Tech companies have tremendous cost coming from their data center. A large portion of that is the cooling required to keep their servers operating with optimal performance. So, the problem to solve is minimizing the energy consumption of cooling the servers to keep them in their optimal range which will as a result minimize the electricity cost and save tremendous amounts of money and therefore, millions of dollars can be saved.
In 2016, DeepMind AI minimized a big part of Google’s cost by reducing Google Data Centre Cooling Bill by 40% using their DQN AI model (Deep Q-Learning). In our project we will try and work on this very problem. We will set up our own server environment, and we will build an AI that will be controlling the cooling/heating of the server so that it stays in an optimal range of temperatures while saving the maximum energy, therefore minimizing the costs. After accounting for "electrical losses and other non-cooling inefficiencies, "this 40 percent reduction translated into a 15 percent reduction in overall power saving", according to Google. Considering that the company used some 4,402,836 MWh of electricity in 2014 (equivalent to the amount of energy consumed by 366,903 US households), this 15 percent will translate into savings of hundreds of millions of dollars over the years.


We will set up our own server environment, and we will build an AI that will be controlling the cooling/heating of the server so that it stays in an optimal range of temperatures while saving the maximum energy, therefore minimizing the costs. We are going to optimise this using Deep-Q Reinforcement Learning for the optimization problem. We’ll be comparing the performance of the server’s internal cooling system with our RL agent’s performance in order to conclude energy savings. The internal cooling system simply brings the current temperature of the server into the optimal range bounds whereas our agent in its neural network architecture will learn weights using which it will predict a suitable action that results into less energy use.
Before we define the states, actions and rewards, we need to explain how the server
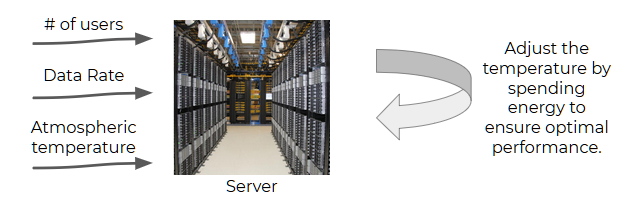
operates. At a given timestep, the server model has as input its intrinsic temperature, the number
of users online and the data rate going through it. Given, the 3-tuple, the agent has to predict an
action as defined in the action space. The states and action spaces are described on the following
page. This RL setup is illustrated below :
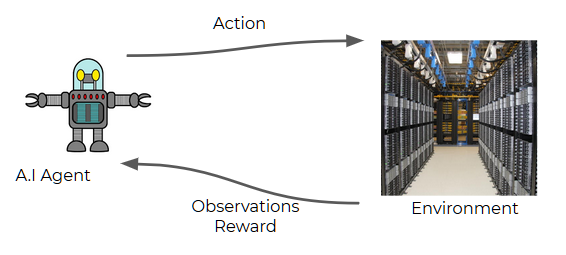
The variables of this environment (at any minute) are given as follows :
- The number of users online
- The temperature of the server
- The data transmission rate through the server
- The energy spent by the server’s internal cooling system that automatically brings the server’s temperature back to the optimal range whenever the server’s temperature goes outside this optimal range.
