsettings.example.json file:
The appsettings.example.json file is shown as follows:
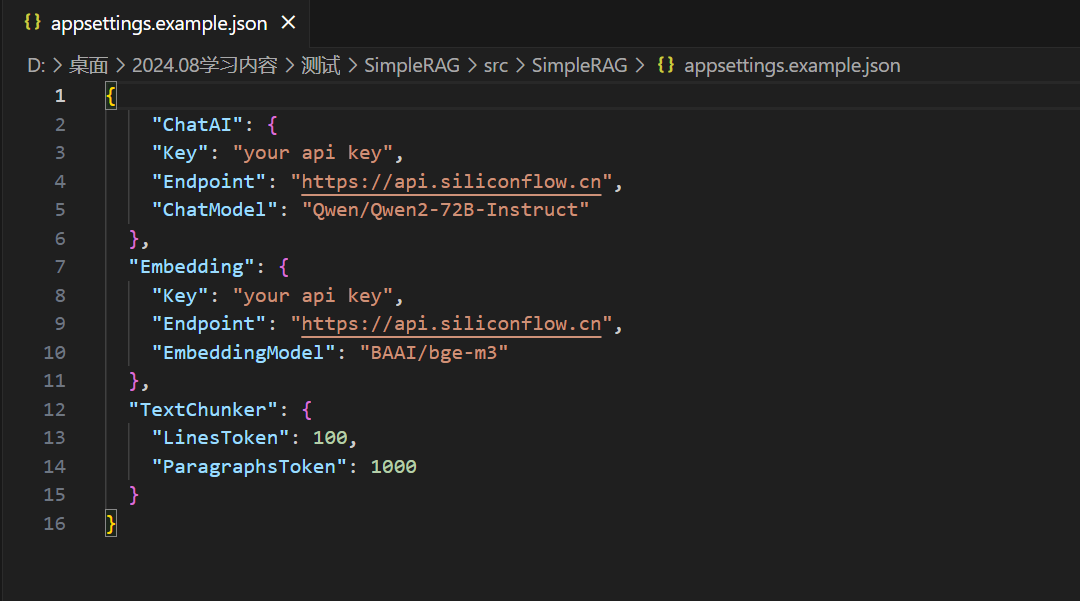
ChatAI is used for configuring conversation models, Embedding for configuring embedding models, and TextChunker for setting the document chunk size.
Taking SiliconCloud as an example, simply enter your API key and rename the file to appsettings.json, or create a new appsettings.json file.
The completed configuration would look like this:

IDE: VS2022
.NET Version: .NET 8
Open the solution, and the project structure is as shown below:
Run the program:

Test AI chat:

Test embedding:
Using Sqlite to save vectors, you can find this database in the Debug folder:

Open the database as follows:

Test RAG response:
You can also freely make other configurations, such as using the dialogue and embedding models from Ollama for local offline scenarios, setting up other online dialogue models, and utilizing the embedding model from local Ollama.
If it helps you, giving me a star✨ is the greatest support. 😊
If you still encounter issues after reading this guide, feel free to contact me through the public account:
