Joker_Xu_song
准备工作
环境准备
- python2.7 + Mac/windws + 相关包(爬虫、数据分析、结巴、词云等) + pycharm
- 建议安装anaconda下载地址
- pycharm 中也有相关包管理工具
| 包名 | 用途 | 备注 |
|---|---|---|
| requests | 发送网络请求 | 介绍地址地址 |
| re | 正则匹配 | 无 |
| json | json对象 | 是一种轻量级的数据交换格式,易于人阅读和编写 |
| BeautifulSoup | 网页抓取数据 | 无 |
| snownlp | 文本情感分析使用 | 分析情感的 |
| pyecharts | 数据可视化 | 无 |
| matplotlib | Python 的 2D绘图库 | 无 |
| jieba | 分词 | 无 |
分析网易云音乐
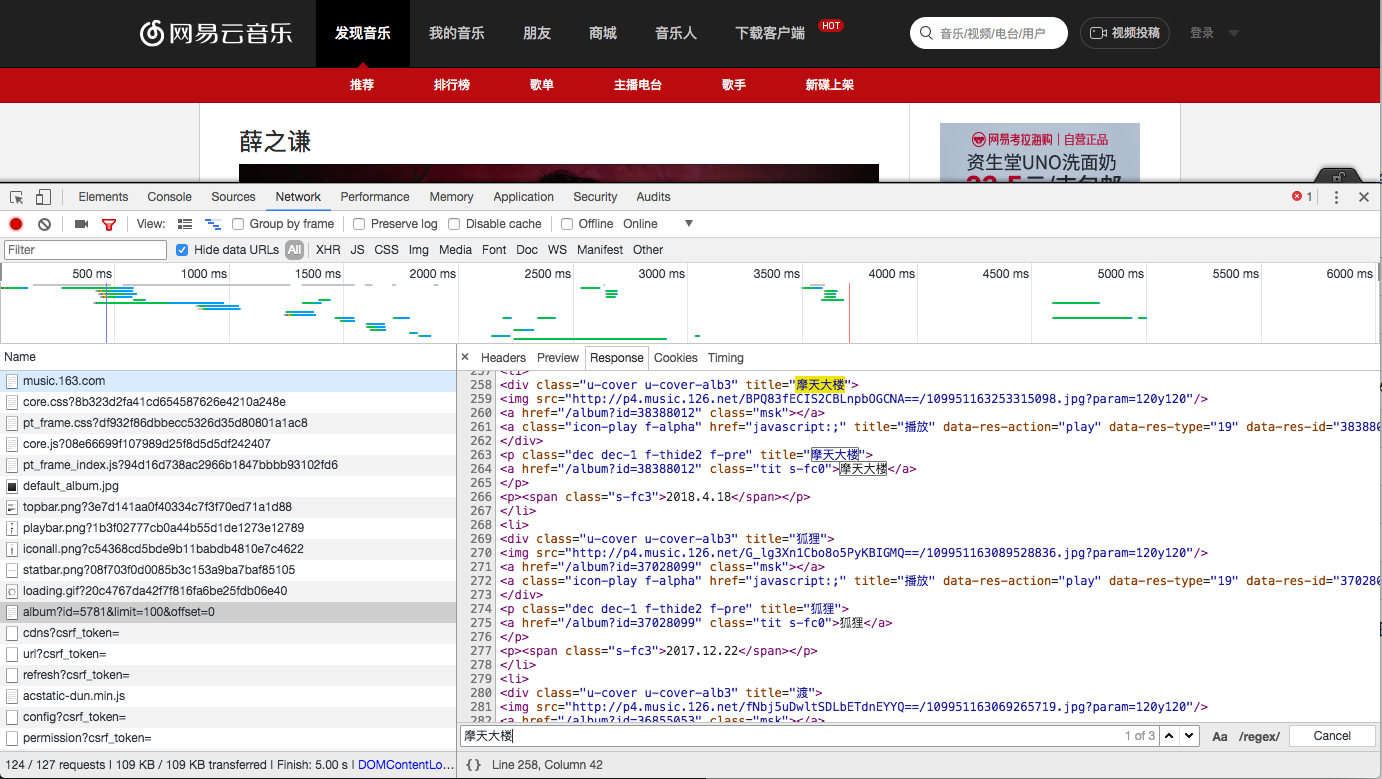
分析找到专辑名对应的div标签
把相关专辑信息写入文件中
def get_joker_album_info(art_id):
"""
得到专辑信息
:param art_id:
:return:
"""
urls = "http://music.163.com/artist/album?id={}&limit=100&offset=0".format(art_id)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '_iuqxldmzr_=32; _ntes_nnid=dc7dbed33626ab3af002944fabe23bc4,1524151830800; _ntes_nuid=dc7dbed33626ab3af002944fabe23bc4; __utmc=94650624; __utmz=94650624.1524151831.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=94650624.1505452853.1524151831.1524151831.1524176140.2; WM_TID=RpKJQQ90pzUSYfuSWgFDY6QEK1Gb4Ulg; JSESSIONID-WYYY=ZBmSOShrk4UKH5K%5CVasEPuc0b%2Fq6m5eAE91jWCmD6UpdB2y4vbeazO%2FpQK%5CgiBW0MUDDWfB1EuNaV5c4wIJZ08hYQKDhpsHnDeMAgoz98dt%2B%2BFfhdiiNJw9Y9vRR5S4GU%2FziFp%2BliFX1QTJj%2BbaIGD3YxVzgumklAwJ0uBe%2FcGT6VeQW%3A1524179765762; __utmb=94650624.24.10.1524176140',
'Host': 'music.163.com',
'Referer': 'https://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
html = requests.get(urls, headers=headers)
pattern = re.compile(r'<div class="u-cover u-cover-alb3" title=(.*?)>')
items = re.findall(pattern, html.text)
cal = 0
# 首先删除这个没文件,要不然每次都是追加
if (os.path.exists("./txt/专辑信息.txt")):
os.remove("专辑信息.txt")
# 删除文件避免每次都要重复写入
if (os.path.exists("./txt/专辑歌曲信息.txt")):
os.remove("专辑歌曲信息.txt")
for i in items:
cal += 1
# 这里需要注意i是有双引号的,所以需要注意转换下
p = i.replace('"', '')
# 这里在匹配里面使用了字符串,注意下
pattern1 = re.compile(r'<a href="/album\?id=(.*?)" class="tit s-fc0">%s</a>' % (p))
id1 = re.findall(pattern1, html.text)
with open("./txt/专辑信息.txt", 'a') as f:
f.write(u'专辑的名字是:{}!!专辑的ID是{} \n'.format(i, id1))
get_joker_lyric_info(i, id1[0])
f.close()
print("总数是%d" % (cal))
print("获取专辑以及专辑ID成功!!!!!")得到的文件信息是
获取专辑对应的歌曲ID
def get_joker_lyric_info(id1):
urls3 = "http://music.163.com/#/album?id={}".format(id1)
print(urls3)
# 将不要需要的符号去掉
urls = urls3.replace("[", "").replace("]", "").replace("'", "").replace("#/", "")
headers = {
