Spider
新浪微博爬虫(Sina weibo spider),百度搜索结果 爬虫
使用方法:
环境:
python 版本 >=python3.5
mysql 版本 >= 5.5.3
pip 版本应与 python 一样
推荐使用虚拟环境:
cd weibo
chmod u+x env.sh
source env.sh
全局安装(不使用虚拟环境):
pip3 install -r requirements.txt
代码运行流程:
有两个爬虫程序 sina_spider.py 和 weibo_spider.py ,区别在于 weibo_spider.py 使用了 selenium ,可以自动登录并且访问网址不容易出现403,但是该程序要慢一些。所以建议首选 sina_spider.py,如果出现403,再改用weibo_spider.py。两个程序爬取的结果是一样的。
- 采用 sina_spider.py 爬取的运行顺序:
0.若是使用的虚拟环境,每次运行前使用
source env.sh命令进入虚拟环境1.首先根据自己的情况修改 conf.yaml ,该文件内有详细说明,关于 uid 和 cookie的获取请见这篇文章
2.然后运行 Create_all.py 创建MySQL表
3.接着运行 sina_spider.py 爬取微博用户资料和动态并保存在数据库中
4.然后分别运行 Data_analysis.py ,LDA_Analysis.py 对数据进行处理
5.得到数据处理结果(默认为 weibo.jpg,weibo_wordfrq.html,weibo_dynamic.html,lda.html)
- 采用 weibo_spider.py 爬取的运行顺序:
0.安装浏览器驱动,请先阅读我的这篇文章
1.若是使用的虚拟环境,每次运行前使用
source env.sh命令进入虚拟环境2.首先根据自己的情况修改 conf.yaml ,该配置文件内有详细说明,不需要cookies,但是需要填写用户名和密码
3.然后运行 Create_all.py 创建MySQL表
4.接着运行 weibo_spider.py 爬取微博用户资料和动态并保存在数据库中
5.然后分别运行 Data_analysis.py ,LDA_Analysis.py 对数据进行处理
6.得到数据处理结果(默认为 weibo.jpg,weibo_wordfrq.html,weibo_dynamic.html,lda.html)
具体说明请见源码。
本项目系列文章
关于本项目代码以及处理的具体思路可以阅读作者的这三篇文章:
更为详细的说明请见源码及注释。
微博用户信息分析
可以爬取微博用户个人资料以及动态信息。
数据分析:
- 生成词云
- 统计词频
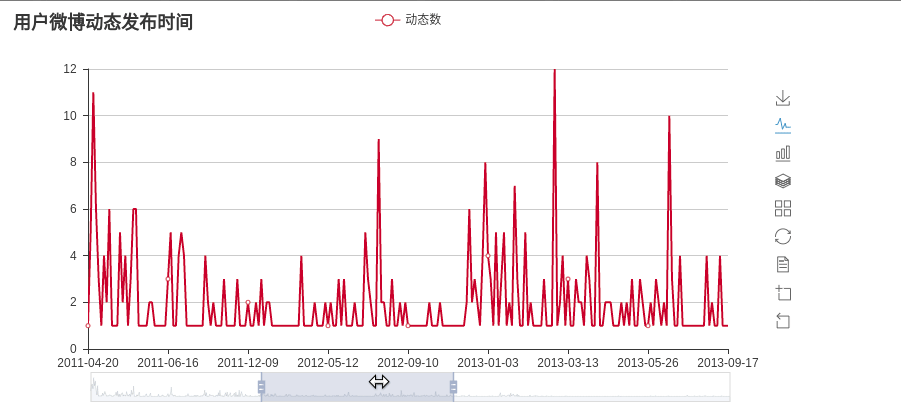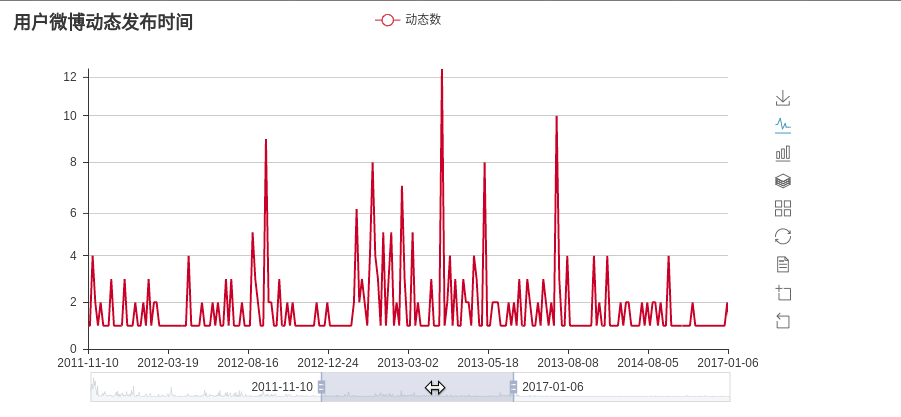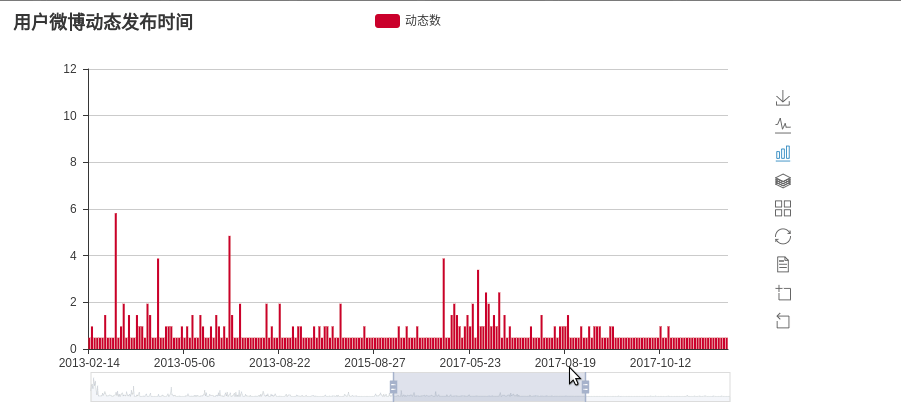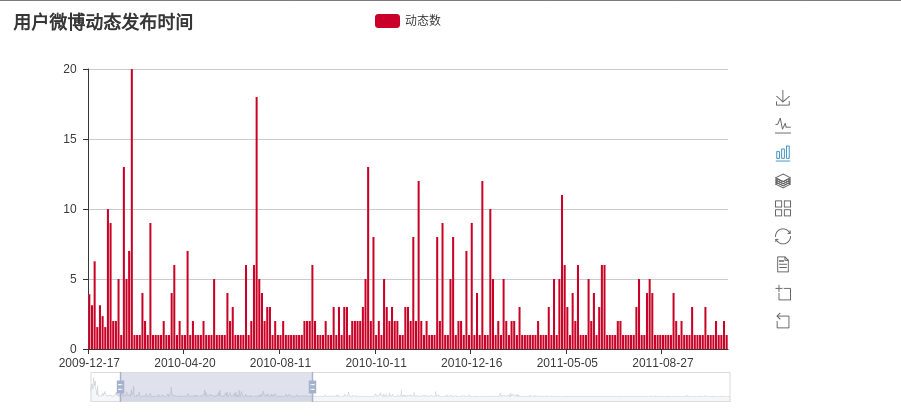
- 统计活跃时间