- The energy spent by the agent onto the server in order to heat it or cool it.
The state of the server at a time t is given as the 3-tuple shown below :

Thus, the input vector will consist of three elements.The agent will take this vector as input, and will return the action to play at each timestep.

-
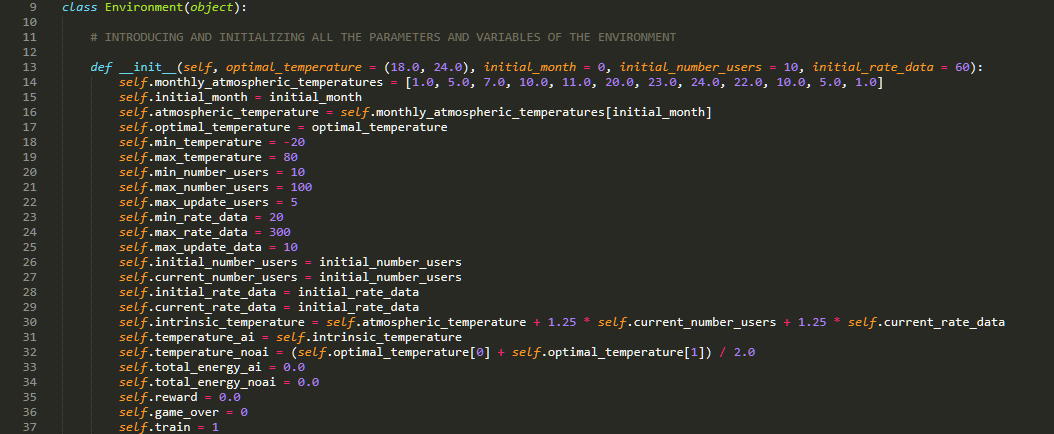
Building the Environment:
-
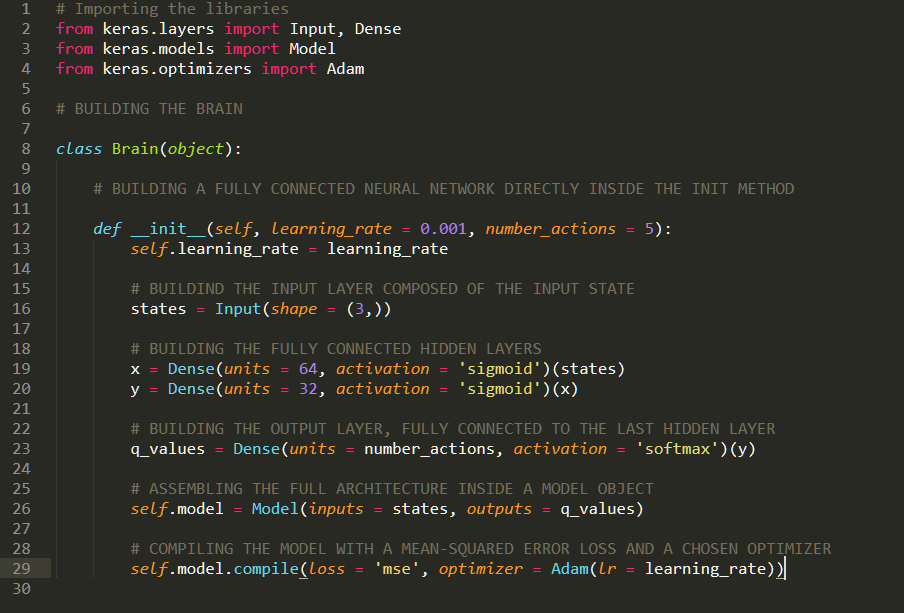
Neural Network Architecture:
-
Implementing the DQN:
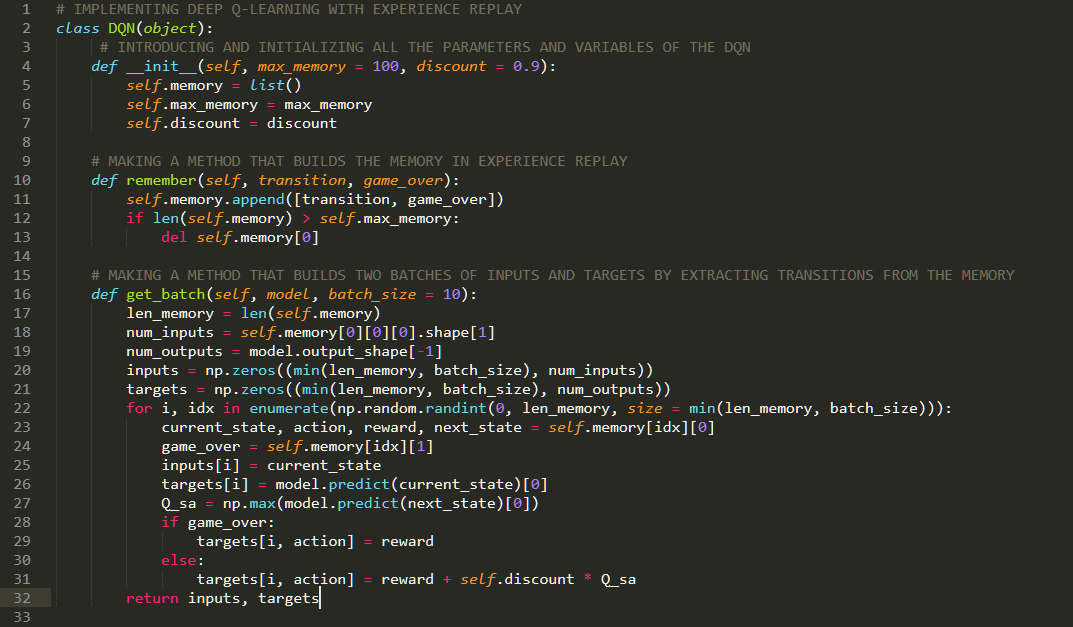
-
Training and Testing Setup:
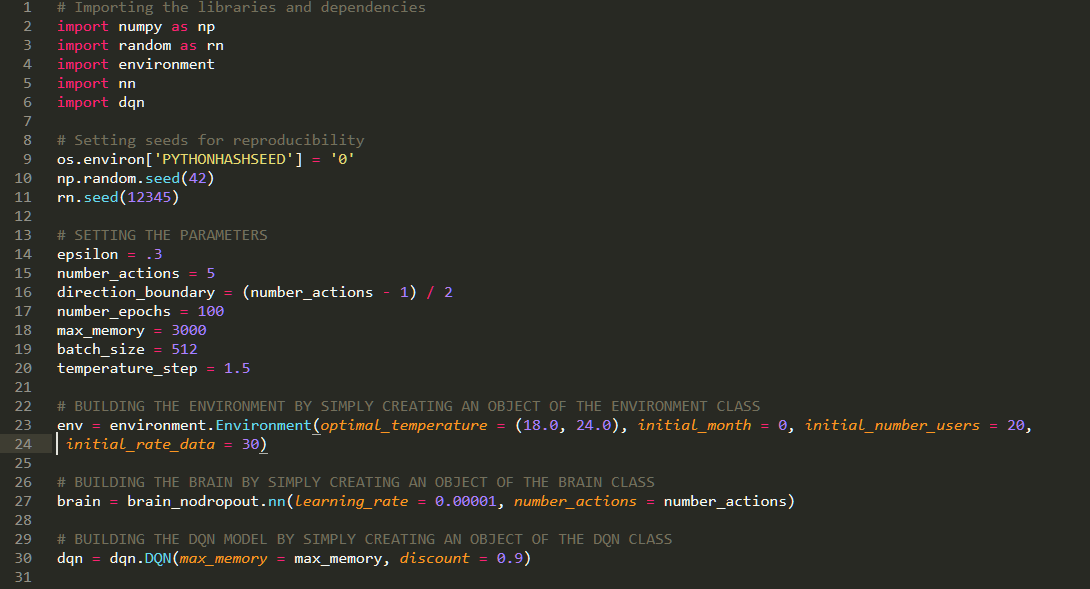
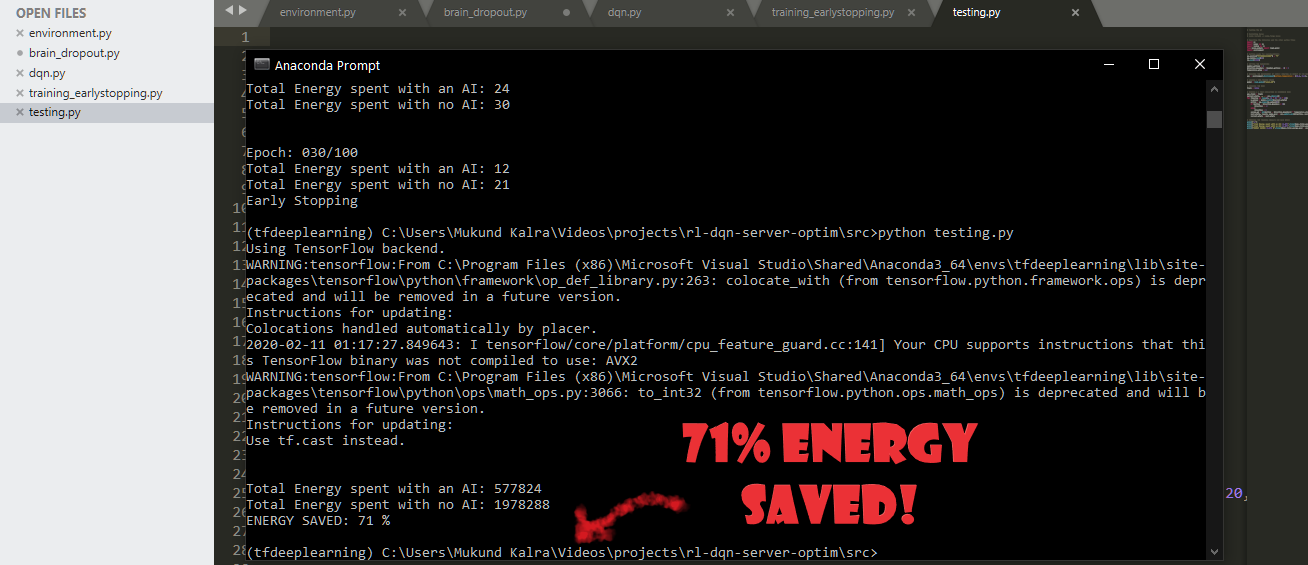
After training the model for 100 epochs each being 5 months, the model was tested for 1 year and the results were a savings on around 40-50% depending on different trials.
- DeepMind, 2016; DeepMind AI Reduces Google Data Centre Cooling Bill by 40%
- Richard Sutton et al., 1998, Reinforcement Learning I: Introduction
- Arthur Juliani, 2016, Simple Reinforcement Learning with Tensorflow (Part 4)
- D. J. White, 1993, A Survey of Applications of Markov Decision Processes
- Richard Sutton, 1988, Learning to Predict by the Methods of Temporal Differences
- Michel Tokic, 2010, Adaptive ε-greedy Exploration in Reinforcement Learning Based on Value Differences
- Tom Schaul et al., Google DeepMind, 2016, Prioritized Experience Replay