-
인공 신경망 (Artificial Neural Network)의 층을 연속적으로 깊게 쌓아올려 데이터를 학습하는 방식이다.
-
인간이 학습하고 기억하는 매커니즘을 모방한 기계 학습이다.
-
인간은 학습할 때 뇌에 있는 뉴런이 자극을 받아들이며, 자극이 일정 수준 이상이 되면
화학 물질을 통해 다른 뉴런과 연결되며 해당 부분이 발달한다. -
자극이 약하거나 기준치를 넘지 못하면 뉴런은 연결되지 않는다.
-
입력한 데이터가 활성 함수에서 임계점을 넘으면 출력된다.
-
초기 인공 신경망(Perceptron)에서 깊게 층을 쌓아 학습하는 딥 러닝으로 발전한다.
-
딥 러닝은 Input Nodes Layer, Hidden Nodes Layer, Output Nodes Layer의 세 가지 층이 존재한다.

-
가장 단순한 형태의 신경망으로서, Hidden Layer가 없고 Single Layer로 구성되어 있다.
-
퍼셉트론의 구조는 입력 feature와 가중치, Activation Function, 출력 값으로 구성되어 있다.
-
퍼셉트론에서의 가중치는 신경 세포에서 신호를 전달하는 축삭 돌기의 역할을 하며,
입력 값과 가중치는 모두 인공 뉴런(활성 함수)으로 도착한다. -
가중치가 클수록 해당 입력 값이 중요하다는 뜻이고,
인공 뉴런(활성 함수)에 도착한 각 입력 값과 가중치를 곱한 뒤, 그것들의 총 합을 구한다. -
인공 뉴런(활성 함수)은 보통 시그모이드 함수와 같은 계단 함수를 사용하며,
합계를 확률로 변환하고, 이 때 임계치를 기준으로 0 또는 1을 출력한다.

-
로지스틱 회귀 모델이 인공 신경망에서는 하나의 인공 뉴런으로 볼 수 있다.
-
결과적으로, 회귀 모델과 마찬가지로 실제 값과 예측 값의 차이가
최소가 되는 가중치를 찾는 과정이 퍼셉트론의 학습 과정이다. -
최초 가중치를 설정한 뒤, 입력 feature 값으로 예측 값을 계산하고,
실제 값과의 차이를 구한 뒤 이를 줄일 수 있는 방향으로 가중치를 변경한다. -
퍼셉트론의 활성화 정도를 편향(bias)으로 조절할 수 있으며, 편향을 통해 어느 정도의 자극을 미리 주고 시작할 수 있다.
-
뉴런이 활성화되기 위해 필요한 자극이 1,000이라고 가정하면, 500의 입력 값만 받아도 편향을 2로 주어 1,000으로 만들 수 있다.


- 퍼셉트론의 출력 값과 실제 값의 차이를 줄여나가는 방향으로 계속해서 가중치를 변경하며, 이 떄 경사 하강법을 사용한다.

-
경사 하강법 방식은 전체 학습 데이터를 기반으로 계산한다.
-
하지만 입력 데이터가 크고 레이어가 많을수록 그만큼 많은 자원이 소모된다.
-
일반적으로 메모리 부족으로 인해 연산이 불가능하기 때문에, 이를 극복하기 위해 SGD 방식이 도입되었다.
-
이는 전체 학습 데이터 중 단 한 건만 임의로 선택하여 경사 하강법을 실시하는 방식을 의미한다.
-
많은 건 수 중에서 한 건만 실시하기 때문에, 빠르게 최적점을 찾을 수 있지만 노이즈가 심하다.
-
무작위로 추출된 샘플 데이터에 대해 경사 하강법을 실시하기 때문에 진폭이 크고 불안정해 보일 수 있다.
-
일반적으로는 사용되지 않으며, SGD을 얘기할 때는 보통 미니 배치 경사 하강법을 의미한다.

- 전체 학습 데이터 중, 특정 크기(Batch 크기)만큼 임의로 선택해서 경사 하강법을 실시한다.
- 이것 또한 확률적 경사 하강법이다.

- 전체 학습 데이터가 1,000건, bacth size를 100건이라고 가정하면,
전체 데이터를 batch size만큼 나눠서 가져온 뒤 섞고, 경사 하강법을 계산한다. - 이 경우, 10번 반복해야 1,000개의 데이터가 모두 학습되고, 이를 epoch라고 한다.
- 즉, 10 epoch * 100 batch이다.

- 보다 복잡한 문제를 해결하기 위해 입력층과 출력층 사이에 은닉층(Hidden Layer)이 포함되어 있다.
- 퍼셉트론을 여러 층 쌓은 인공신경망으로서, 각 층은 활성 함수를 통해 입력을 처리한다.
- 층이 깊어질수록 보다 정확한 분류가 가능해지지만, 너무 깊어지면 Overfitting이 발생한다.