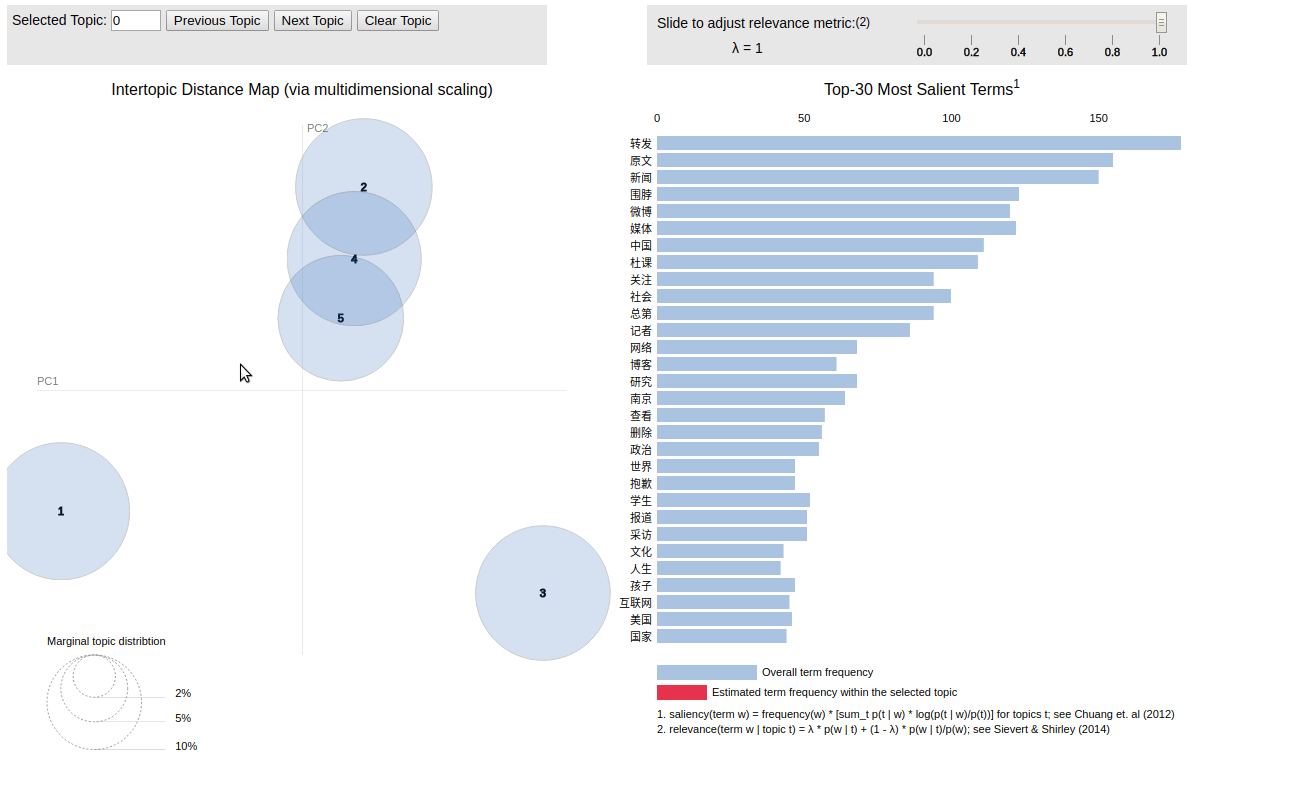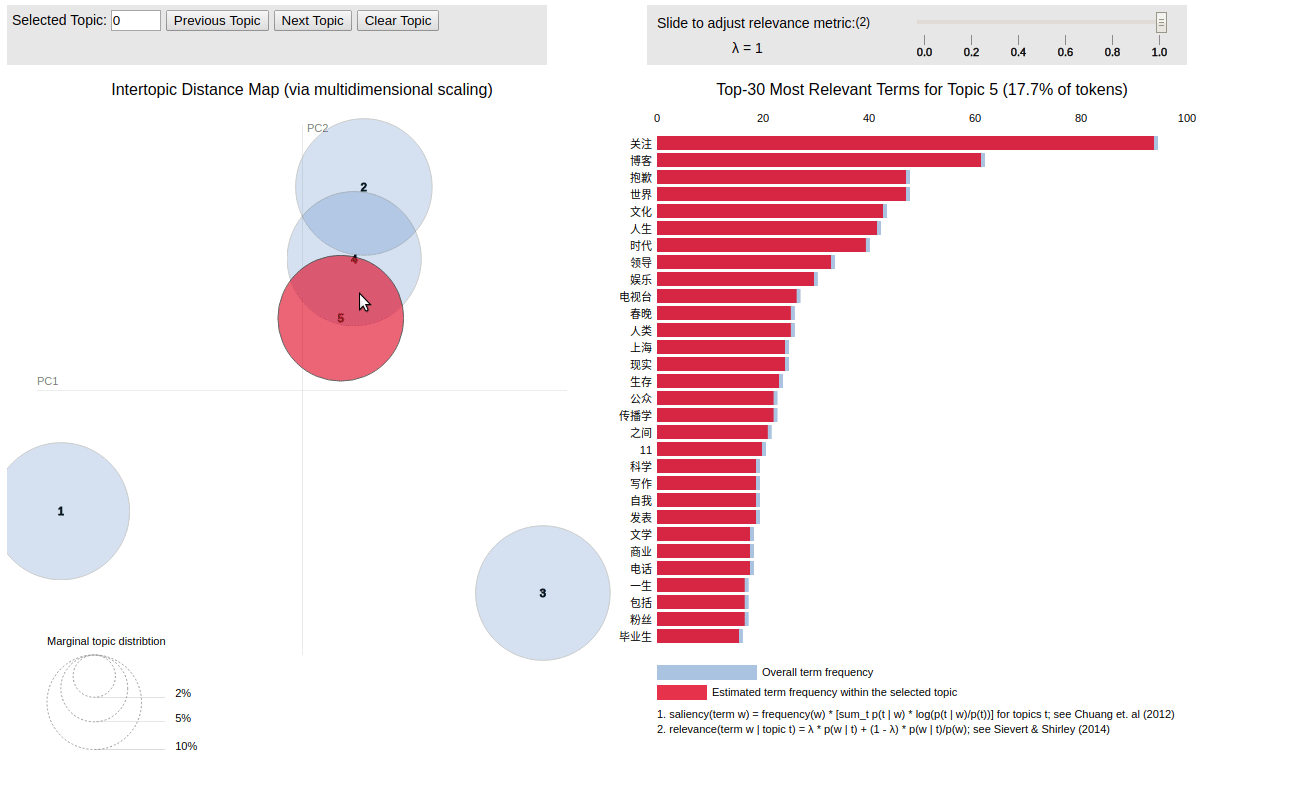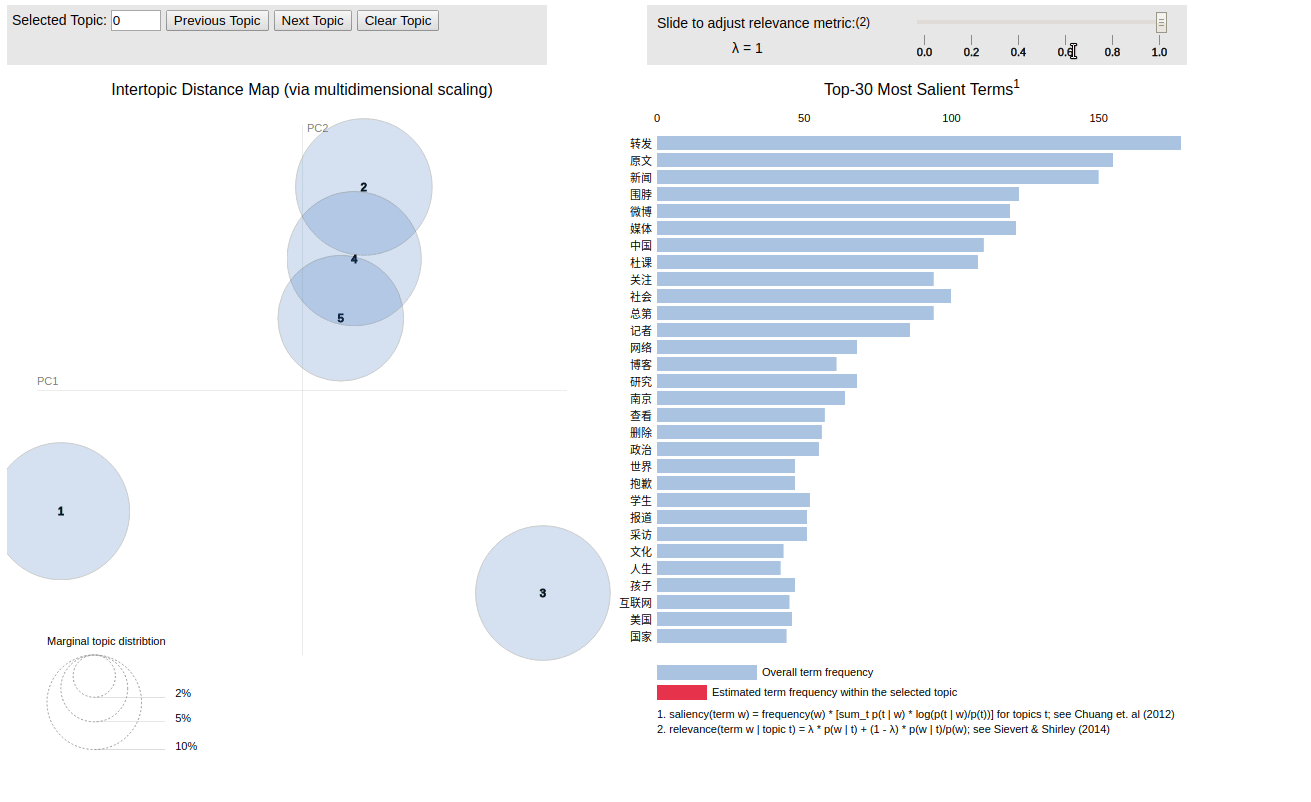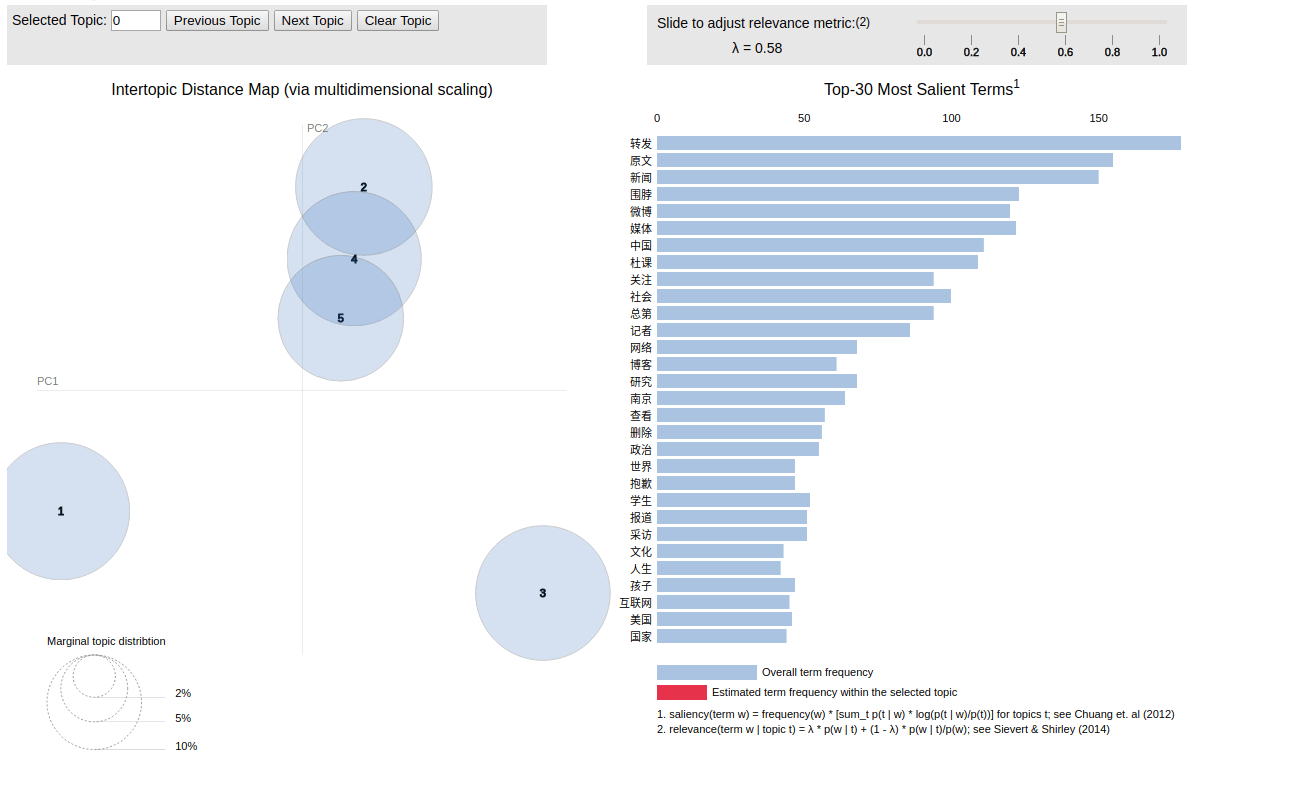
- 使用 LDA 构建了微博主题模型
- 更多功能...
UI:
- 生成良好的UI数据分析与展示界面
更多功能还在开发中,程序也在不断重构中.... 代码行数++
代码结构
├── baidu_result
│ └── baidu_result.py #根据关键词爬取百度搜索结果
├── LICENSE
├── README.md
└── weibo
├── conf.yaml #配置文件
