-
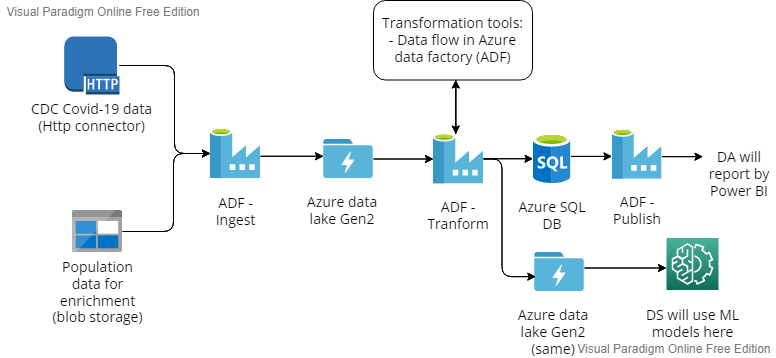
Overview diagram of this project:
-
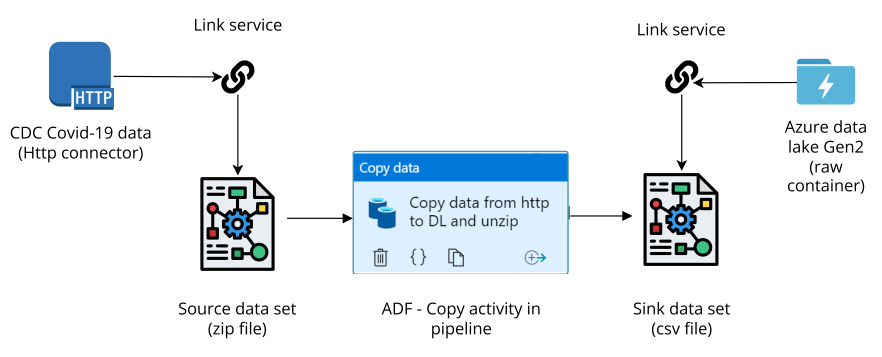
Di chuyển dữ liệu từ link http vào Azure data lake gen2 gồm các thành phần sau:
- Tạo 2 link services, một cái ứng với http connector, một cái ứng với data lake.
- Tạo 2 datasets để định nghĩa schema và các thông tin cần thiết cho dữ liệu chứa bên trong.
- Thao tác COPY trong khi tạo pipeline từ dataset này tới dataset kia.
Từ azure blob tới data lake gen2 tương tự, thay http connector bằng blob connector.
Dữ liệu gồm các tệp csv sau:
- cases_deaths liên quan số ca nhiễm và mất ngày/tuần.
- hospital_admissions là số ca chiếm chỗ hồi sức đặc biệt/chỗ thông thường trong bệnh viện.
- testing liên quan đến số ca được kiểm tra covid, tỉ lệ phát hiện bệnh.
- population cung cấp thông tin về dân số theo từng nhóm tuổi: 0-14, 15-24, 25-49, 50-64,... Ngoài ra:
- dim_country cung cấp thông tin lookup về country_code, dân số các nước.
- dim_date cung cấp thông tin lookup về ngày, tuần trong tháng, trong năm gần đây, đóng vai trò trong việc tạo ra cột year_week sao cho giống định dạng trong các dữ liệu như testing,... cũng như xác định được ngày bắt đầy/kết thúc mỗi tuần.
- Biến đổi các tệp trong data lake:
- Dữ liệu được chứa trong raw container, biến đổi bằng cách tạo 4 pipelines trong Azure Data Factory, rồi ghi vào processed container.
- Dữ liệu cases_and_deaths và hospital_admissions được biến đổi bằng cách tạo Data flow, rồi cho flow đó vào Data pipeline.
