当图片存在不同的尺度(scales)以及旋转(rotations)时,简单的corner detector无法取得很好的效果,这时我们就需要使用Scale Invariant Feature Transform。当然,SIFT特征不仅仅是scale invariant,同样一张图片,如果改变以下一些特征仍能取得很好的结果:
- 尺度(Scale)
- 旋转(Rotation)
- 亮度(Illumination)
- 视角(Viewpoint) 例如,假设我们需要在下图中识别出图1所示的物体(object),尽管图1中物体的视角和尺度和目标图中对应物体的不同,使用SIFT特征仍能准确的定位出该物体

 图一
图一
在现实世界中,物体往往只在某个特定的尺度(准确来说,是清晰度,或者分辨率)下才能被准确的识别出,例如你也许可以看见在桌子上有一块方糖,但是如果画面十分模糊,你是无法看到方糖的。
如果你需要识别的物体是一棵树,那么你就不需要识别出树上的叶子这些details。去除这些不必要的细节常用的手段就是是图片模糊化(blur),为了在模糊的过程中不引入新的false details,一般使用Gaussian Blur。 创建一个scale space的方法是将原始输入图片不断的模糊化,下图就是一个例子:

在SIFT中,生成scale spaces除了对原始的输入图片做递进的模糊操作以外,我们还会将原始的输入图片做Resize操作,使其大小为原图的一半,然后对resize过后的图片再次进行模糊化操作,以此类推。

由上图可见,同一列的图片是相同size的,它们共同组成了一个octave,上图共有4个octaves,每一个octave包含了5张图片,每张图片具有不同的scale (the amount of blur)。
- Octave and Scales Octaves和scales的数量取决于原始图片的大小,一般需要由用户自己定义这个数量,但是,SIFT的创造者建议使用4个Octaves和5个blur levels。
- The first octave 如果将原始的输入图片尺寸扩大一倍并且做抗锯齿操作(by blurring it),那么算法生成的keypoints将会是原来的四倍以上。Keypoints越多,算法的性能越好!
- Blurring 从数学的角度来说,Blurring是指对图像中的像素做卷积操作,Gaussian blur的数学表达式为:
公式中的符号含义:
* L代表模糊后的图片
* G代表高斯滤波器
* I代表原始输入图片
* x, y是像素点坐标
* 是scale parameter.可以把它当做是模糊的程度,值越大,越模糊
* *代表卷积操作
- Amount of blurring
假设在某个特定的图片中模糊程度为
,那么,下一张图的模糊程度就是k*
在这一部分,我们将使用前面生成的模糊后的图片去生成另一组图片:the Difference of Gaussians(DoG).这些DoG图片对发现图像中有益的key points十分有帮助。
The Laplacian of Gaussian operation的操作步骤是:先将原始图片通过高斯滤波器模糊化,然后计算图像的second order derivatives(也称作laplacian)。这步操作可以帮助定位到图中的边(edges)和角(corners),这些边和角可以帮助发现图中的关键点信息。
但是,二阶导对于噪声十分敏感,因此需要在求二阶导之前对图像做降噪(模糊)处理,从而使得二阶导的求解更加的稳定。
问题在于,计算图像中所有像素位置的二阶导十分的computationally expensive,因此我们需要一条捷径。
为了快速的生成LoG图像,我们使用到了scale space。我们计算两个连续scales之间的差值,或者说,the Difference of Gaussians,如图所示:

这些DoG图片可近似等于the Laplacian of Gaussian,我们通过这样的方式将一个计算量十分庞大的过程化简成了一个简单的相减操作,大大提升了效率。
仅仅是Laplacian of Gaussian图像还不够,因为它们并不是scale invariant的,也就是说它们取决于你对图像的模糊化程度,即的值
找到关键点分为两个步骤:
- Locate maxima/minima in DoG images
- Find subpixel maxima/minima
第一步是粗略的定位极大值和极小值,这一步很简单,只需要遍历图中的每个像素点,并将当前遍历的像素点与其邻接区域的像素点比较
 X表示当前像素点,绿色的圈表示邻接点像素点,这样的话,对当前像素点,一共需要进行26次比较。
X表示当前像素点,绿色的圈表示邻接点像素点,这样的话,对当前像素点,一共需要进行26次比较。
如果X位置像素点的值比其余26个像素点的值都大,或者都小,那么X就会被标记为"key point"
需要注意的是我们不会再lowermost和topmost scales中检测keypoints,因为我们没有足够的邻接点来进行检测工作,所以直接跳过这些scales上的像素点即可。 这一步完成之后,我们找到了”近似的“极大值点和极小值点,说它们是近似的,是因为真正的极大/小值点几乎不会落在某个具体的像素点上,它往往是落在像素点之间,但是我们没有办法获取像素点之间的数据。因此,我们必须通过数学计算的方法来定位这些subpixel location。
![]()
图中绿色的叉才是真正的极值点。
使用已有的像素值,subpixel的值可以被生成,方法是使用the Taylor expansion of the image around the approximate key point

我们可以通过上面的泰勒展开式轻松的求解出该式的极值点(differentiate and eqaute to zero)
通过上一步可以生成许多的关键点,这些关键点中有一些会落在edge上,或者说它们并不具备足够的对比度(contrast)。在这种情况下,它们就不适合作为特征(features)。
去除操作很简单,我们事先设定好一个阈值,如果在DoG图像中,当前像素点的值小于阈值,就去除。
方案是计算在keypoint处的两个相互垂直方向上的梯度(gradient),基于keypoint点周围的图像,存在三种不同的情况:
- 平摊区域(A flat region):两个计算出来的梯度都很小
- 边(An edge):其中一个梯度比较大(垂直于边的方向),另一个梯度比较小(沿着边的方向)
- 角落(A corner):两个梯度都很大
Corners是很好的keypoints。所以我们只想要corners。如果两个gradients都足够大,我们就标记该候选点为key point,否则的话,拒绝。
数学上,我们通常使用Hessian Matrix来实现这一目的。
在获取了质量较高的keypoint之后,我们需要赋予每个keypoint方向(orientations),方向的赋予使得keypoint具备rotation invariant特性。

梯度值和方向可以通过如下公式来计算得到:

在计算得到关键点周围所有像素点的梯度方向和大小后,生成直方图。由于梯度方向有360度,我们可以分成36个bin,每个bin代表10度。

上图所示关键点的方向就是3(20-29度)
Note: 扫描窗口的大小等于高斯滤波器的窗口大小
R-CNN的全称是Region-based Convolutional Neural Networks,该算法主要包含了两个步骤,首先,第一个步骤是做selective search,它的作用是从原始的输入图像中提取出一些我们感兴趣的的"区域",所谓感兴趣,就是"区域"中有可能包含我们需要识别/定位的object。这些我们感兴趣的"区域"有一个专有名词:Region of Interest,一般简写为RoI。接下来,第二个步骤就是从这些感兴趣的"区域"中通过CNN提取出特征用以后续的分类工作。
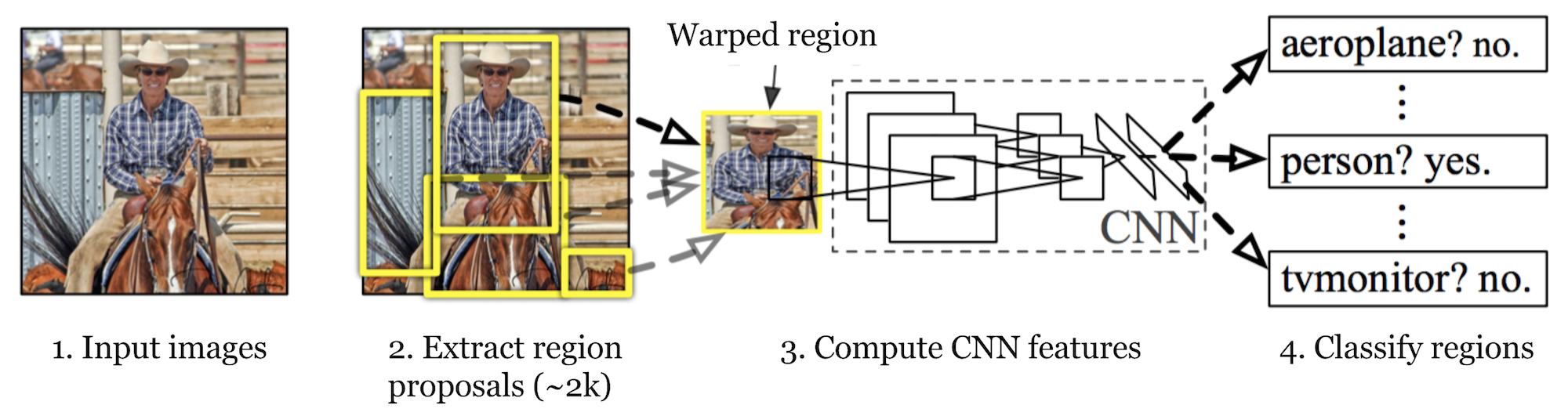

