About: Notebooks for Hadoop Clusters README
Literate Computing for Reproducible Infrastructure: インフラ運用をJupyter + Ansibleでおこなう際のお手本Notebookです。(Hadoop版)
このリポジトリでは、HDP(Hortonworks Data Platform, https://jp.hortonworks.com/products/data-center/hdp/ )を利用してHadoopクラスタを構築し、運用するためのNotebook例を紹介しています。
なお、これらのNotebookはNIIクラウドチーム内で行っている作業の考え方を示すためのもので、環境によってはそのままでは動作しないものもあります。

Literate-computing-Hadoop (c) by National Institute of Informatics
Literate-computing-Hadoop is licensed under a Creative Commons Attribution 4.0 International License.
You should have received a copy of the license along with this work. If not, see http://creativecommons.org/licenses/by/4.0/.
関連資料
お手本Notebook
お手本NotebookはこのNotebookと同じディレクトリにあります。Notebookは目的に応じて以下のような命名規則に則って名前がつけられています。
- D(NN)_(Notebook名) ... インストール関連Notebook
- O(NN)_(Notebook名) ... 運用関連Notebook
- T(NN)_(Notebook名) ... テスト関連Notebook
特に、[D00_Prerequisites for Literate Computing via Notebooks](D00_Prerequisites for Literate Computing via Notebooks.ipynb)は、お手本Notebookが適用可能なNotebook環境、Bind対象であるかどうかを確認するためのNotebookです。はじめに実施して、これらのお手本Notebookが利用可能な状態かを確認してみてください。
お手本Notebookの構成
このNotebookは、大きく分けて以下のような構成になっています。
- 収容設計の準備Notebook
- Hadoopマシン準備Notebook
- HadoopインストールNotebook
- Hadoop運用Notebook
- Hadoop動作確認Notebook
これらのNotebookと、構築・運用する対象の関係は、以下のようになります。

収容設計の準備Notebook は、構築・運用対象とするシステム全体の収容設計をおこないます。ここで、どのようなマシンがあって(あるいは用意する必要があって)、それぞれのマシンにどのような役割を割り当てるかを明確化します。このプロセスによりAnsibleのInventory, 変数群を生成します。ここで、Ansibleなど自動化ツールに与えるパラメータと、収容設計の関連を明確化します。
Hadoopマシン準備Notebook は、Hadoopのインストール対象のマシンを準備し、Hadoop(HDP)のインストールに必要な前提条件を満たすよう各マシンのOS設定を調整します。それぞれの要件については各Notebookを参照してください。
HadoopインストールNotebook は、Hadoopおよびその周辺ツールのインストール手順を定義します。マシンの準備Notebookにより前提条件が満たされた状態のマシンに対して各種ツールをインストールすることができます。
Hadoop運用Notebook は、構築した環境を保守する手順を定義します。実際にクラスタを構築すると、ハードウェア故障が生じたりさまざまなトラブルが発生するので、それらの状態変化に応じてクラスタの健康状態を維持する必要があります。公開したこれらのNotebookは運用における手順や考え方を紹介する一例であり、障害の具体的な発生状況に応じて修正しながら実施する必要があります。
