AI-RecommenderSystem
该仓库主要是沉淀自学推荐系统路上学习到的一些经典算法模型和技术,并尝试用浅显易懂的语言把每个模型或者算法解释清楚!此次整理通过CSDN博客+GitHub的形式进行输出, CSDN主要整理算法的原理或者是经典paper的解读, 而GitHub上主要是模型代码复现。
模型的原理部分, 可以参考我的博客链接推荐系统学习笔记
内容简介
关于要整理的模型和技术,我这里按照自己的理解做了一个思维导图:
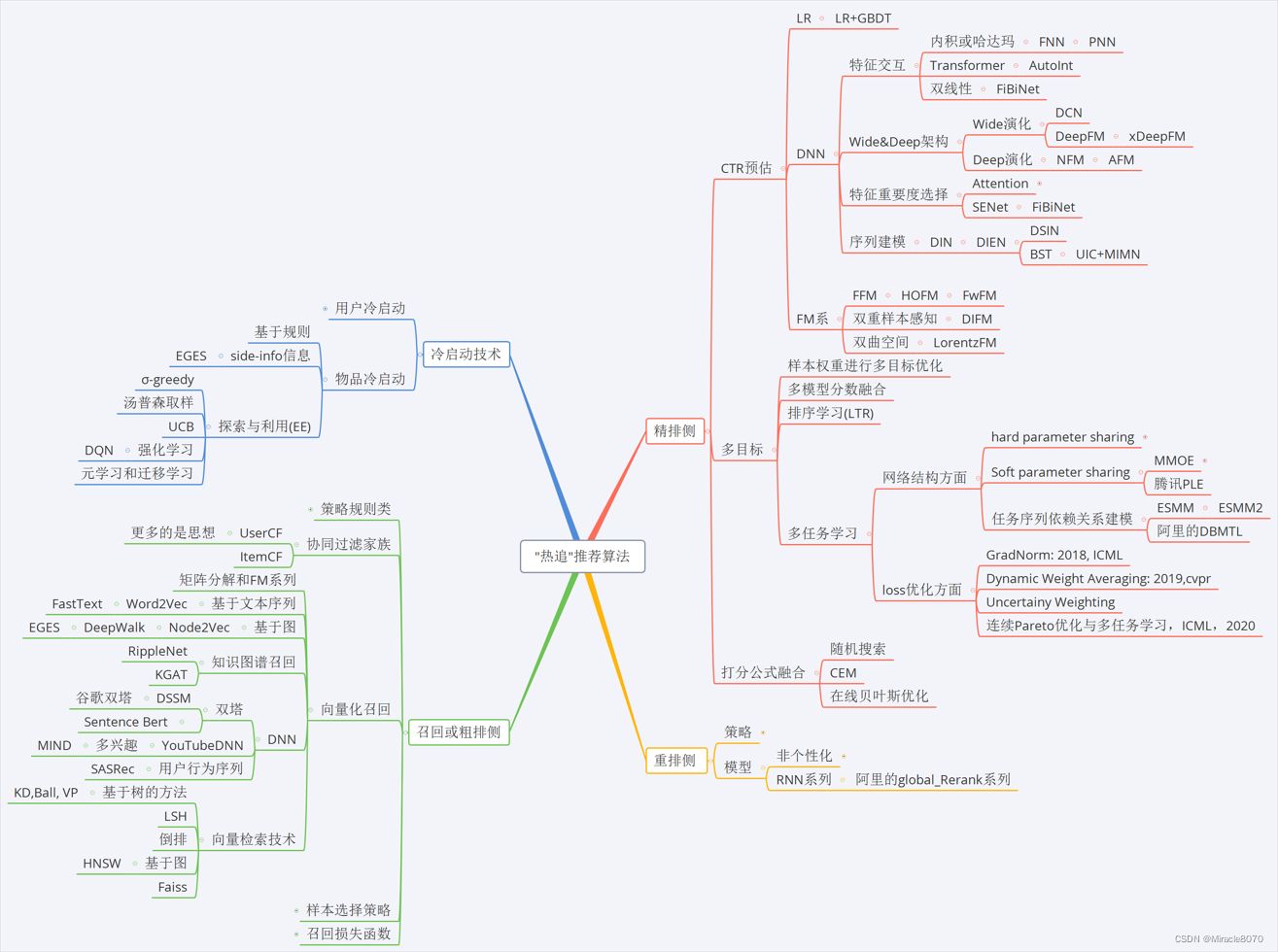
“热追"推荐算法的特色是从实际应用的角度去梳理推荐系统领域目前常用的一些关键技术,主要包括召回粗排,精排,重排以及冷启动,这几个差不多撑起了工业界推荐系统的流程。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快,精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准, 但有时候,排序环节的速度是跟不上召回的,所以往往也可以在这两块直接加一个粗排,用少量用户和物品特征,对召回结果再先进行一波筛选。 而重排侧,主要是结合精排的结果,再加上各种业务策略,比如去重,插入,打散,多样性保证等,主要是技术产品策略主导或改善用户体验的。 所以这四个环节组合起来,以"迅雷不及掩耳漏斗之势”,组成了推荐系统的整个架构。
数据集简介
在初学阶段的时候, 使用的数据集是paper里面经常见到的公开性数据集
之前整理的精排模型采用的数据,都是用这里面的数据进行采样,然后跑通。
但目前存在一些问题:
- 首先是这些数据集虽然是来自工业上的数据,但我之前每个精排模型可能使用的数据都不一样,有的很简单,有的数据比较复杂, 导致这些模型没办法对比到一块,依然是停留在学习模型原理的阶段。
- 在数据量上, Criteo Dataset数据集的数量过少, 用这个数据集的模型可能没办法收敛
- 由于数据太简单, 在精排模型里面学习到的策略也没法直接使用和做实验进行验证,只是先跑通
所以, 后面我打算采用一个统一的稍微正规的数据集,是新闻推荐的一个数据集,来自于某个推荐比赛,因为这个数据集是来自工业上的真实数据,所以使用起来比之前用的movielens数据集可尝试的东西多一些,并且原数据有8个多G,总共3个文件: 用户画像,文章画像, 点击日志,用户数量100多万,6000多万次点击, 文章规模是几百,数据量也比较丰富, 用户的历史行为记录也超级丰富。 这样可以使得所有的精排模型或者召回模型都可以在这上面做实验,这样也能对比各个模型之间的效果, 另外一个好处,这个和我之前参与整理的推荐系统开源项目fun-rec很相似, 这个项目里面有个仿照工业界实现的一个推荐系统, 使得学习完基础模型的原理之后,能快速通过做新闻推荐项目进行应用, 这样可以快速入门推荐,知识和工程能够两手抓!
当然,这个数据集由于太大,我这边电脑无法直接跑,我依然是采用了一些策略进行采样,选择出了一份比较规整的数据集,20000用户的100多万的历史点击, 做实验用也足够了,小本子也能跑起来。 关于数据集以及处理方式, 可以见dataset目录。
模型简介
初始学习的时候, 是参考王喆老师《深度学习推荐系统》这本书, 围绕着王喆老师梳理的模型框架进行的学习和整理,目前梳理的整体模型解读框架及进展:
- 传统的推荐算法模型(已完成)
- 深度学习时代的算法模型(王喆老师书上的已经完成,目前是在做拓展), 这块后面的话就是继续追工业上经典且实用的模型做解读
- 上面的模型大部分都是CTR的精排部分的模型, 所以后面会加入召回模块的经典模型, 多任务的经典模型,多目标的经典模型,序列推荐的经典模型等等