R-CNN的工作步骤可以被概括为以下几点:
- 预训练一个用来做图像分类的卷积神经网络,例如:VGG或者ResNet。
- 针对不同的图像类别,独立地生成RoI,每张原始输入图像生成大约2000个候选区域即可。这些候选区域有可能包含了目标物体,并且它们一般都具有不同的size。
- 候选区域通过warp操作转换成固定的size,这样一来它们就能被用作CNN的输入。
- 使用warped过的候选区域继续fine-tune我们的CNN网络,这时我们模型的输出一共有K+1类,多出来的1类代表的是背景(background),即不包含任何我们需要识别的物体。在fine-tuning阶段,我们需要使用更小的learning rate,并且,每一个mini-batch都需要对正样本进行过采样,因为大多数候选区域都是background。
- 给定任何一个图像区域,经过一次forward propagation就会生成一个特征向量。这个特征向量将被用作二分类SVM的输入。每一个类(class)都有对应的一个binary SVM。分类的正样本是那些**IoU (intersection over union)**重叠率大于等于0.3的样本,不满足这一条件的是负样本。
- 为了减小定位误差,我们还需要训练一个回归模型来矫正预测的bounding box的位置。



假设预测的bounding box坐标为:,式中前两个元素代表定位框的中心点坐标,后面两个元素分别代表定位框的宽度和高度,实际的bounding box坐标为:
,回归器(regressor)被设置为学习scale-invariant transformation between two centers,以及log-scale transformation between widths and heights。所有transformation functions都以p为输入。
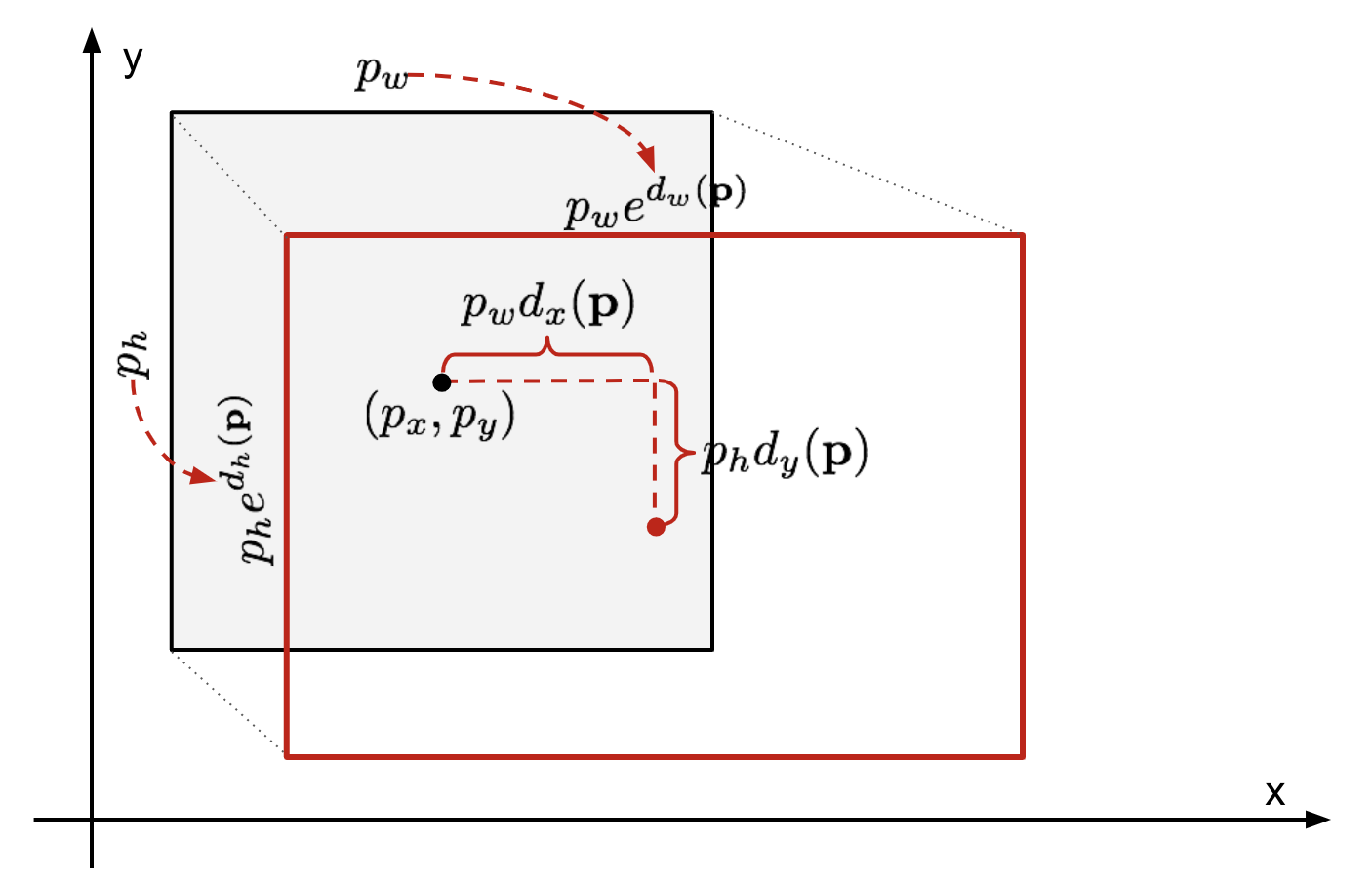
应用以上变换的一个显著的好处在于,所有的定位框矫正方程,
,
,可以接受实数范围内的任意值作为输入。它们的学习目标是:
一个标准的回归模型可以通过最小化SSE误差来优化求解:
这里的正则化项十分的重要,在原始的R-CNN论文中作者通过cross-validation的方法来挑选最优的lambda取值。需要值得注意的是,不是所有预测的定位框都有对应的ground truth定位框。例如,如果我们选择的区域与目标物没有任何重叠,那么我们其实就没必要去运行bbox回归模型。在这里,只有选定区域与最近的ground truth定位框重叠区域(IoU)大于等于0.6时,预测定位框才会被用来训练bbox回归模型。
以下是一些经常被用在R-CNN和其他一些鉴别模型中的小技巧。
对于同一个物体,有很大的可能我们的模型会找到多个可能的定位框。Non-maximum Suppression帮助我们的模型不会重复检测同一个目标物体。具体的实现方法为:当我们得到一系列对同一目标物体的匹配的定位框以后,首先根据他们的confidence score进行排序,舍弃那些低置信度的定位框。如果还有剩余的定位框,重复以下操作:贪婪地选取置信度最高的定位框,舍弃那些与先前选取的定位框重叠率(IoU)大于0.5的定位框。

