By Maxim Bonnaerens, and Joni Dambre.
Vision transformers have demonstrated remarkable success in a wide range of computer vision tasks over the last years. However, their high computational costs remain a significant barrier to their practical deployment. In particular, the complexity of transformer models is quadratic with respect to the number of input tokens. Therefore techniques that reduce the number of input tokens that need to be processed have been proposed. This paper introduces Learned Thresholds token Merging and Pruning (LTMP), a novel approach that leverages the strengths of both token merging and token pruning. LTMP uses learned threshold masking modules that dynamically determine which tokens to merge and which to prune. We demonstrate our approach with extensive experiments on vision transformers on the ImageNet classification task. Our results demonstrate that LTMP achieves state-of-the-art accuracy across reduction rates while requiring only a single fine-tuning epoch, which is an order of magnitude faster than previous methods.
 |
+ |  |
= |  |
|---|
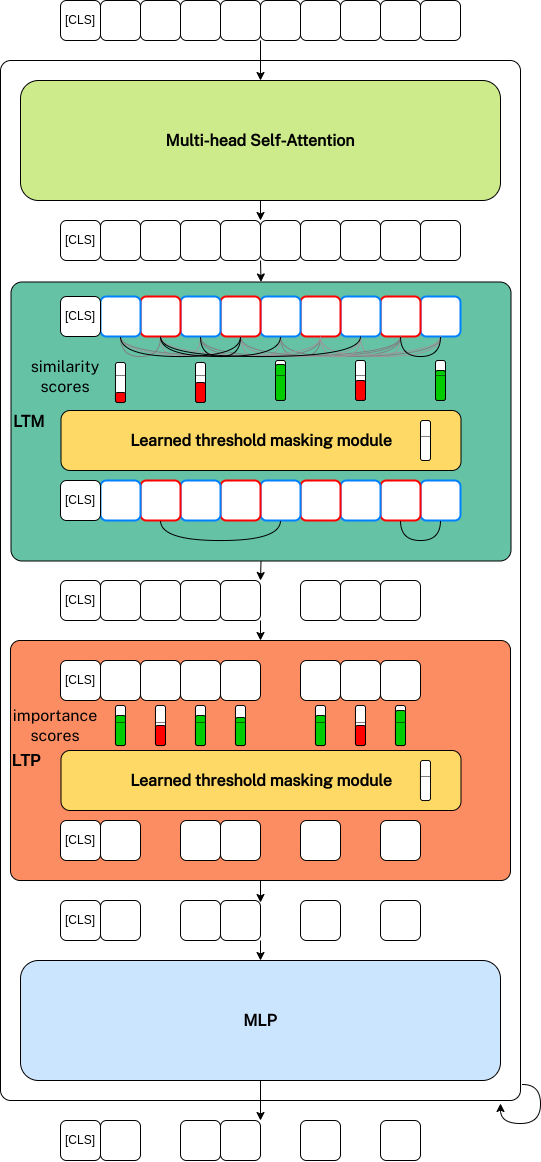
An overview of our framework is shown below. Given any vision transformer, our approach adds merging (LTM) and pruning (LTP) components with learned threshold masking modules in each transformer block between the Multi-head Self-Attention (MSA) and MLP components. Based on the attention in the MSA, importance scores for each token and similarity scores between tokens are computed. Learned threshold masking modules then learn the thresholds that decide which tokens to prune and which ones to merge.
pip install -e .This repository is based on the vision transformers of 🤗timm (v0.9.5).
LTMP Vision Transformers for training can be used as follows:
import timm
import ltmp
model = timm.create_model("ltmp_vit_base_patch16_224", pretrained=True, tau=0.1, **kwargs)To reproduce the results from the paper run:
python tools/train.py /path/to/imagenet/ --model ltmp_deit_small_patch16_224 --pretrained -b 128 --lr 0.000005 0.005 --reduction-target 0.75"ltmp_{vit_model}" models obtained through the training detailed above can be used for inference by using the following variant which actually prunes and merges tokens.
import timm
import ltmp
model = timm.create_model("inference_ltmp_vit_base_patch16_224", pretrained=True, tau=0.1, **kwargs)To check the accuracy of trained models:
python tools/validate_timm.py /path/to/imagenet/ --model ltmp_deit_small_patch16_224 --checkpoint /path/to/checkpoint.pth.tar -b 1See ./ltmp/timm/lt_mergeprune.py and ./ltmp/timm/lt_mergeprune_inference.py for the changes required to adopt LTMP in a vision transformer.
./tools/train.py contains the code to train LTMP models.
If you find this work useful, consider citing it:
@article{
bonnaerens2023learned,
title={Learned Thresholds Token Merging and Pruning for Vision Transformers},
author={Maxim Bonnaerens and Joni Dambre},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2023},
url={https://openreview.net/forum?id=WYKTCKpImz},
note={}
}