
Atom is an accurate low-bit weight-activation quantization algorithm that combines (1) mixed-precision, (2) fine-grained group quantization, (3) dynamic activation quantization, (4) KV-cache quantization, and (5) efficient CUDA kernels co-design.
This codebase utilizes lm_eval to evaluate perplexity and zero-shot accuracy. Code segments from SmoothQuant, GPTQ, and SparseGPT are integrated to reproduce results. Our kernels are modified based on previous version of FlashInfer and tested by NVBench. Serving framework Punica is integrated to evaluate end-to-end throughput and latency. We also use BitsandBytes for new data-type evaluations (e.g., FP4). We thank the authors for their great works.
The current release features:
- Simulated quantization for accuracy evaluation.
- Perplexity and zero-shot accuracy evaluation
- Kernel benchmark & End-to-end evaluation
To do:
- Release code for reproducing results.
- Release code for end-to-end throughput evaluation.
- Add FP4 accuracy evaluation for both weight and activation quantization.
- Add support for Mixtral models.
- Optimize kernel for different GPUs.
- Full inference workflow in real production scenario.
The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance.
To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to 7.73× compared to the FP16 and by 2.53× compared to INT8 quantization, while maintaining the same latency target.
- Run in container. Mount models.
docker pull nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04
docker run -it --gpus all -v /PATH2MODEL:/model nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04 /bin/bash
- Clone this repo (Make sure you install Git, and Conda)
git clone --recurse-submodules https://github.com/efeslab/Atom
cd Atom
- Prepare environment
cd model
conda create -n atom python=3.10
conda activate atom
pip install -r requirements.txt
- Compile kernels benchmarks (Optional): Install gcc-11 and CMake (>= 3.24)
apt install software-properties-common lsb-release
apt-get update
curl -s https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | gpg --dearmor - | tee /etc/apt/trusted.gpg.d/kitware.gpg >/dev/null
apt-add-repository "deb https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main"
apt update
apt install cmake
cd /PATH_TO_ATOM/kernels
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt-get update
apt install -y gcc-11 g++-11
mkdir build && cd build
cmake ..
make -j
Before running this command, please download Llama model from Hugging Face website first. We recommend downloading from Deca-Llama.
We provide several scripts to reproduce our results in the paper:
To run our W4A4 perplexity evaluation, please execute
bash scripts/run_atom_ppl.sh /Path/To/Llama/Model
To get our W4A4 zero shot accuracy on common sense tasks, please execute
bash scripts/run_atom_zeroshot_acc.sh /Path/To/Llama/Model
To run our ablation study on different quantization optimizations, please run
bash scripts/run_atom_ablation.sh /Path/To/Llama/Model
You can also customize your own quantization setup by modifying the parameters. Check model/llama.py to see the description of each parameter.
python model/llama.py /Path/To/Llama/Model wikitext2 \
--wbits 4 --abits 4 --a_sym --w_sym \
--act_group_size 128 --weight_group_size 128 --weight_channel_group 2 \
--reorder --act_sort_metric hessian \
--a_clip_ratio 0.9 --w_clip_ratio 0.85 \
--keeper 128 --keeper_precision 3 --kv_cache --use_gptq \
--eval_ppl --eval_common_sense
We evaluate Atom on a RTX4090 GPU. Results below are executed in cu113 docker container. Note that current kernels are only optimized for RTX4090.
To get INT4 GEMM kernel result, please execute:
cd kernels/build
./bench_gemm_i4_o16
Check column Elem/s to see the computation throughput of the kernel (Flop/s).

