
adept is a reinforcement learning framework designed to accelerate research by abstracting away engineering challenges associated with deep reinforcement learning. adept provides:
- multi-GPU training
- a modular interface for using custom networks, agents, and environments
- baseline reinforcement learning models and algorithms for PyTorch
- built-in tensorboard logging, model saving, reloading, evaluation, and rendering
- proven hyperparameter defaults
This code is early-access, expect rough edges. Interfaces subject to change. We're happy to accept feedback and contributions.
- Architecture Overview
- ModularNetwork Overview
- Resume training
- Evaluate a model
- Render environment
- Custom Network (stub | example)
- Custom SubModule (stub | example)
- Custom Agent (stub | example)
- Custom Environment (stub | example)
git clone https://github.com/heronsystems/adeptRL
cd adeptRL
pip install .From docker:
Train an Agent
Logs go to /tmp/adept_logs/ by default. The log directory contains the
tensorboard file, saved models, and other metadata.
# Local Mode (A2C)
# We recommend 4GB+ GPU memory, 8GB+ RAM, 4+ Cores
python -m adept.app local --env BeamRiderNoFrameskip-v4
# Distributed Mode (A2C, requires NCCL)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app distrib --env BeamRiderNoFrameskip-v4
# IMPALA (requires ray, resource intensive)
# We recommend 2+ GPUs, 8GB+ GPU memory, 32GB+ RAM, 4+ Cores
python -m adept.app actorlearner --env BeamRiderNoFrameskip-v4
# To see a full list of options:
python -m adept.app -h
python -m adept.app help <command>Use your own Agent, Environment, Network, or SubModule
"""
my_script.py
Train an agent on a single GPU.
"""
from adept.scripts.local import parse_args, main
from adept.network import NetworkModule, SubModule1D
from adept.agent import AgentModule
from adept.env import EnvModule
class MyAgent(AgentModule):
pass # Implement
class MyEnv(EnvModule):
pass # Implement
class MyNet(NetworkModule):
pass # Implement
class MySubModule1D(SubModule1D):
pass # Implement
if __name__ == '__main__':
import adept
adept.register_agent(MyAgent)
adept.register_env(MyEnv)
adept.register_network(MyNet)
adept.register_submodule(MySubModule1D)
main(parse_args())- Call your script like this:
python my_script.py --agent MyAgent --env env-id-1 --custom-network MyNet - You can see all the args here or how to implement the stubs in the examples section above.
Local (Single-node, Single-GPU)
- Best place to start if you're trying to understand code.
Distributed (Multi-node, Multi-GPU)
- Uses NCCL backend to all-reduce gradients across GPUs without a parameter server or host process.
- Supports NVLINK and InfiniBand to reduce communication overhead
- InfiniBand untested since we do not have a setup to test on.
Importance Weighted Actor Learner Architectures, IMPALA (Single Node, Multi-GPU)
- Our implementation uses GPU workers rather than CPU workers for forward passes.
- On Atari we achieve ~4k SPS = ~16k FPS with two GPUs and an 8-core CPU.
- "Note that the shallow IMPALA experiment completes training over 200 million frames in less than one hour."
- IMPALA official experiments use 48 cores.
- Ours: 2000 frame / (second * # CPU core) DeepMind: 1157 frame / (second * # CPU core)
- Does not yet support multiple nodes or direct GPU memory transfers.
- Modular Network Interface: supports arbitrary input and output shapes up to 4D via a SubModule API.
- Stateful networks (ie. LSTMs)
- Batch normalization (paper)
- OpenAI Gym Atari
- ~ 3,000 Steps/second = 12,000 FPS (Atari)
- Local Mode
- 64 environments
- GeForce 2080 Ti
- Ryzen 2700x 8-core
- Used to win a
Doom competition
(Ben Bell / Marv2in)
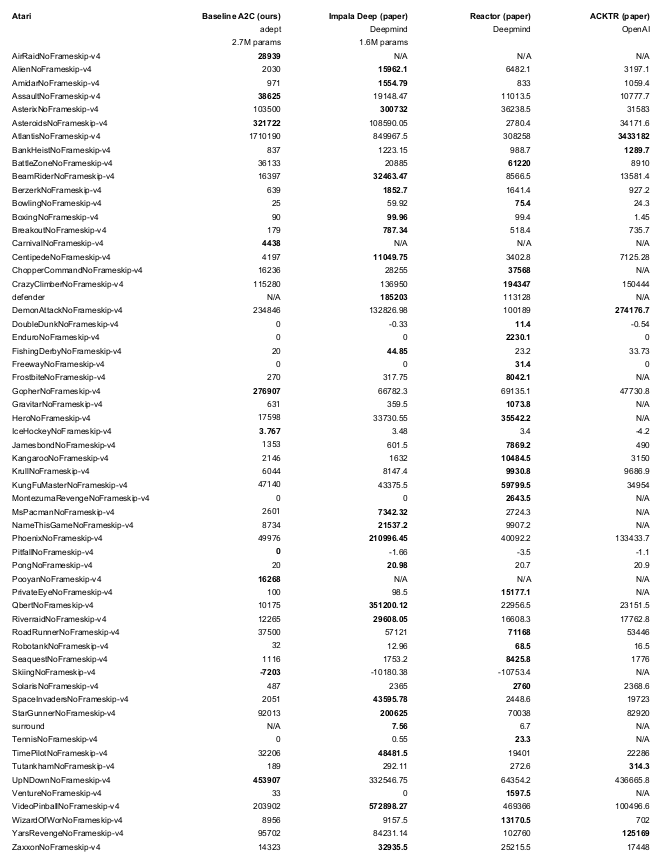
- Trained for 50M Steps / 200M Frames
- Up to 30 no-ops at start of each episode
- Evaluated on different seeds than trained on
- Architecture: Four Convs (F=32) followed by an LSTM (F=512)
- Reproduce with
python -m adept.app local --logdir ~/local64_benchmark --eval -y --nb-step 50e6 --env <env-id>

We borrow pieces of OpenAI's gym and baselines code. We indicate where this is done.