后面的整理内容会按照上面整理的思维导图进行扩充,并且把之前整理的模型大体上分下类, 后面整理的时候, 主要分精排模型和召回模型,分别放到两个目录里面, 并且在复现代码上也进行优化, 每个模型尽量给出三个版本的代码:
- TensorFlow和Pytorch的两款简易版代码,这个主要是为了看清楚模型结构,从细节上把握模型的前向传播逻辑, 并且还能学习两种框架
- 最后一版代码,是如何使用deepctr或者deepmatch的模型调包版本, 这两个库写的非常优秀,功能齐全,所以真实应用的时候,可以直接调包去完成任务,主要是从使用的角度去完成一些其他方面策略的实验,比如特征工程, 损失函数这种不改模型结构的。
主要模型如下:
召回或粗排侧
基于内容的推荐算法
这是一种比较简单的推荐方法,基于内容的推荐方法是非常直接的,它以物品的内容描述信息为依据来做出的推荐,本质上是基于对物品和用户自身的特征或属性的直接分析和计算。例如,假设已知电影A是一部喜剧,而恰巧我们得知某个用户喜欢看喜剧电影,那么我们基于这样的已知信息,就可以将电影A推荐给该用户。具体实现步骤:
- 构建物品画像(主要包括物品的分类信息,标题, 各种属性等等)
- 构建用户画像(主要包括用户的喜好, 行为的偏好, 基本的人口学属性,活跃程度,风控维度)
- 根据用户的兴趣, 去找相应的物品, 实施推荐。
筋斗云: AI上推荐 之 基于内容的推荐(ContentBasedRecommend)
协同过滤算法
协同过滤算法, 虽然这个离我们比较久远, 但它是对业界影响力最大, 应用最广泛的一种经典模型, 从1992年一直延续至今, 尽管现在协同过滤差不多都已经融入到了深度学习,但模型的基本原理依然还是基于经典协同过滤的思路, 或者是在协同过滤的基础上进行演化, 所以这个算法模型依然有种“宝刀未老”的感觉, 掌握和学习非常有必要。主要有下面两种算法:
- 基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
- 基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
筋斗云:AI上推荐之协同过滤
隐语义模型与矩阵分解
协同过滤的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型, 但是也存在一些问题, 第一个就是处理稀疏矩阵的能力比较弱, 所以为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力, 从协同过滤中衍生出矩阵分解模型(Matrix Factorization,MF), 并发展出了矩阵分解的分支模型。在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
FM+FFM模型
FM模型是2010年提出, FFM模型是2015年提出, 这两个属于因子分解机模型族, 在传统逻辑回归的基础上, 加入了二阶部分, 使得模型具备了特征组合的能力,逻辑回归是一个简单、直观、应用的模型, 但是局限性就是表达能力不强, 无法进行特征交叉和特征筛选等, 因此为了解决这个问题, 推荐模型朝着复杂化发展, GBDT+LR的组合模型就是复杂化之一, 通过GBDT的自动筛选特征加上LR天然的处理稀疏特征的能力, 两者一结合初步实现了推荐系统特征工程化的开端。 其实, 对于改造逻辑回归模型, 使其具备交叉能力的探索还有一条线路, 就是POLY2->FM->FFM, 这条线路在探索特征之间的两两交叉, 从开始的二阶多项式, 到FM, 再到FFM, 不断演化和提升。
NeuralCF 模型
