Is a web spider extension for Google Chrome.
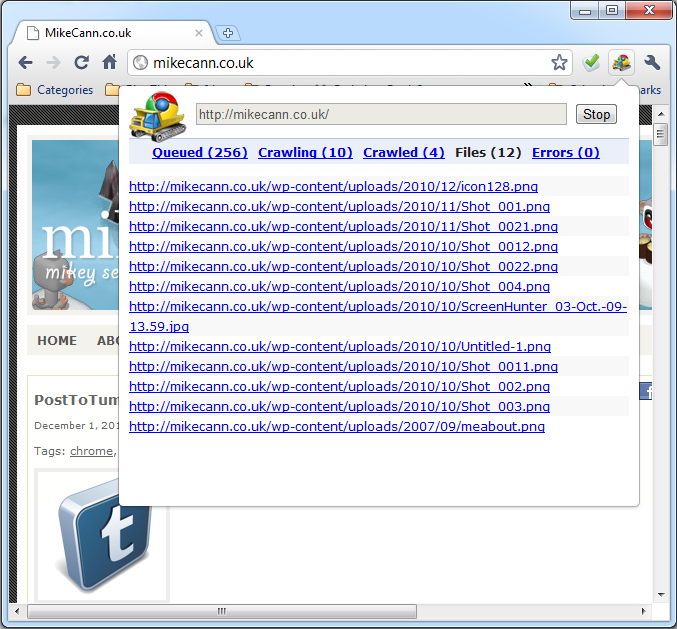
The idea is simple really. You just give it a URL, it then goes off and finds all the links on that page then follows them to more pages then gets all the links and follows them and so on and so on.
Along the way it checks each page to see if there are any ‘interesting’ files linked there, if it finds an interesting link it will flag it for you so you can check it out.
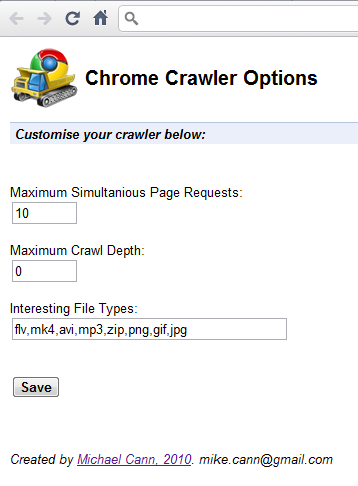
Theres an options page that lets you customise the way it all works:
Grab it on the Chrome Web Store: https://chrome.google.com/webstore/detail/amjiobljggbfblhmiadbhpjbjakbkldd
Find out more on my blog:
- http://mikecann.co.uk/personal-project/chrome-crawler-a-web-crawler-written-in-javascript/
- http://mikecann.co.uk/personal-project/chrome-crawler-v0-4-background-crawling-more/
- http://mikecann.co.uk/personal-project/chrome-crawler-v0-5/
Copyright (C) 2012 by Michael Cann mike.cann@gmail.com
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.