- 인공 신경망에서 입력값에 가중치를 곱한 뒤 전부 합한 결과를 적용하는 함수다.
- 시그모이드 함수
- 은닉층이 아닌 최종 활성화 함수, 출력층에서 사용한다.
- 은닉층에서 사용 시, 입력값이 양 또는 음의 방향으로 큰 값일 경우 출력에 변화가 없다.
- 평균이 0이 아니기 때문에 정규 분포 형태가 아니며,
방향에 따라 기울기가 달라져서 탐색 경로가 비효율적인(지그재그) 형태가 된다.

- 소프트맥스 함수
- 마찬가지로 은닉층이 아닌 최종 활성화 함수(출력층)에서 사용한다.
- 시그모이드와 유사하게 0 ~ 1 사이의 값을 출력하지만,
이진 분류가 아닌 다중 분류를 통해 모든 확률 값이 1이 되도록 해준다. - 여러 개의 타겟 데이터를 분류하는 다중 분류의 최종 활성화 함수(출력층)로 사용된다.

- 탄젠트 함수
- 은닉층이 아닌 최종 활성화 함수(출력층)에서 사용한다.
- 은닉층에서 사용 시, 시그모이드와 달리 -1 ~ 1 사이의 값을 출력해서 평균이 0이 될 수 있지만,
여전히 입력 값이 양 또는 음의 방향으로 큰 값일 경우 출력 값의 변화가 미비하다.

- 렐루 함수
- 대표적인 은닉층의 활성 함수다.
- 입력 값이 0보다 작으면 0을, 0보다 크면 입력 값을 그대로 출력하게 된다.

- 최적의 경사 하강법을 적용하기 위해 필요하며, 최소값을 찾아가는 방법들을 의미한다.
- loss를 줄이는 방향으로 최소 loss를 보다 빠르고 안정적으로 수렴할 수 있어야 한다.

- 가중치를 업데이트할 때마다 이전 값을 일정 수준 반영시키면서 새로운 가중치로 업데이트한다.
- 지역 최소값에서 벗어나지 못하는 문제를 해결할 수 있으며,
진행했던 방향만큼 추가적으로 더해서 관성처럼 빠져나올 수 있게 해준다.

- 가중치 별로 서로 다른 학습률을 동적으로 적용한다.
- 변화가 적은 가중치에는 보다 큰 학습률을 적용하고, 변화가큰 가중치에는 보다 작은 학습률을 적용한다.
- 처음에는 큰 보폭으로 이동하다가, 최소값에 가까워질수록 작은 보폭으로 이동한다.
- 과거의 모든 기울기를 사용하기 때문에 학습률이 급격히 감소하며, 분모가 커짐으로써 학습률이 0에 가까워진다.


- AdaGrad의 단점을 보완한 기법으로서, 학습률이 지나치게 작아지는 것을 막기 위해
지수 가중 평균법(Exponential Weighted Averages)을 통해 구한다. - 지수 가중 평균법이란, 데이터의 이동 평균을 구할 때
오래된 데이터가 미치는 영향을 지수적으로 감쇠하도록 하는 방법이다. - 이전의 기울기들을 똑같이 더해가는 것이 아니라,
훨씬 이전의 기울기는 약간만 반영하고, 최근의 기울기는 보다 많이 반영한다. - feature마다 적절한 학습률을 적용하여 학습을 효율적으로 진행할 수 있고, AdaGrad보다 학습을 오래 할 수 있다.
- Momentum과 RMSProp, 두 가지 방식을 결합한 형태로,
진행하던 속도에 관성을 주고 지수 가중 평균법을 적용한 알고리즘이다. - 가장 많이 사용되는 최적화 알고리즘으로, 수식은 아래와 같다.


- 구글이 개발한 오픈소스 소프트웨어 라이브러리이며,
머신러닝과 딥러닝을 쉽게 사용할 수 있도록 다양한 기능을 제공한다. - 주로 이미지 인식이나 반복 신경망 구성, 기계 번역, 필기 숫자 판별 등을 위한 각종 신경망 학습에 사용된다.
- 딥러닝 모델을 만들 때, 기초부터 세세하게 작업해야 하기 때문에 진입장벽이 높다.

- 일반 사용 사례에 "최적화, 간단, 일관, 단순화" 된 인터페이스를 제공한다.
- 손쉽게 딥러닝 모델을 개발하고 활용할 수 있도록 직관적인 API를 제공한다.
- Tensorflow 2버전 이상부터 Keras가 포함되어 있기 때문에, Tensorflow를 통해 사용한다.
- 이제는 기존 Keras 패키지보다 Tensorflow에 내장된 Keras를 사용하는 것이 권장된다.