Neural CF是2017年新加坡国立大学的研究人员提出的一个模型, 提出的动机就是看着MF的内积操作比较简单, 表达能力不强, 而此时正是深度学习的浪潮啊, 所以作者就用一个“多层的神经网络+输出层”替换了矩阵分解里面的内积操作, 这样做一是让用户向量和物品向量做更充分的交叉, 得到更多有价值的特征组合信息。 二是引入更多的非线性特征, 让模型的表达能力更强。
筋斗云: AI上推荐 NCF模型
精排侧
GBDT+LR模型
2014年Facebook提出的一个模型,协同过滤和矩阵分解同属于协同过滤家族, 之前分析过这协同过滤模型存在的劣势就是仅利用了用户与物品相互行为信息进行推荐, 忽视了用户自身特征, 物品自身特征以及上下文信息等,导致生成的结果往往会比较片面。 而今天的这两个模型是逻辑回归家族系列, 逻辑回归能够综合利用用户、物品和上下文等多种不同的特征, 生成较为全面的推荐结果。GBDT+LR模型利用GBDT的”自动化“特征组合, 使得模型具备了更高阶特征组合的能力,被称作特征工程模型化的开端。
筋斗云:AI上推荐 之 逻辑回归模型与GBDT+LR(特征工程模型化的开端)
DeepCrossing模型
该模型是2016年微软提出的一个模型, 是一次深度学习框架在推荐系统中的完整应用, 该模型完整的解决了从特征工程、稀疏向量稠密化, 多层神经网络进行优化目标拟合等一系列深度学习在推荐系统中的应用问题, 为后面研究打下了良好的基础。 DeepCrossing没有引入特殊的模型结构, 只是常规的Embedding+多层神经网络。但这个网络模型的出现, 有革命意义。 DeepCrossing模型中没有任何人工特征工程的参与, 只需要清洗一下, 原始特征经Embedding后输入神经网络层, 自主交叉和学习。 相比于FM, FFM只具备二阶特征交叉能力的模型, DeepCrossing可以通过调整神经网络的深度进行特征之间的“深度交叉”, 这也是Deep Crossing名称的由来。
筋斗云:AI上推荐 之 AutoRec与Deep Crossing模型(改变神经网络的复杂程度)
Product-based Neural Networks模型
该模型是2016年上海交大团队提出的一个模型, PNN模型在输入、Embedding层, 多层神经网络及最后的输出层与DeepCrossing没有区别, 唯一的就是Stacking层换成了这里的Product层。该模型的提出是为了研究特征之间的交叉方式, DeepCrossing模型是加深了网络的层数, 但是不同特征的embedding向量它统一放入了一个全连接层里面去学习, 这可能会丢失掉一些信息, 比如可能有特征之间一点关系也没有, 有特征之间关系非常相似, 这种在DeepCrossing之中是没法学习到的。 所以PNN 模型用了Product层替换了原来的stacking层, 在这里面主要就是两两特征的外积和内积交叉。
Wide&Deep Networks
这是谷歌在2016年提出的一个经典模型, 该模型在深度学习的模型中处在了非常重要的地位,它将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。Wide&Deep这种线性模型与DNN的并行连接模式,后来成为推荐领域的经典模式, 奠定了后面深度学习模型的基础。该模型取得成功的关键在于它的两个特色:
- 抓住业务问题的本质特点, 能够融合传统模型的记忆能力和深度模型的泛化能力
- 结构简单, 容易在工程上实现,训练和部署
筋斗云:AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)
Deep&Cross NetWork(DCN)