Hadoop動作確認Notebook は、構築した環境に実際にデータをアップロードしてみたり、ジョブを実行してみたりする例を提供します。HadoopインストールNotebookを通してインストールされた環境の使い方を示す役割もあります。
収容設計の準備Notebook
Hadoopのように複数ノードからなるクラスタを構築・運用する際は、それぞれのノードにどのようなロール(役割)を割り振って、リソースを割り当てていくか(収容設計)が重要なポイントになります。収容設計を明確にしながらシステムを構築・運用していくことで、的確なシステムのスケールや、スムーズなトラブル対応をすることが可能になります。
そこで、インストールの前に以下のNotebookにより、収容設計の確認をしながら、AnsibleのInventoryやgroup_varsといった各種パラメータを生成しています。
- [D10_Hadoop - Set! Inventory](D10_Hadoop - Set! Inventory.ipynb)
ここで生成されるパラメータは、以降の手順のNotebookで設定ファイル生成の際に利用されます。
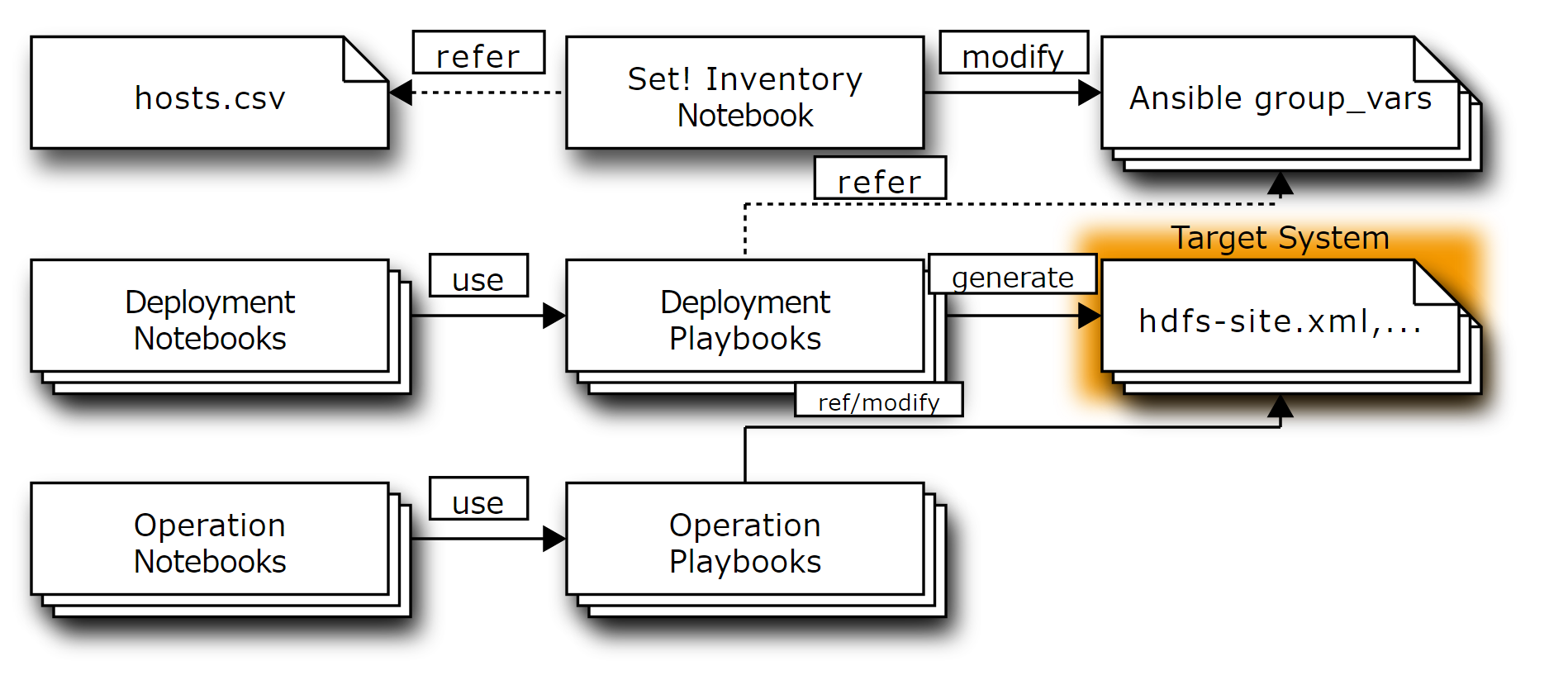
ここで定義されるパラメータには、以下のようなものがあります。
- 各サービスに割り当てるリソース量の情報
- 各サービスのインストールに使用する外部リソースの情報
Hadoop構築Notebookでは、各マシンにどのサービスを載せて、どの程度のメモリやディスクを割り当てていくかは、 hosts.csv のような表形式で定義しています。この情報に基づいて、AnsibleのPlaybookに与えるパラメータを定義しています。
また、Hadoopのインストール時にどのリポジトリからパッケージを取ってくるかという情報も、システムの素性を理解するうえで重要な情報です。このような情報も含めてNotebookの形で明確化、証跡を残すようにしています。
Hadoopマシン準備Notebook
Hadoopをインストールする対象となるマシンの準備に関するNotebookです。
VMの作成手順
NIIクラウドチームでは、プライベートなベアメタルクラウド(仮想マシンではなく物理マシンを貸すIaaS)を持っています。このクラウド上でベアメタル(物理マシン)を複数台用意し、そこにHadoopをインストールする形を採っています。 ベアメタルの設定手順の事例紹介は難しいのですが、テスト用クラスタを構築する際に使っているKVM環境の準備と、VMの構築用Notebookをここでは紹介しています。
この例では、以下のものを準備しています。
- [D03_KVM - Ready! on CentOS](D03_KVM - Ready! on CentOS.ipynb)
- [D03b_KVM - Set! CentOS6](D03b_KVM - Set! CentOS6.ipynb)
- [D03c_KVM - Go! VM](D03c_KVM - Go! VM.ipynb)
また、Google Compute Engineでのマシン確保を想定したNotebookも添付しています。
- [D01_GCE - Set! Go! (Google Compute Engine)](D01_GCE - Set! Go! %28Google Compute Engine%29.ipynb)
- [O03_GCE - Destroy VM (Google Compute Engine)](O03_GCE - Destroy VM %28Google Compute Engine%29.ipynb)
VMの設定手順
作成したVMは、MinimalなOSがインストールされた状態ですので、(当然のことながら)セキュリティ上必要な設定を施す必要があります。
- [D90_Postscript - Operational Policy Settings; Security etc. (to be elaborated)](D90_Postscript - Operational Policy Settings; Security etc. %28to be elaborated%29.ipynb)
また、HDPをインストールするために必要な推奨設定などもあります。これらの設定を施すNotebookも紹介しています。