- 흑백 이미지와 컬러 이미지는 각각 2차원과 3차원으로 표현될 수 있다.
- 흑백 이미지는 0 ~ 255 사이의 값을 가지는 2차원 배열 (높이 * 너비)이고,
컬러 이미지는 R, G, B 라는 2차원 배열 3개를 가지는 3차원 배열 (높이 * 너비 * 채널)이다.


- 검은색에 가까운 색은 0에, 흰색에 가까운 색은 255에 가깝다.
- 모든 픽셀이 feature다.

- 간단한 모델을 구햔하기에 적합하며, 단순하게 층을 쌓는 방식으로 쉽고 간단하게 사용할 수 있다.
- 단일 입력 및 출력만 있기 때문에, 레이어를 공유하거나 여러 입력 또는 출력을 가질 수 있는 모델은 생성할 수 없다.
- Sequential API로는 구현하기 어려운 복잡한 모델들을 구현할 수 있다.
- 여러 개의 입력 또는 출력을 가지는 모델을 구현하거나 층 간의 연결 및 연산을 수행하는 모델 구현 시 사용한다.

- 모델이 학습 중에 충돌이 발생하거나 네트워크가 끊기면 모든 훈련 시간이 낭비될 수 있고,
과적합을 방지하기 위해 훈련을 조기 종료해야 할 수도 있다. - 모델이 학습을 시작하면 학습이 완료될 때까지 어떤 제어도 하지 못하게 되고,
신경망 훈련을 완료하는 데에는 몇 시간에서 최대 며칠이 걸릴 수도 있기 때문에, 모델을 모니터링 및 제어하는 기능이 필요하다. - 훈련 시(fit()) Callback API를 등록시키면 반복 내에서 특정 이벤트가 발생할 때마다 등록된 callback이 호출되어 수행된다.
ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weight_only=False, mode='auto')
- 특정 조건에 따라 모델 또는 가중치를 파일로 저장한다.
- filepath: "weights.{epoch:03d}-{val_loss:.4f}-{acc:.4f}.weights.hdf5"와 같이 모델의 체크포인트를 저장한다.
- monitor: 모니터링할 성능 지표를 작성한다.
- save_best_only: 가장 좋은 성능을 보인 모델을 저장할지에 대한 여부
- mode: {auto, min, max} 중 한 가지를 작성한다. monitor의 성능 지표에 따라 적합한 것을 선택한다.
monitor의 성능 지표가 감소해야 좋은 경우는 min, 증가해야 좋은 경우는 max,
monitor의 성능 지표명으로부터 자동으로 유추하고 싶다면 auto를 기재한다.
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', min_lr=0)
- 특정 반복 동안 성능이 개선되지 않을 때, 학습률을 동적으로 감소시킨다.
- monitor: 모니터링할 성능 지표를 작성한다.
- factor: 학습률을 감소시킬 비율, 새로운 학습률 = 기존 학습률 * factor
- patience: 학습률을 줄이기 전 monitor 할 반복 횟수
- mode: {auto, min, max} 중 한 가지를 작성한다. monitor의 성능 지표에 따라 적합한 것을 선택한다.
monitor의 성능 지표가 감소해야 좋은 경우는 min, 증가해야 좋은 경우는 max,
monitor의 성능 지표명으로부터 자동으로 유추하고 싶다면 auto를 기재한다.
EarlyStopping(monitor='val_loss', patience=0, verbose=0, mode='auto')
-
특정 반복동안 성능이 개선되지 않으면 학습을 조기 종료한다.
-
monitor: 모니터링할 성능 지표를 작성한다.
-
patience: Early Stopping을 적용하기 전 monitor할 반복 횟수
-
mode: {auto, min, max} 중 한 가지를 작성한다. monitor의 성능 지표에 따라 적합한 것을 선택한다.
monitor의 성능 지표가 감소해야 좋은 경우는 min, 증가해야 좋은 경우는 max,
monitor의 성능 지표명으로부터 자동으로 유추하고 싶다면 auto를 기재한다.
-
실제 이미지 데이터는 분류 대상이 이미지에서 고정된 위치에 있지 않은 경우가 대부분이다.
-
실제 이미지 데이터를 분류하기 위해서는 이미지의 각 feature들을 그대로 학습하는 것이 아닌,
CNN으로 패턴을 인식한 뒤 학습해야 한다.


- 이미지의 크기가 커질수록 굉장히 많은 Weight(가중치)가 필요하기 때문에 분류기에 바로 넣지 않고,
이를 사전에 추출 및 축소해야 한다. - CNN은 인간의 시신경 구조를 모방한 기술로서, 이미지의 패턴을 찾을 때 사용한다.
- Feature Extraction을 통해 각 단계를 거치면서, 함축된 이미지 조각으로 분리되고
각 이미지 조각을 통해 이미지의 패턴을 인식한다.

