Table of Contents
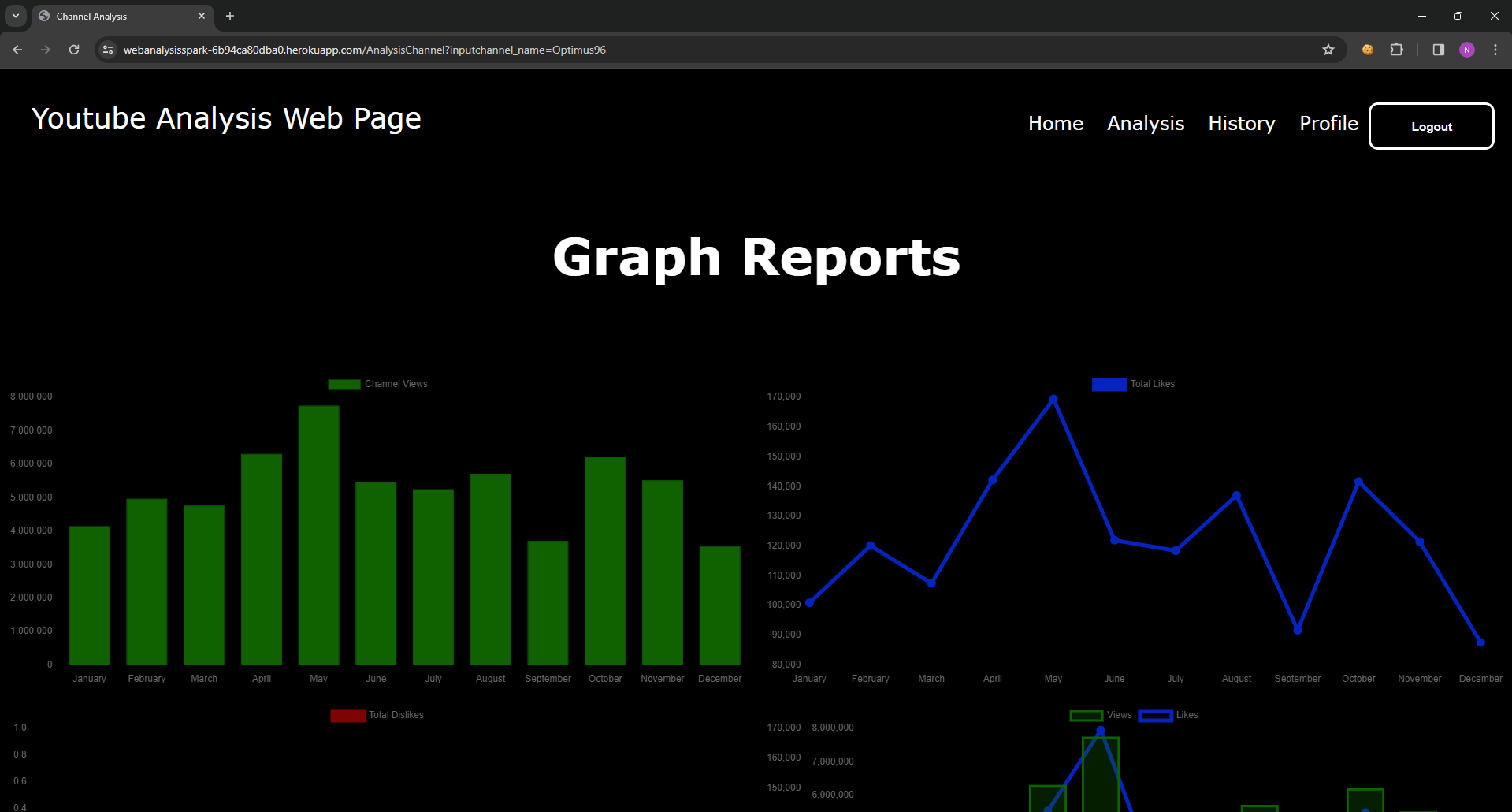
Welcome to our Flask Python web application designed to create insightful summary reports, complete with charts, based on input YouTube usernames. This innovative tool harnesses the power of the YouTube API to collect relevant data and provide users with comprehensive analyses of their channel's performance.
With just a few simple steps, users can input their YouTube username, and our application will swiftly gather essential information, such as views, likes, comments, and more. Leveraging this data, our app generates intuitive charts and graphs that offer valuable insights into the channel's growth, engagement, and audience demographics.