├── Connect_mysql.py #连接数据库
├── Create_all.py #创建MySQL表
├── data_analysis
│ ├── data
│ │ └── stop_words.txt #中文停用词
│ ├── Data_analysis.py #根据微博用户动态进行词云和词频分析
│ ├── HYQiHei-25J.ttf #用于生成中文词云的字体
│ └── LDA_Analysis.py #使用LDA进行微博动态主题建模与分析
├── Delete_users.py #删除不在conf.yaml配置文件中的微博用户及其动态
├── env.sh #该脚本可以使程序运行在虚拟环境中
|── get_cookies.py #模拟登录微博并获取cookies
├── __init__.py
├── requirements.txt #项目依赖文件
├── sina_spider.py #爬取微博用户资料和动态并保存在数据库中(速度快)
└── weibo_spider.py #爬取微博用户资料和动态并保存在数据库中(效果好)
数据分析示例
词云:

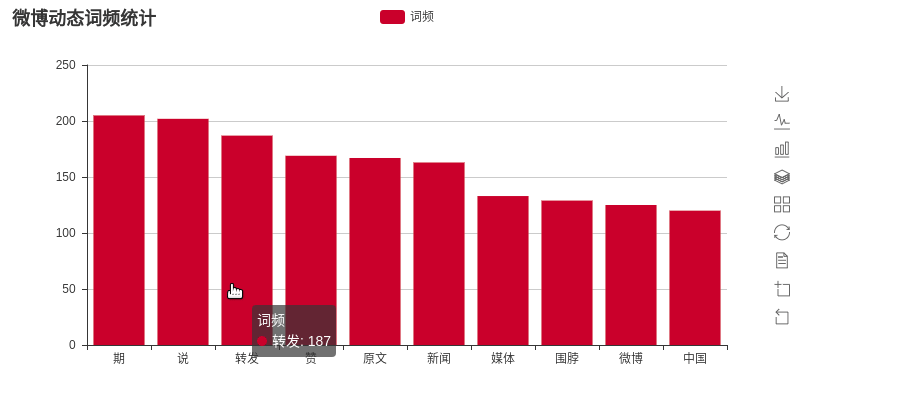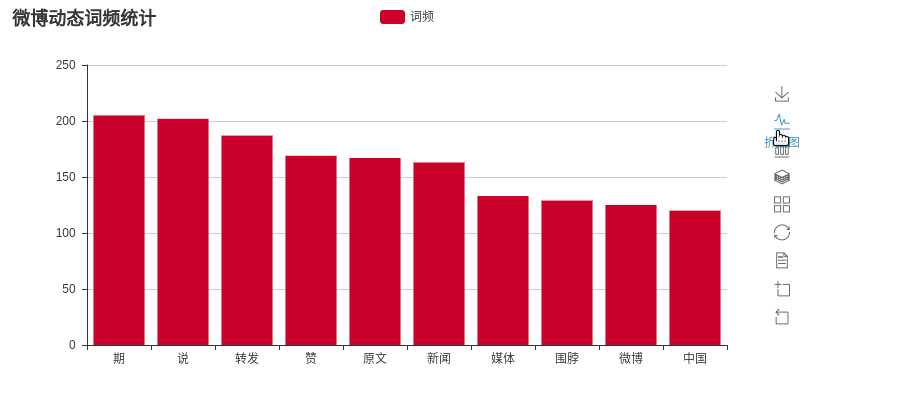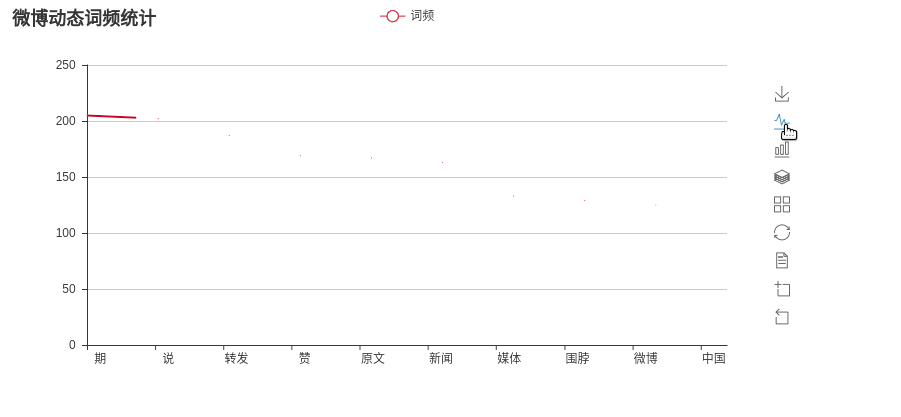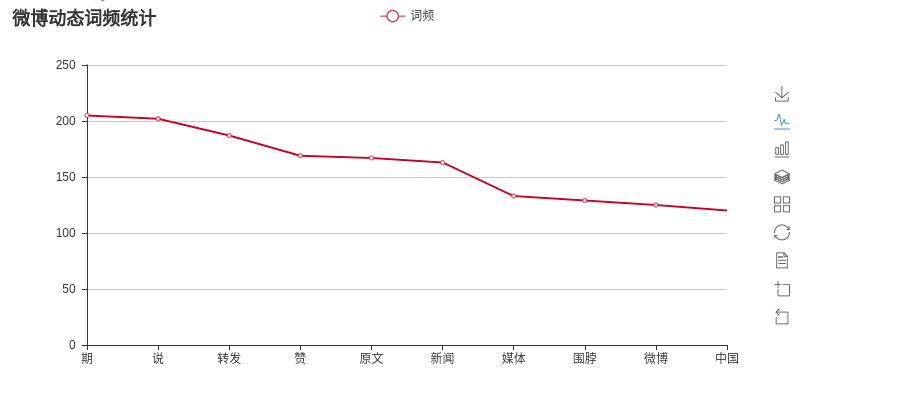
词频分析:
微博动态时间统计:
微博主题分析(LDA):
协议
本项目遵从MIT协议