Source code for our SIGIR'25 paper: Enhancing the Patent Matching Capability of Large Language Models via Memory Graph
If you find this work useful, please cite our paper and give us a shining star 🌟
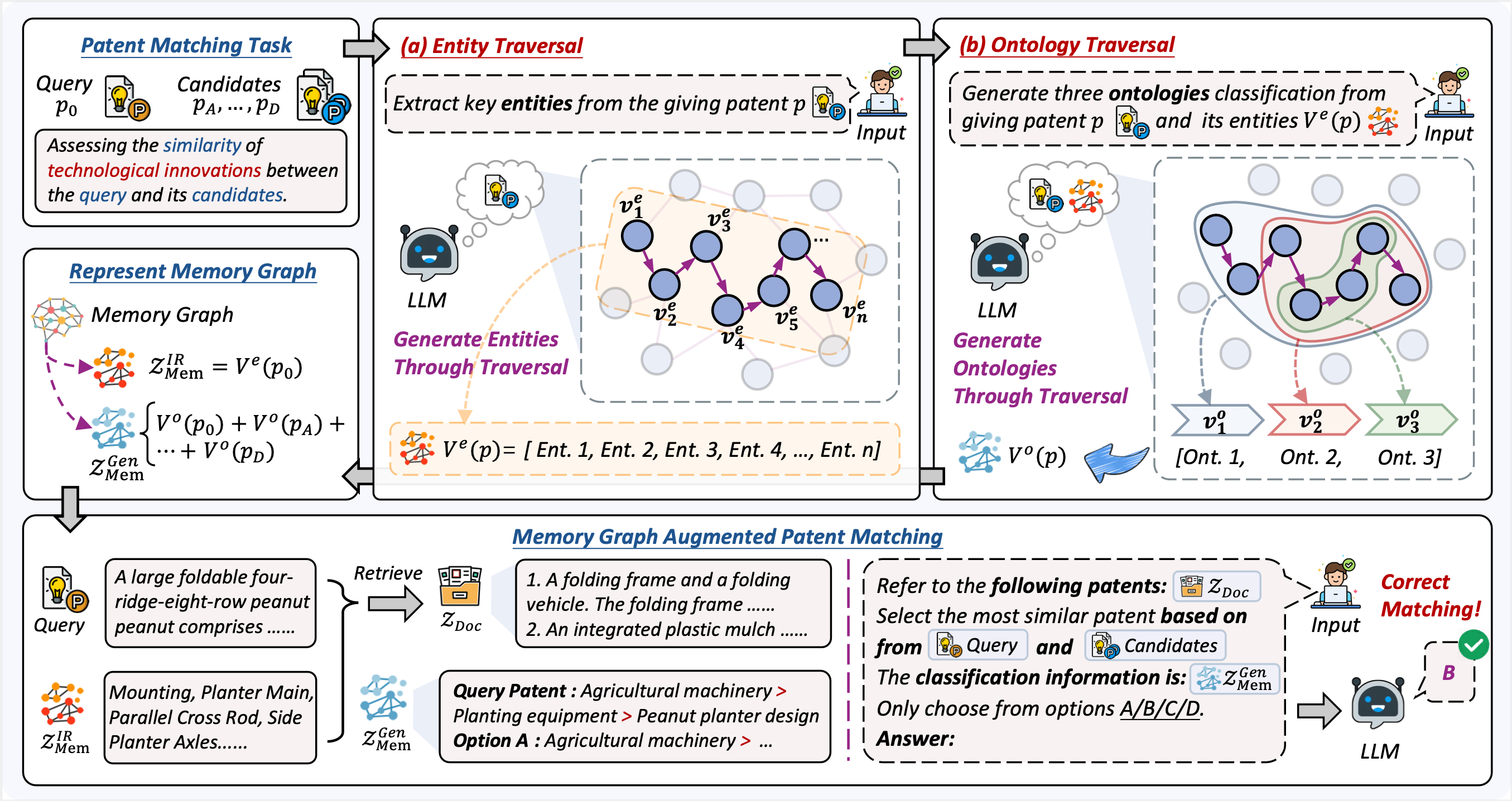
We propose MemGraph, a method that augments the patent matching capabilities of LLMs by incorporating a memory graph derived from their parametric memory.
Specifically, MemGraph prompts LLMs to traverse their memory to identify relevant entities within patents, followed by attributing these entities to corresponding ontologies. After traversing the memory graph, we utilize extracted entities and ontologies to improve the capability of LLM in comprehending the semantics of patents.
Experimental results on the PatentMatch dataset demonstrate the effectiveness of MemGraph, achieving a 17.68% performance improvement over baseline LLMs.
1️⃣ Clone from git:
git clone https://github.com/NEUIR/MemGraph.git
cd MemGraph2️⃣ Install dependencies:
pip install -r requirements.txt1️⃣ Download retrieval corpus we collected from the Google Drive, create a corpus directory and make sure that the files under the data folder contain the following before running:
data/
├── corpus/
│ ├── patent_en.json
│ └── patent_zh.json
└── benchmark/
2️⃣ Data Processing
sh scripts/data_processing.sh3️⃣ Our implementation requires both embedding and language models. First, create a models directory in the project root and download the necessary models from Hugging Face:
models/
├── embedding/
│ ├── bge-base-en/ # English embedding model
│ └── bge-base-zh/ # Chinese embedding model
└── llm/
└── Qwen2-7B-Instruct/ # Language model
You can download these models from:
- Embedding models: BAAI/bge-base-en, BAAI/bge-base-zh
- Language Model: Qwen2-7B-Instruct (or other compatible LLMs like Qwen2.5-14B-Instruct, Llama-3-8B-Instruct, GLM-4-9B-Chat)
1️⃣ Build MemGraph
# Generate entity
sh scripts/generate_entity.sh
# Generate ontology
sh scripts/generate_ontology.sh2️⃣ Retrieval with MemGraph
sh scripts/retrieval.sh3️⃣ Inference with MemGraph
sh scripts/inference.sh@inproceedings{xiong2025enhancing,
title={Enhancing the Patent Matching Capability of Large Language Models via Memory Graph},
author={Xiong, Qiushi and Xu, Zhipeng and Liu, Zhenghao and Wang, Mengjia and Chen, Zulong and Sun, Yue and Gu, Yu and Li, Xiaohua and Yu, Ge},
booktitle={Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval},
year={2025}
}If you have questions, suggestions, and bug reports, please email:
xiongqiushi@stumail.neu.edu.cn