- [D11_Hadoop Prerequisites - Ready! on CentOS6](D11_Hadoop Prerequisites - Ready! on CentOS6.ipynb)
これらの設定としてどのような項目が必要かは、VMの初期設定により異なってきます。
HadoopインストールNotebook
Hadoopのインストールは以下のような手順で実施しています。 HDPで提供されていないものについては、HDPインストール用Notebookとは別にNotebookを用意しています。
- [D12_Hadoop - Ready! on CentOS6 - ZK,HDFS,YARN,HBase,Hive,Spark](D12_Hadoop - Ready! on CentOS6 - ZK,HDFS,YARN,HBase,Hive,Spark.ipynb)
- [D13a_Hadoop Swimlanes - Ready! on Tez](D13a_Hadoop Swimlanes - Ready! on Tez.ipynb)
- [D13b_Hivemall - Ready! on Hive](D13b_Hivemall - Ready! on Hive.ipynb)
Hadoop運用Notebook
Hadoopの運用に関しては、以下のようなNotebookを用意しています。
- [O12a_Hadoop - Start the services - ZK,HDFS,YARN,HBase,Spark](O12a_Hadoop - Start the services - ZK,HDFS,YARN,HBase,Spark.ipynb)
- [O12b_Hadoop - Stop the services - Spark,HBase,YARN,HDFS,ZK](O12b_Hadoop - Stop the services - Spark,HBase,YARN,HDFS,ZK.ipynb)
- [O12c_Hadoop - Decommission DataNode](O12c_Hadoop - Decommission DataNode.ipynb)
- [O12d_Hadoop - Restore a Slave Node](O12d_Hadoop - Restore a Slave Node.ipynb)
Hadoop動作確認Notebook
動作確認のためのNotebookとして、以下のものを用意しています。
- [T12a_Hadoop - Confirm the services are alive - ZK,HDFS,YARN,HBase,Spark](T12a_Hadoop - Confirm the services are alive - ZK,HDFS,YARN,HBase,Spark.ipynb)
- [T12b_Hadoop - Simple YARN for Test job](T12b_Hadoop - Simple YARN job for Test.ipynb)
- [T12c_Hadoop - Simple HBase query for Test.ipynb](T12c_Hadoop - Simple HBase query for Test.ipynb)
- [T12d_Hadoop - Simple Spark script for Test](T12d_Hadoop - Simple Spark script for Test.ipynb)
- [T13b_Hadoop - Simple Hivemall query for Test](T13b_Hadoop - Simple Hivemall query for Test.ipynb)
お手本Notebookの一覧
現在、このNotebook環境からアクセス可能なNotebookの一覧を参照するには、以下のセルを実行(Run cell)してください。Notebookファイルへのリンクが表示されます。
import re
import os
from IPython.core.display import HTML
ref_notebooks = filter(lambda m: m, map(lambda n: re.match(r'([A-Z][0-9][0-9a-z]+_.*)\.ipynb', n), os.listdir('.')))
