2021.02.28
- 此系統的主要目的為提供一般使用者輸入自己的刑事案件情境,系統即會回饋最相似案件情境的前N篇法律判決書。
python 3.6
sentence_transformers 0.3.6
scipy 1.3.1
wget https://www.dropbox.com/s/8siytnrli5ey47i/TFIDF.tgz
tar zxf TFIDF.tgz
rm TFIDF.tgzdocker-compose up --detach --buildFor the backend, it may take several hours to start the service.
- 使用 [標註資料用V1.ipynb] 將判決書資料集轉換成公共 Testing Data。(檔名最後有 "X" 表示有做 NR)
- dir = 'dataR11' 為指定輸出的資料夾名稱
- 使用 [標註資料用V2.ipynb] 產生 Training Data,會依照指定資料夾的Testing Data扣除後產生。由最大的指定資料量產生,之後遞減輸入指定資料量重複產生。
- dir = 'dataR11' 為指定輸入Testing Data 與欲輸出的資料夾名稱。
- train_onum = 600 (上一次較大的資料量)
- train_num = 100 (本次欲輸出的資料量)
- 詳細程式碼與資料集資訊,請至LSCBERT的github
- NCHU-LJSD 資料集
https://drive.google.com/drive/u/2/folders/12hKOa9jJZAQd1-qXqPS1c3YoSAVvKqhc
- 使用二元分類器,判斷法律判決書是否含有案件情境。並將有案件情境的判決書蒐集起來,筆數自己決定。我們實驗蒐集了10萬筆資料。
- 僅測試程式功能流程,可以直接使用[NCHU-LJSD] 部分資料集即可。
- 使用 [標註資料用_大量.ipynb] 對Step1的大量判決書資料整理產生 Testing Data。
- 並使用 [LSCBERT 實驗-Step5] 儲存的模型,對Testing Data 直接產生案件情境。
- 另外將 Step1. 的資料集,產生要使用於計算詞彙 Tfidf 的 JSON檔案。丟進 ~/TFIDF/data_tfidf。
- 上半部為將指定資料集的所有不是常用的詞彙計算TFIDF並排序。
- 下半部為將TFIDF (P)值數值超過 p_upper 匯集起來,製作為一個詞彙庫。 然後對Step2 額外產生的 Result的案件情境內容做斷詞後,再將所有詞彙比對上半部產生的做詞彙表,如有在詞彙表中的詞彙則剃除。
- p_upper=3.0 表示蒐集 TDIDF P值大於3.0的詞彙。
- pip install -U sentence-transformers
https://github.com/UKPLab/sentence-transformers/tree/master/sentence_transformers
- 至[sentence_transformers]資料夾,將[~/STBERT/Cover/SentenceTransformer.py] 與 [Cover/util.py] 覆蓋。
- num_clusters = 20 => KMeans 分20群
- simtype = 'COS' => 選擇相似度演算法 (COS/DIS/DPS 已完成,剩餘需修改)
- berttype = 'bert-base-chinese' => 選擇BERT模型
- AutoComAEOCTimes = 15 => 重複計算 AEOC 15次。
-
將 LSCBERT 實驗 Step5. 留下的模型中所有檔案放入 [~/STBERT/TFIDF]。
-
此為範例模型,將這兩個模型放在 ~/LSCBS/TFIDF/ 底下,自行選擇
-
data_tfidf2是選取十萬筆判決書來做比對。
https://drive.google.com/file/d/1N1o-dRrBP58folqqAzX9POe_AWyqDSsJ/view?usp=sharing
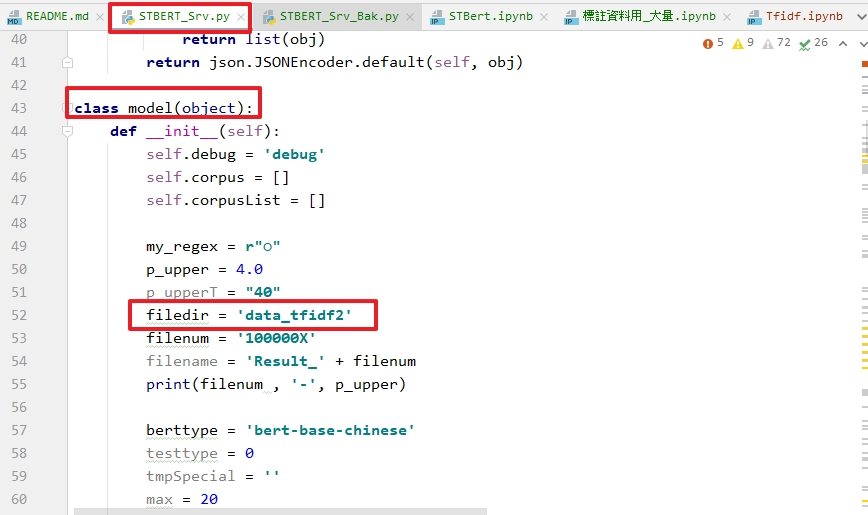
- 在STBERT_Srv.py 行49~61 可以自行調整參數,以及相對應的資料夾。如下圖,我是選擇data_tfidf2
- 執行 STBERT_Srv.py
- 前端環境 js jquery(功能面)+bootstrap(網頁介面)
- 後端環境 PHP 5.2.0
- 將 ~/WebSite_LSCBS 所有檔案丟進你的網站即可。內容均為 LSCBS 實驗的程式調整。