这是2017年, 斯坦福大学和谷歌的研究人员在ADKDD会议上提出的模型, 该模型针对W&D的wide部分进行了改进, 因为Wide部分有一个不足就是需要人工进行特征的组合筛选, 过程繁琐且需要经验, 2阶的FM模型在线性的时间复杂度中自动进行特征交互,但是这些特征交互的表现能力并不够,并且随着阶数的上升,模型复杂度会大幅度提高。于是乎,作者用一个Cross Network替换掉了Wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 通过与Deep部分相结合,构成了深度交叉网络(Deep & Cross Network),简称DCN。Deep&Cross的设计思路相比于W&D并没有本质上的改变,但是Cross交叉网络的引进使得模型的记忆部分的能力更加强大了。
筋斗云:AI上推荐 之 Wide&Deep与Deep&Cross模型(记忆与泛化并存的华丽转身)
DeepFM Networks
这是2017年哈工大和华为公司联合提出的一个模型,CTR预测任务中, 高阶和低阶特征的学习都非常的重要, 线性模型虽然简单,但是没法学习交叉特征且特征工程是个经验活,而FM考虑了低阶交叉, 深度学习模型有着天然的学习特征之间高阶交叉的能力,但是有些深度学习模型却忽略了只顾着学习泛化而忽略了记忆能力,也就是他们一般学习了特征之间的高阶交叉信息而忽略了低阶交叉的重要性。 比如PNN, FNN, 等。 D&W模型架构同时考虑了记忆和泛化,但是wide的部分需要进行特征工程, 所以为了去掉特征工程的繁琐细节,实现一个端到端的CTR预测模型,也为了同时兼顾低阶和高阶交叉特征信息的学习, 该paper,作者提出了DeepFM模型, 这个模型基于了W&D模型,组合了FM和DNN, 把FM的低阶交叉和DNN的高阶交叉学习做到了各司其职且物尽其用,最后做了很多的对比实验证明了该模型要比之前的LR, FM, PNN, FNN, W&D等模型都要好。DeepFM的思路还是很简单的, 但是起的作用也是非常大的, 所以感觉也是一个非常经典的深度组合模型了。
筋斗云:AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现)
NFM Networks
这是2017年由新加坡国立大学的何向南教授等人在SIGIR会议上提出的一个模型, 主要是针对FM的一些不足进行改进,主要包括线性模型的局限以及无法进行高阶特征交叉,所以作者认为FM无法胜任生活中各种具有复杂结构和规律性的真实数据,尽管当前有了各种FM的变体改进,但仍然局限于线性表达和二阶交互。所以作者在这里提出了一种将FM融合进DNN的策略,通过一个核心结构特征交叉池化层,使得FM与DNN进行了完美衔接,这样就组合了FM的建模低阶特征交互能力和DNN学习高阶特征交互和非线性的能力,得到了NFM模型。由于FM可以在底层学习更多的特征交互信息,这样在DNN学习高阶交互的时候,用比较简单的结构就可以学习到,所以NFM模型不仅兼顾了低阶和高阶特征学习, 线性和非线性学习,并且训练效率和速度上也也比之前的W&D或者Deep Crossing等模型好。该模型还有一个较大的优势就是适合高维稀疏的数据场景。
筋斗云:AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现)
AFM Networks
