- Problem Domain .
- Extractive and Abstractive summarization
- Architecture overview
- References
- Future Scope
Every day, people rely on a wide variety of sources to stay informed -- from news stories to social media posts to search results. Being able to develop Machine Learning models that can automatically deliver accurate summaries of longer text can be useful, for digesting such large amounts of information in a compressed form, could be useful in many fields
One approach to summarization is to extract parts of the document that are deemed interesting by some metric (for example, inverse-document frequency) and join them to form a summary. Algorithms of this flavor are called extractive summarization. Original Text: Alice and Bob took the train to visit the zoo. They saw a baby giraffe, a lion, and a flock of colorful tropical birds. Extractive Summary: Alice and Bob visit the zoo. saw a flock of birds. Above we extract the words bolded in the original text and concatenate them to form a summary. As we can see, sometimes the extractive constraint can make the summary awkward or grammatically strange.
Another approach is to simply summarize as humans do, which is to not impose the extractive constraint and allow for rephrasings. This is called abstractive summarization. Abstractive summary: Alice and Bob visited the zoo and saw animals and birds. In this example, we used words not in the original text, maintaining more of the information in a similar amount of words. It’s clear we would prefer good abstractive summarizations, but how could an algorithm begin to do this?
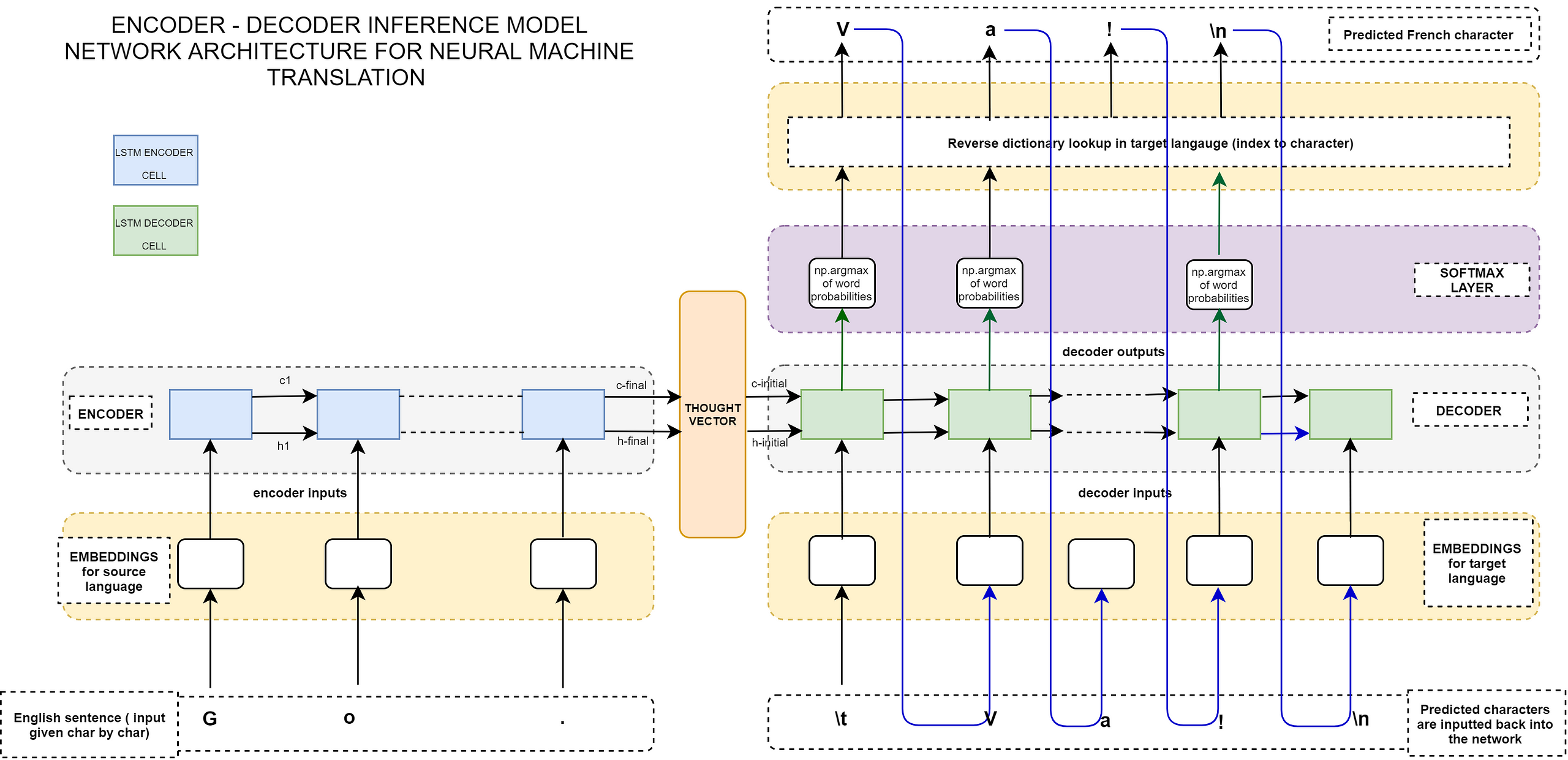
Encoder decoder model specifications :
- word representations : Glove, Alternatives : word2vec, universal sentence encoder, ELMO
- vocab size = 10000
- maximum text length = 22
- summary length = 9
- embedding size = 200
- batch size = 2096
- numner of epochs = 15
- time taken for each epoch = 1300 sec approx
- RNN units = CuDNNLSTM
- seq2seq Bidrectional LSTM Encoder with unidirectional decoder using Glove embeddings
- Data set :1M samples of kindle reviews and summaries link : https://www.kaggle.com/bharadwaj6/kindle-reviews
https://arxiv.org/pdf/1409.3215.pdf
- Training for more epochs
- Increasing batch size
- Implementing Attention Mechanism
- Trying other word/sentence embeddings