Whether you're a content creator seeking to understand your audience better or a marketing professional aiming to optimize your YouTube strategy, our web app provides actionable intelligence to drive informed decision-making. Our user-friendly interface ensures a seamless experience, allowing users to access detailed reports effortlessly.
Harness the power of data-driven decision-making with our Flask Python web application, and unlock the full potential of your YouTube channel today! 😄 😄 😄
This is an example of how you may give instructions on setting up your project locally. To get a local copy up and running follow these simple example steps.
The Instruction for installing and set up the project locally.
- Before running the code examples, we have to clone the repository to your local machine:
-
Git Clone: Clone the repository to your local machine:
git clone https://github.com/NolanMM/Web_Spark_Analysis_Python.git
- Before running the code examples, make sure you have the virtual enviroment is installed and be ready to use:
We need to create a new
Python 3.11virtual enviroment for this project.
-
If you want to create a new virtual enviroment, you can use the following command in the terminal of the project directory:
- In Windows or Linux, you can use the following command:
python -m venv venv
- Then, you can activate the virtual enviroment by using the following command:
venv\Scripts\activate
- In MacOs, you can use the following command:
python3 -m venv venv
- Then, you can activate the virtual enviroment by using the following command:
source venv/Scripts/activate -
Make sure the virtual environment needed for project is activate with corresponding project directory, you can use the following command:
- In Windows or Linux, you can use the following command:
venv\Scripts\activate
- In MacOs, you can use the following command:
source venv/Scripts/activate -
Install requirements.txt: Automatically installed dependencies that needed for the project:
pip install -r requirements.txt
To use the code examples in this repository, follow these steps:
-
Install the required dependencies as mentioned in the Prerequisites section.
-
Run the following command in the terminal to start the server:
gunicorn app:appTo create the new database for this repository, follow these steps:
-
Double-check if
/instance/SparkWeb.dbfile is existed in the project directory. If yes, delete it. -
Run the
Database_Handle/Create_Table.pyin the terminal to start the server:
python Database_Handle/Create_Table.pyTo create the new database for this repository, follow these steps:
-
Double-check if
/instance/SparkWeb.dbfile is existed in the project directory. If yes, delete it. -
Run the
Database_Handle/Create_Table.pyin the terminal to create new instance of the database for the project:
python Database_Handle/Create_Table.pyTo check all the data and columns with data type in the database of this repository, follow these steps:
-
Double-check if
/instance/SparkWeb.dbfile is existed in the project directory. If not, create a new one by steps above. -
Run the
Database_Handle/DoubleCheckTable.pyin the terminal to clear all the data in the database of the project:
python Database_Handle/DoubleCheckTable.pyTo clear all the data in the database of this repository, follow these steps:
-
Double-check if
/instance/SparkWeb.dbfile is existed in the project directory. If not, create a new one by steps above. -
Run the
Database_Handle/Clear_Table.pyin the terminal to clear all the data in the database of the project:
python Database_Handle/Create_Table.pyBefore running the code examples, make sure you have the following dependencies installed:
-
Flask: A micro web framework written in Python. You can install it via pip:
pip install flask
-
Flask-SqlAlchemy: : An extension for Flask that adds support for SQLAlchemy, a powerful SQL toolkit and Object-Relational Mapping (ORM) library for Python. You can install it via pip:
pip install flask-sqlalchemy
-
Google Youtube APIs: APIs provided by Google for interacting with YouTube services, such as uploading videos, retrieving video metadata, and managing playlists. You can install the Python client library via pip:
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
-
Pyspark: A unified analytics engine for large-scale data processing built on top of Apache Spark. You can install it via pip:
pip install pyspark
-
Gunicorn: A Python WSGI HTTP Server for UNIX. You can install it via pip:
pip install gunicorn
-
Boostrap: Bootstrap is a popular front-end framework for building responsive and mobile-first websites and web applications:
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet">
This is a list of features that we are planning to add in the future:
- Continuous Development on Advanced Analytics
- Instagram and Twitter APIs Integration for Social Media Analytics
- Facebook and LinkedIn APIs Integration for Social Media Analytics
- Implement and improve the test coverage
- Files Downloaded Support
- Improve the User Interface
- Improve the User Experience
- Add more features to the platform
- Improve the performance of the platform
- Language Support
- Vietnamese
Distributed under the MIT License. See LICENSE.txt for more information.
NolanM - Minh Nguyen - @Gmail - minhlenguyen02@gmail.com
Project Link: https://github.com/NolanMM/Web_Spark_Analysis_Python