ref_notebooks = sorted(ref_notebooks, key=lambda m: m.group(1))
HTML(''.join(map(lambda m: '<div><a href="{name}" target="_blank">{title}</a></div>'.format(name=m.group(0), title=m.group(1)),
ref_notebooks)))お手本Notebookと証跡Notebook
お手本Notebookを使う場合は、お手本をコピーし、そのコピーを開きます。このように、お手本と作業証跡は明確に分けながら作業をおこないます。
また、お手本をコピーする際は、 YYYYMMDD_NN_ といった実施日を示すプレフィックスを付加することで、後で整理しやすくしています。
実際にお手本Notebookを使ってみる
以下のJavaScriptを実行することで、簡単にお手本から作業用Notebookを作成することもできます。
以下のセルを実行すると、Notebook名のドロップダウンリストと[作業開始]ボタンが現れます。 [作業開始]ボタンを押すと、お手本Notebookのコピーを作成した後、自動的にブラウザでコピーが開きます。 Notebookの説明を確認しながら実行、適宜修正しながら実行していってください。
from datetime import datetime
import shutil
def copy_ref_notebook(src):
prefix = datetime.now().strftime('%Y%m%d') + '_'
index = len(filter(lambda name: name.startswith(prefix), os.listdir('.'))) + 1
new_notebook = '{0}{1:0>2}_{2}'.format(prefix, index, src)
shutil.copyfile(src, new_notebook)
print(new_notebook)
frags = map(lambda m: '<option value="{name}">{title}</option>'.format(name=m.group(0), title=m.group(1)),
ref_notebooks)
HTML('''
<script type="text/Javascript">
function copy_otehon() {
var sel = document.getElementById('selector');
IPython.notebook.kernel.execute('copy_ref_notebook("' + sel.options[sel.selectedIndex].value + '")',
{'iopub': {'output': function(msg) {
window.open(msg.content.text, '_blank')
}}});
}
</script>
<select id="selector">''' + ''.join(frags) + '</select><button onclick="copy_otehon()">作業開始</button>')D00_Prerequisites for Literate Computing via NotebooksD01_GCE - Set! Go! (Google Compute Engine)D03_KVM - Ready! on CentOSD03b_KVM - Set! CentOS6D03c_KVM - Go! VMD10_Hadoop - Set! InventoryD11_Hadoop Prerequisites - Ready! on CentOS6D12_Hadoop - Ready! on CentOS6 - ZK,HDFS,YARN,HBase,Hive,SparkD13a_Hadoop Swimlanes - Ready! on TezD13b_Hivemall - Ready! on HiveD90_Postscript - Operational Policy Settings; Security etc. (to be elaborated)O03_GCE - Destroy VM (Google Compute Engine)O03_KVM - Destroy VM on KVMO12a_Hadoop - Start the services - ZK,HDFS,YARN,HBase,SparkO12b_Hadoop - Stop the services - Spark,HBase,YARN,HDFS,ZKO12c_Hadoop - Decommission DataNodeO12d_Hadoop - Restore a Slave NodeT03_KVM - Confirm KVM is healthy T03_KVM - Status Report of running VMsT12a_Hadoop - Confirm the services are alive - ZK,HDFS,YARN,HBase,SparkT12b_Hadoop - Simple YARN job for TestT12c_Hadoop - Simple HBase query for TestT12d_Hadoop - Simple Spark script for TestT13b_Hadoop - Simple Hivemall query for Test作業開始
お手本のアーカイブ
以下のセルで、お手本NotebookのZIPアーカイブを作成できます。
ref_notebooks = filter(lambda m: m, map(lambda n: re.match(r'([A-Z][0-9][0-9a-z]+_.*)\.ipynb', n), os.listdir('.')))
ref_notebooks = sorted(ref_notebooks, key=lambda m: m.group(1))
!zip ref_notebooks-{datetime.now().strftime('%Y%m%d')}.zip README.ipynb hosts.csv {' '.join(map(lambda n: '"' + n.group(0) + '"', ref_notebooks))} scripts/* images/* group_vars/.gitkeepこいつを・・・以下のURLからダウンロードできます。
HTML('<a href="../files/{filename}" target="_blank">{filename}</a>' \
.format(filename='ref_notebooks-' + datetime.now().strftime('%Y%m%d') + '.zip'))