Other kernel of Atom can be evaluated similarly, for e.g., ./bench_reorder. We conduct kernel evaluation on baselines as well. Please check baselines/README.md to reproduce results.
To reproduce end-to-end throughput and latency evaluation, please check e2e/README.md.
We evaluate Atom's accuracy on serveral model families, including Llama, Llama-2, and OPT.
- WikiText2, PTB and C4 datasets on Llama family:
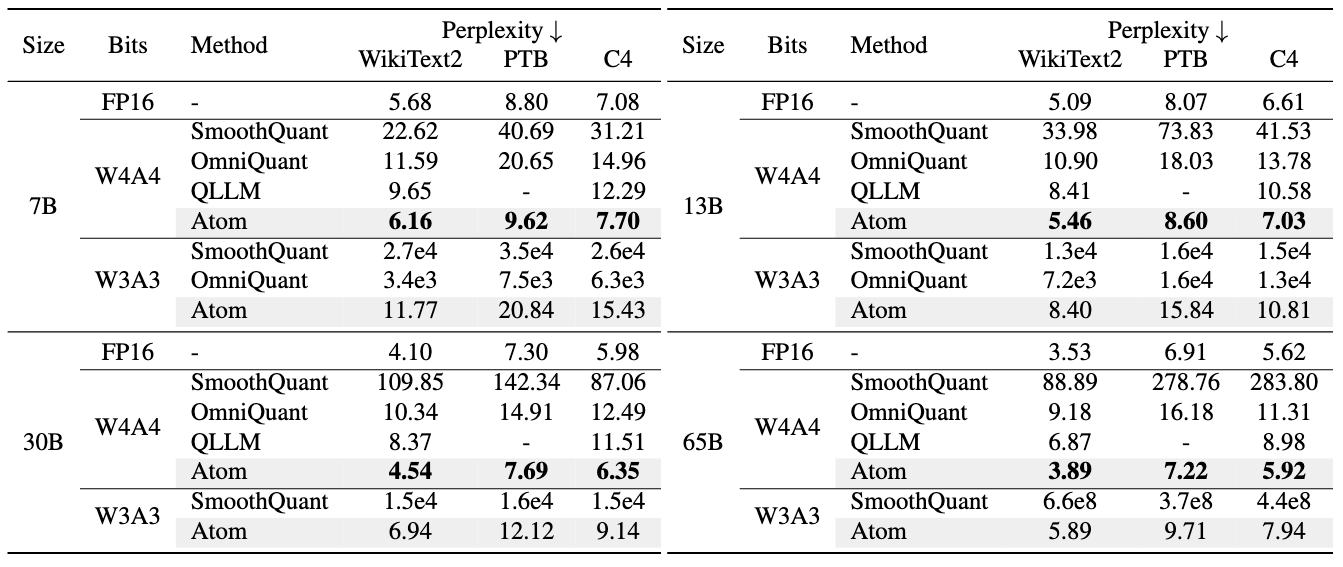
- WikiText2 comparing with SmoothQuant and OmniQuant on OPT:

| #Bit | Method | OPT-6.7B | OPT-13B | OPT-30B | OPT-66B |
|---|---|---|---|---|---|
| FP16 | - | 10.86 | 10.13 | 9.56 | 9.34 |
| W4A4 | SmoothQ | 1.80E+04 | 7.40E+03 | 1.20E+04 | 2.20E+05 |
| W4A4 | OmniQ | 12.24 | 11.65 | 10.6 | 10.29 |
| W4A4 | Atom | 11.23 | 10.44 | 9.70 | 9.57 |
- Atom achieves up to 7.7x higher throughput with similar latency than
FP16with a fixed GPU memory under serving scenario.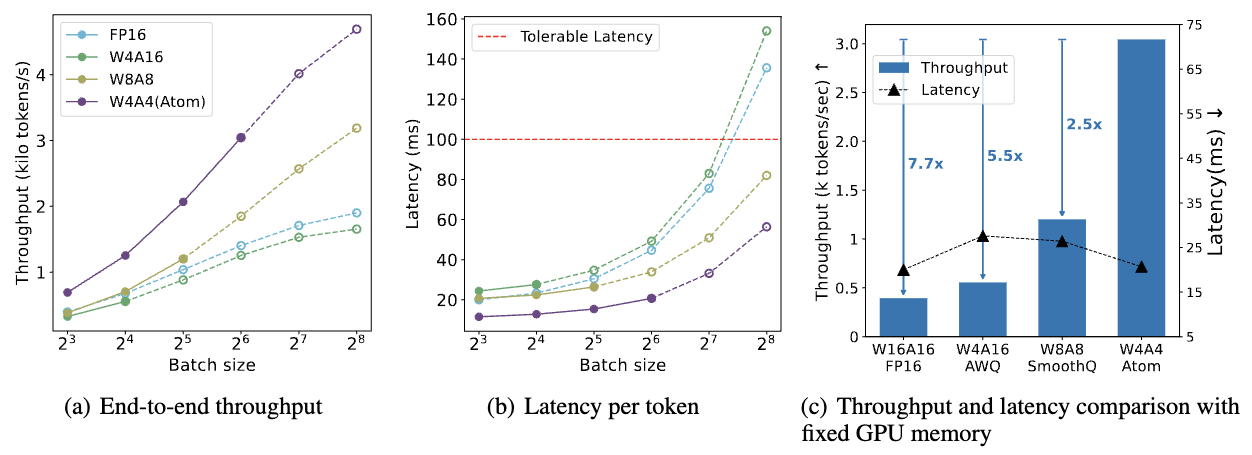

If you find this project is helpful to your research, please consider to cite our paper:
@article{zhao2023atom,
title={Atom: Low-bit Quantization for Efficient and Accurate LLM Serving},
author={Zhao, Yilong and Lin, Chien-Yu Lin and Zhu, Kan and Ye, Zihao and Chen, Lequn and Zheng, Size and Ceze, Luis and Krishnamurthy, Arvind and Chen, Tianqi and Kasikci, Baris},
journal={arXiv},
year={2023}
}