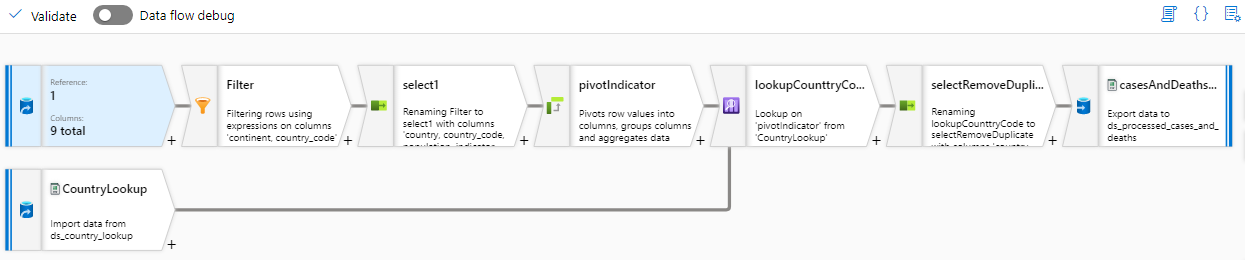
- Data flow cho biến đổi cases_deaths:
- Data flow cho biến đổi hospital_admissions:
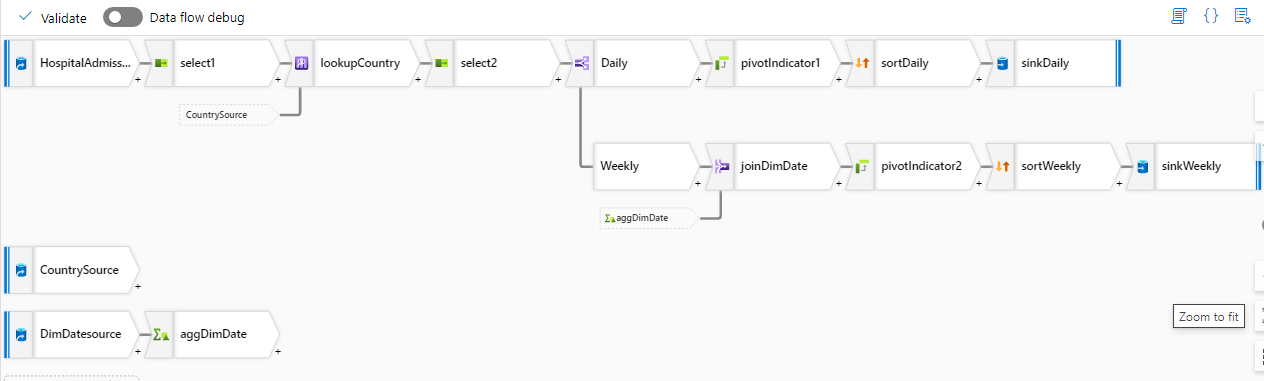
- Data flow cho biến đổi cases_deaths:
- Dữ liệu population và testing được biến đổi bằng Data Bricks Notebook, rồi đặt notebooks đó trong Data pipeline. Chi tiết:
- Data Bricks workspace được tạo, và ta mount các thư mục trong Data lake gen2 vào workspace (xem thư mục Databricks-workspace/set-up)
- Tạo một link services liên kết với workspace đó và dùng Access token được tạo trong workspace để liên kết, sử dụng Databricks cluster để chạy pipeline.
- Viết 2 notebooks để biến đổi dữ liệu population và testing (link).
- Di chuyển dữ liệu đã xử lý vào DWH (ở đây là Azure SQL DB):
- Dữ liệu đã xử lý vừa được lưu ở Data lake và cả Azure SQL DB.
- Tạo Azure SQL DB và viết DDL scripts tương ứng để tạo sẵn các bảng: cases_deaths, hospital_admissions_daily, testing.
- Tạo các pipelines để di chuyển dữ liệu trong processed container vào SQL DB (tạo các link services, datasets cần thiết).
- Điều phối việc thực thi tự động các pipelines:
- Dùng pipline dependency và triggers dependency.
- Video demo