这个是2017年浙江大学和新加坡国立大学研究员提出的一个模型, 依然来自何向南教授的团队, 这篇文章又使用了一个新的结构Attention对传统的FM进行改进, FM非常擅长学习特征之间的二阶交互, 但是存在的一个问题就是FM把所有交互的特征同等的对待, 即认为这些交互特征对于预测目标来说的重要程度一样, 这个在作者看来是FM的一个缺点所在, 所以使用了Attention结构来改进FM, 通过一个注意力网络对于每个特征交互根据对预测结果的重要程度进行了加权, 进一步增强了模型的表达,并且也增加了模型的可解释性。这个模型可以看做是NFM的延伸, 和NFM是从两个不同的方向改进了FM, 但是又可以结合起来, 因为这个模型就是在NFM的基础上, 在特征交叉层与池化层之间加入了一个注意力网络对特征交叉层的交互特征进行了加权,然后进入了池化层。 不过这次AFM这里没有在池化层后面加入DNN了。本篇文章最大的创新就是注意力网络, 使得特征交互有了一个重要性区分, 更加符合真实的业务场景。
筋斗云:AI上推荐 之 AFM与DIN模型(当推荐系统遇上了注意力机制)
eXtreme DeepFM模型
xDeepFM是2018年中科大联合微软在KDD上提出的一个模型,这个模型的改进出发点依然是如何更好的学习特征之间的高阶交互作用,从而挖掘更多的交互信息。而基于这样的动机,作者提出了又一个更powerful的网络来完成特征间的高阶显性交互,这个网络叫做 这个网络叫做CIN(Compressed Interaction Network),这个网络也是xDeepFM的亮点或者核心创新点了。xDeepFM的模型架构依然是w&D结构,更好的理解方式就是用这个CIN网络代替了DCN里面的Cross Network, 这样使得该网络同时能够显性和隐性的学习特征的高阶交互(显性由CIN完成,隐性由DNN完成)。
筋斗云:AI上推荐 之 xDeepFM模型(显隐性高阶特征交互的组合策略)
Deep Interest Networks
这是2018年阿里在KDD上的一个模型, DIN模型是基于真实的业务场景搞的, 解决的痛点是深度学习模型无法表达用户多样化的兴趣。 它可以通过考虑【给定的候选广告】和【用户的历史行为】的相关性,来计算用户兴趣的表示向量。具体来说就是通过引入局部激活单元,通过软搜索历史行为的相关部分来关注相关的用户兴趣,并采用加权和来获得有关候选广告的用户兴趣的表示。与候选广告相关性较高的行为会获得较高的激活权重,并支配着用户兴趣。该表示向量在不同广告上有所不同,大大提高了模型的表达能力。 这个模型我一直在强调应用场景, 是因为并不是任何时候都适合这个模型的,很大一个前提是丰富的用户历史行为数据。
筋斗云:AI上推荐 之 AFM与DIN模型(当推荐系统遇上了注意力机制)
Deep Interest Evolution Network
DeepInterestEvolutionNetwork(深度进化网络)是阿里2019年提出的模型, 是上一个DIN的演化版本。 该模型的创新点就是“兴趣进化网络”, 在这里面用序列模型模拟了用户兴趣的进化过程,能模拟用户的演化过程在很多推荐场景中是非常重要的。于是乎,为了更好的利用序列信息, 该网络进行了序列模型与推荐系统的尝试,最后形成了这样一个能动态模拟用户兴趣变化的一个网络机制。 这个网络机制主要分为兴趣提取层和兴趣演化层, 兴趣提取层干的事情就是从连续的用户行为中提取一系列的兴趣动态, 使用了GRU网络并提出了新的一种训练网络的方法。 兴趣进化层通过与注意力机制结合, 使得模型能够更有针对性的模拟与目标广告相关的兴趣进化路径。在兴趣进化层部分, 提出了一种新的结构单元AUGRU,就是在原来GRU的基础上,改变了更新门的计算方式。 这就是整个网络的核心内容了。
筋斗云:AI上推荐 之 DIEN模型(序列模型与推荐系统的花火碰撞)
Deep Session Interest Network