'Cookie': '_iuqxldmzr_=32; _ntes_nnid=dc7dbed33626ab3af002944fabe23bc4,1524151830800; _ntes_nuid=dc7dbed33626ab3af002944fabe23bc4; __utmz=94650624.1524151831.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=94650624.1505452853.1524151831.1524176140.1524296365.3; __utmc=94650624; WM_TID=RpKJQQ90pzUSYfuSWgFDY6QEK1Gb4Ulg; JSESSIONID-WYYY=7t6F3r9Uzy8uEXHPnVnWTXRP%5CSXg9U3%5CN8V5AROB6BIe%2B4ie5ch%2FPY8fc0WV%2BIA2ya%5CyY5HUBc6Pzh0D5cgpb6fUbRKMzMA%2BmIzzBcxPcEJE5voa%2FHA8H7TWUzvaIt%2FZnA%5CjVghKzoQXNM0bcm%2FBHkGwaOHAadGDnthIqngoYQsNKQQj%3A1524299905306; __utmb=94650624.21.10.1524296365',
'Host': 'music.163.com',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
}
html = requests.get(urls, headers=headers)
soup = BeautifulSoup(html.text, "html.parser")
book_div = soup.find_all("ul")
string_array = book_div[0].find_all("li")
for something in string_array:
html_data2 = something.find("a").text
items = re.findall(r"\d+\.?\d*", str(something))
with open("./txt/薛之谦专辑歌曲信息.txt", 'a') as f:
print(len(something))
if (len(something) > 0):
f.write(u'薛之谦歌曲的名字是:{}!!歌曲的ID是{}\n'.format(html_data2, items))
f.close()得到的相关歌曲信息是
根据得到的信息,爬去这首歌曲的热评和相关歌词
对得到的歌词进行相关分析
生成的html在html文件中,可以通过游览器进行打开
相关代码请看源代码
把得到的歌词进行合并,合并到一个文件里,并且去除相关空格之类的东西
def MergedFile():
"""
进行合文件操作
:return:
"""
aaa = 0
for song_file_name in glob.glob("./txt/lyrics/*歌曲名*"):
file_object = open(song_file_name, 'r', )
list_of_line = file_object.readlines()
for p in list_of_line:
if "作词" in p or "作曲" in p or "混音助理" in p or "混音师" in p or "录音师" in p or "执行制作" in p or "编曲" in p or "制作人" in p or "录音工程" in p or "录音室" in p or "混音录音室" in p or "混音工程" in p or "Programmer" in p or p == "\n" or "和声" in p or "吉他" in p or "录音助理" in p or "陈任佑鼓" in p or "薛之谦" in p:
aaa += 1
else:
with open("./txt/allLyric" + ".txt", "a") as f:
f.write(p)
f.write("\n")
file1 = open('./txt/allLyric.txt', 'r') # 要去掉空行的文件
file2 = open('./txt/allLyric_analysis.txt', 'w') # 生成没有空行的文件
try:
for line in file1.readlines():
if line == '\n':
line = line.strip("\n")
file2.write(line)
finally:
file1.close()
file2.close()进行歌词的分词以及生成词云
def show_Joker_pic():
# 读入背景图片
backgroud_Image = plt.imread("./word_pic/way_pic.jpg")
# 读取要生成词云的文件
text_from_file_with_apath = open("word.txt").read()
# 通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud(
background_color='white', # 设置背景颜色
mask=backgroud_Image, # 设置背景图片
max_words=10000, # 设置最大现实的字数
stopwords=STOPWORDS, # 设置停用词
font_path='/Library/Fonts/Songti.ttc', # 设置字体格式,如不设置显示不了中文 Mac是这样的设置方式
max_font_size=50, # 设置字体最大值
random_state=300, # 设置有多少种随机生成状态,即有多少种配色方案
scale=10,
width=16000,
height=8000
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(backgroud_Image)
my_wordcloud.recolor(color_func=image_colors)
# 以下代码显示图片
plt.imshow(my_wordcloud)
plt.axis("off")
print 'over'
plt.show()
my_wordcloud.to_file('./word_pic/show_Chinese.png')生成词云的步骤是
1.读取相关图片 2.生成想应的图片

github地址项目地址
本人联系方式微信