我们认为不包含目标物体的定位框为负样本。不是所有的负样本都一样难被识别出来。例如,如果某个区域全是背景,那么它很容易就可以别识别出是负样本,但是如果定位框中包含一些奇奇怪怪的噪声纹理,或者包含了一部分object,那么它们就比较难被识别出是负样本,"hard negative"。
那些hard negative examples很容易就被误分类。因此,我们在训练时就显式(explicitly)找出那些false positive样本,并将它们包含进训练数据以提升分类器的精度。
纵观R-CNN的学习步骤,我们可以轻易的发现训练一个R-CNN模型是十分耗时的,因为以下几个步骤包含了大量的计算和处理工作:
- 对每一张输入图像,运行selective search来提出2000个候选区域
- 对每一个候选区域生成CNN特征向量 (N images * 2000)
- 整个过程包含了三个独立的模型,并且模型之间没有太多可以共享的计算:1. 用以图像分类和特征提取的卷积神经网络;2. 位于顶层的SVM分类器,来识别目标object;3. 用于估计定位框的回归模型。
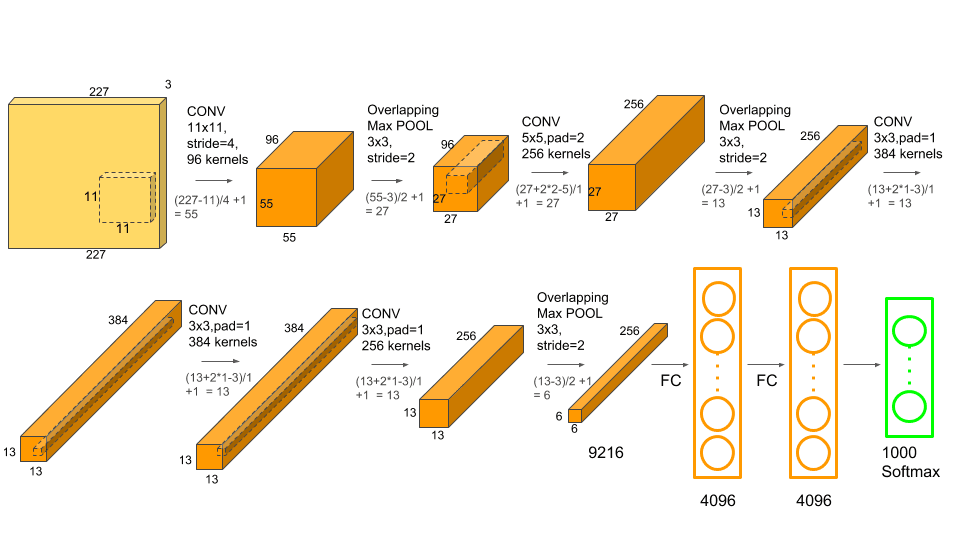
**模型结构:**5*卷积层+3*全连接层
Some of highlights:
- AlexNet使用了ReLU作为激活函数,而非sigmoid或tanh,从而提升了模型的收敛速率
- AlexNet使用了Dropout来防止overfitting,这一操作比使用正则化项的训练速率慢
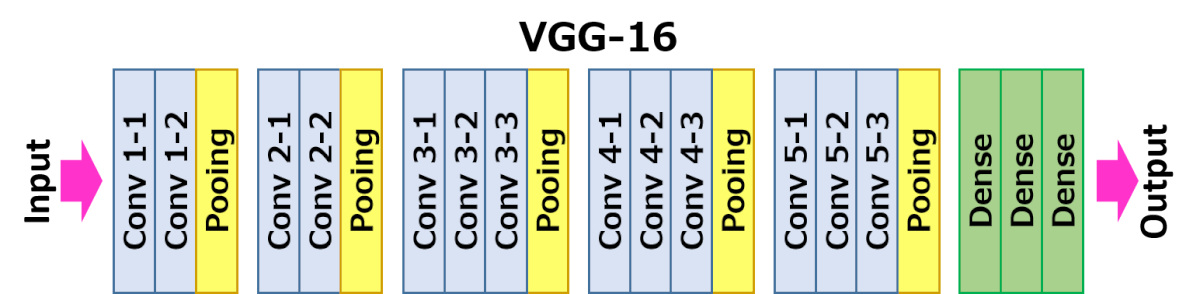
**模型结构:**16*conv layers + 3*FC layers
它相较于AlexNet的改善在于将大尺寸的滤波模板替换成了3*3的小尺寸滤波模板,从而简化了模型。
弊端:
- 训练慢
- 模型权重多,使得部署一个VGG-net十分的麻烦,你需要考虑到磁盘空间、带宽等因素。