DSIN阿里2019年提出的新模型,全称是Deep Session Interest Network(深度会话兴趣网络), 重点在这个Session上,这个是在DIEN的基础上又进行的一次演化,这个模型的改进出发点依然是如何通过用户的历史点击行为,从里面更好的提取用户的兴趣以及兴趣的演化过程,DSIN从行为序列的组成结构会话的角度去进行用户兴趣的提取和演化过程的学习,在这个过程中用到了一些新的结构,比如Transformer中的多头注意力,比如双向LSTM结构, 再比如前面的局部Attention结构。 主要分为会话兴趣分割层,会话兴趣提取层,会话兴趣交互层以及局部激活。
筋斗云:AI上推荐 之 DSIN模型(阿里DIEN之上的再探索,Transformer来了)
FiBiNet模型
FiBiNET(Feature Importance and Bilinear feature Interaction)是2019年发表在RecSys(ACM组织的在推荐系统领域的专会)的模型,来自新浪微博张俊林老师的团队。 这个模型如果从模型演化的角度来看, 主要是在特征重要性以及特征之间交互上做出了探索, 主要是通过SENET layer对不同的特征,根据对预测目标的重要性进行加权, 另外一个就是在特征embedding交互上面提出了一种双线性特征交互的方式, 文章简单明了,通俗易懂。
筋斗云:AI上推荐 之 FiBiNET模型(特征重要性选择与双线性特征交叉)
AutoInt模型
AutoInt(Automatic Feature Interaction),这是2019年发表在CIKM上的文章,这里面提出的模型,重点也是在特征交互上,而所用到的结构,就是大名鼎鼎的transformer结构了,也就是通过多头的自注意力机制来显示的构造高阶特征,有效的提升了模型的效果。所以这个模型的提出动机比较简单,和xdeepFM这种其实是一样的,就是针对目前很多浅层模型无法学习高阶的交互, 而DNN模型能学习高阶交互,但确是隐性学习,缺乏可解释性,并不知道好不好使。而transformer的话,我们知道, 有着天然的全局意识,在NLP里面的话,各个词通过多头的自注意力机制,就能够使得各个词从不同的子空间中学习到与其它各个词的相关性,汇聚其它各个词的信息。 而放到推荐系统领域,同样也是这个道理,无非是把词换成了这里的离散特征而已, 而如果通过多个这样的交叉块堆积,就能学习到任意高阶的交互啦。这其实就是本篇文章的**核心。
筋斗云: AI上推荐 之 AutoInt模型(Transformer开始玩特征交互))
特别说明
关于这里还得特别说明下, 整理这些模型的目的是为了能够更清楚的了解每个模型的具体计算细节和原理, 只是单纯学习使用, 不能作任何商业用途
代码+博客解读的方式我觉得能够更加帮大家认识到各个模型的精髓,以及模型的演化过程,我觉得看完每个模型的解读和代码之后,至少要明白三个问题:
- 这个模型提出是为了解决什么问题?
- 通过用什么样的方法解决问题?
- 这个方法具体是怎么实现的(代码层次)?
最终的升华就是拔高一层,去把握思路,比如特征重要性选择会有哪些思路? 特征交叉上会有哪些思路? 处理序列数据上会有哪些思路等? 有哪些通用的比较好的模型结构等等。 我觉得这些问题要比单独的模型要重要多,这也是我坚持把模型串联到一块的原因。
另外,就是这些模型的代码都是采用了最简单的实现方式说明原理用的,采用的数据也没有刻意仿照原论文, 原因就是我觉得推荐领域是非常和场景强相关的, 所以用这样简单的数据去对比各个模型的好坏没有意义,所以大家也不要刻意去复现原论文或者我这里的实验结果,**才是最关键的,具体使用的时候就会发现会有各种工具包,人大佬都帮我们实现好了,不用重复造轮子啦。 但这种想问题的方式可是需要我们用心一点点去积累的, 所以这个项目的初心就是希望能通过这样的方式把比模型更重要的东西沉淀下来,既是对自己的一个考验,又是自己的兴趣,也希望能帮助到更多的伙伴啦