本项目是基于VGG-Speaker-Recognition开发的,本项目主要是用于声纹识别,也有人称为说话人识别。本项目包括了自定义数据集的训练,声纹对比,和声纹识别。
本教程源码:https://github.com/yeyupiaoling/Kersa-Speaker-Recognition
本项目使用的是Python 3.7,Keras2.3.1和Tensorflow1.15.3,音频处理使用librosa库,安装方法如下。
1、安装Tensorflow GPU版本,CUDA为10.0,CUDNN为7。
pip install tensorflow-gpu==1.15.3 -i https://mirrors.aliyun.com/pypi/simple/2、安装Keras。
pip install keras==2.3.1 -i https://mirrors.aliyun.com/pypi/simple/3、安装librosa库,最简单的方式就是使用pip命令安装,如下。如安装的是librosa 0.6.3--0.7.2,依赖的是numba0.49.0,源码安装的时候要留意,否者会报错No module named numba.decorators。
pip install pytest-runner
pip install librosa如果pip命令安装不成功,那就使用源码安装,下载源码:https://github.com/librosa/librosa/releases/, windows的可以下载zip压缩包,方便解压。
pip install pytest-runner
tar xzf librosa-<版本号>.tar.gz 或者 unzip librosa-<版本号>.tar.gz
cd librosa-<版本号>/
python setup.py install如果出现libsndfile64bit.dll': error 0x7e错误,请指定安装版本0.6.3,如pip install librosa==0.6.3
如果出现audioread.exceptions.NoBackendError错误,解决方法如下。
Windows: 安装ffmpeg, 下载地址:http://blog.gregzaal.com/how-to-install-ffmpeg-on-windows/,笔者下载的是64位,static版。
然后到C盘,笔者解压,修改文件名为 ffmpeg,存放在 C:\Program Files`目录下,并添加环境变量 C:\Program Files\ffmpeg\bin`
最后修改源码,路径为C:\Python3.7\Lib\site-packages\audioread\ffdec.py,修改32行代码,如下:
COMMANDS = ('C:\\Program Files\\ffmpeg\\bin\\ffmpeg.exe', 'avconv')Linux: 安装ffmpeg。
sudo add-apt-repository ppa:djcj/hybrid
sudo apt-get update
sudo apt-get install ffmpeg 配置环境变量。
export PATH=/usr/bin/ffmpeg:${PATH}4、其他的依赖库自行安装。
本节介绍自定义数据集训练,如何不想训练模型,可以直接看下一节,使用官方公开的模型进行声纹识别。
自定义数据列表格式如下,前面是音频的相对路径,后面的是该音频对应的说话人的标签,就跟分类一样。
dataset/ST-CMDS-20170001_1-OS/20170001P00001A0119.wav 0
dataset/ST-CMDS-20170001_1-OS/20170001P00001A0120.wav 0
dataset/ST-CMDS-20170001_1-OS/20170001P00001I0001.wav 1
dataset/ST-CMDS-20170001_1-OS/20170001P00001I0002.wav 1
dataset/ST-CMDS-20170001_1-OS/20170001P00001I0003.wav 1
1、本项目默认是支持Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30,aidatatang_200zh,CN-Celeb,VoxCeleb2这6个数据集的,需要把他们下载并解压到dataset目录下,有一点要注意的是,VoxCeleb2非常大,建议使用,其他的数据集选择性使用。VoxCeleb2数据集解压之后,把训练集和测试集里的aac目录下的文件夹都放在同一个VoxCeleb2目录下,他们的下载地址如下。
- Aishell:http://www.openslr.org/resources/33
- Free ST-Chinese-Mandarin-Corpus:http://www.openslr.org/resources/38
- THCHS-30:http://www.openslr.org/resources/18
- THCHS-30:http://www.openslr.org/resources/18
- aidatatang_200zh:http://www.openslr.org/resources/62
- CN-Celeb:http://www.openslr.org/resources/82
- VoxCeleb2:http://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox2.html
2、下载并解压完成之后,执行create_data.py生成数据列表,如何读者有其他自定义的数据集,可以参考这个文件中的代码,生成自己数据集的数据列表,其中delete_error_audio()函数是检查数据是否有错误或者过短的,这个比较耗时,如果读者能够保证数据没有问题,可以跳过这个函数。
在执行训练之前,可能需要修改train.py中的几个参数。
gpu是指定是用那个几个GPU的,如何多卡的情况下,最好全部的GPU都使用上。resume这个是用于恢复训练的,如何之前有训练过的模型,可以只用这个参数指定模型的路径,恢复训练。batch_size根据自己显存的大小设置batch的大小。n_classes是分类数量,这个可以查看上一步生成数据列表最后一个得到分类数量,但也记得加1,因为label是从0开始的。multiprocess这个参数是指定使用多少个线程读取数据,因为读取音频需要比较慢,训练默认也是使用4个多线程训练的,所以如果使用多线程读取数据,就不要使用多线程读取数据,否则反之,Ubuntu下最好使用多线程读取数据。但是Windows不支持多个线程读取数据,在Windows下必须是0。net参数是指定使用的模型,有两种模型可以选择,较小的resnet34s,和较大的resnet34l。
最后执行train.py开始训练,在训练过程中,每一步都会保存模型,同时也使用Tensorboard记录训练的logs信息。
使用训练完成的模型,或者是官方提供的模型,笔者这里提供了国内的下载:点击下载,把模型存放在pretrained目录下。
本项目提供三种预测方案:
- 第一种是声纹对比
predict_contrast.py,即对比两个音频的声纹相似度,其中参数audio1_path和audio2_path就是需要对比的音频路径,其他的参数需要跟训练的一致。 - 第二种是录音识别
predict_recognition.py,即通过录音识别说话的人属于声纹库中的那个,并输出说话人的名称和跟声纹库对比的相识度,同样其他的参数需要跟训练的一致。 - 第三种是服务接口方式
predict_server.py,即通过HTTP提供接口,通过网络请求注册或者识别声纹,还有也提供了在线录音识别的页面,但是在线录音只能在localhost下使用,否则只能是HTTPS协议才能调用chrome浏览器的录音功能。
声纹对比:

录音声纹识别:

页面:
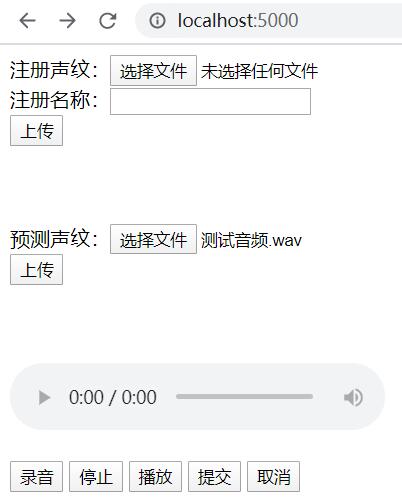
启动日志:
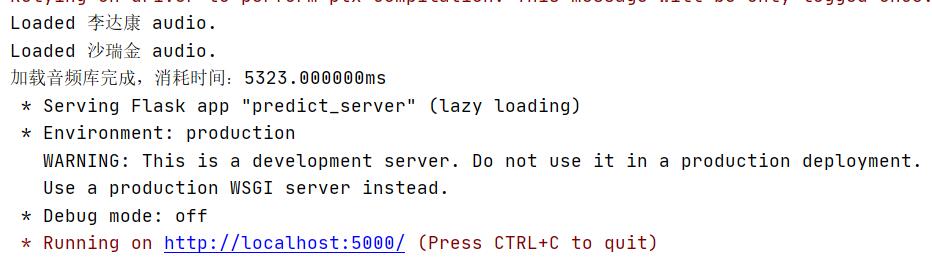
录音识别结果:

在线播放录音:
| 模型 | 下载地址 | 说明 |
|---|---|---|
| 官方提供的模型 | 点击下载 | 英文数据集训练 |
| 自训练超大数据集的模型 | 点击下载 | 中英文数据集训练,算力不足,并没有完全训练完 |