- CNN은 분류하기에 적합한 최적의 feature를 추출하고,
그 feature를 추출하기 위한 최적의 Weight와 Filter를 계산한다.

- 보통 정방 행렬로 구성되어 있으며, 원본 이미지에 슬라이딩 윈도우 알고리즘을 사용하여
순차적으로 새로운 픽셀값을 만들면서 적용한다. - 사용자가 목적에 맞는 특정 필터를 만들거나 기존에 설계된 다양한 필터를 선택하여 이미지에 적용한다.
하지만, CNN은 최적의 필터값을 학습하여 스스로 최적화한다.


- 필터 하나 당, 이미지의 채널 수만큼의 Kernel이 존재하고,
각 채널에 할당된 필터의 커널을 적용하여 출력 이미지를 생성한다. - 출력 feature map의 개수는 필터의 개수와 같다.

- 필터 안에는 1 ~ n개의 커널이 존재한다.
- 커널의 개수는 반드시 이미지의 채널 수와 동일해야 한다.
- Kernel Size는 가로 * 세로를 의미하며, 가로와 세로는 서로 다를 수 있지만 보통은 일치시킨다.
- Kernel Size가 크면 클수록 입력 이미지에서 더 많은 feature 정보를 가져올 수 있지만,
큰 사이즈의 커널로 Convolution Backbone을 할 경우, 그만큼 더 많은 연산량과 파라미터가 필요하다.

- 입력 이미지에 Convolution Filter를 적용할 때 Sliding Window가 이동하는 간격을 의미한다.
- 기본 Stride는 1이지만, 2를 적용하면 입력 feature map 대비 출력 feature map의 크기가 절반 정도 줄어든다.
- Stride를 키우면, feature 정보를 손실할 가능성이 높아지지만,
오히려 불필요한 특성을 제거하는 효과를 가져올 수 있고 Convolution 연산 속도를 향상시킨다.


- 필터를 적용하여 Convolution 수행 시, 출력 feature map이 입력 feature map에 비해 계속해서 작아지는 것을 막기 위해 사용한다.
- 필터 적용 전 입력 feature map의 상하좌우 끝에 각각 열과 행을 추가한 뒤,
0으로 채워서 크기를 증가시킨다. - 출력 이미지의 크기를 입력 이미지의 크기와 동일하게 유지하기 위해 직접 계산할 필요 없이,
"same"이라는 값을 통해 입력 이미지의 크기와 동일하게 맞출 수 있다.

- Convolution이 적용된 feature map의 일정 영역별로 하나의 값을 추출하여 feature map의 사이즈를 줄인다.
- 보통은 Convolution → Relu Activation → Pooling 순으로 적용한다.
- 비슷한 feature들이 서로 다른 이미지에서 위치가 달라지면서 다르게 해석되는 현상을 중화시킬 수 있고,
feature map의 크기가 줄어들기 때문에 연산 성능이 향상된다. - Max Pooling과 Average Pooling이 있으며, Max Pooling은 중요도가 가장 높은 feature를 추출하고,
Average Pooling은 전체를 버무려서 추출한다.

- Stride를 증가시키는 것과 Pooling을 적용하는 것은 출력 feature map의 크기를 줄이는 데 사용하는 방법이다.
- Convolution 연산을 진행하면서 feature map의 크기를 줄이면,
위치 변화에 따른 feature의 영향도도 줄어들기 때문에 과적합을 방지할 수 있다는 장점이 있다. - Pooling의 경우, 특정 위치의 feature 값이 손실되는 이슈 등으로 인해
최근 Advanced CNN에서는 많이 사용되지 않는다. - Classifier에서는 Fully Connected Layer의 지나친 연결로 인해 많은 파라미터가 생성되므로 오히려 과적합이 발생할 수 있다.

- Dropout을 사용함으로써 Layer 간 연결을 줄일 수 있고, 과적합도 방지할 수 있다.

- CNN 모델을 제작할 때, 다양한 기법을 통해 성능 개선 및 과적합 해소가 가능하다.
- 처음 가중치를 어떻게 줄 것인지 정하는 방법이며, 처음 가중치를 어떻게 설정하느냐에 따라 모델의 성능이 크게 달라진다.
- 사비에르 글로로트 초기화
- 고정된 표준편차를 사용하지 않고, 이전 층의 노드 수에 맞게 현재 층의 가중치를 초기화한다.
- 층마다 노드 개수를 다르게 설정하더라도, 이에 맞게 가중치가 초기화되기 때문에
고정된 표준편차를 사용하는 것보다 이상치에 민감하지 않다.- 활성화 함수가 ReLU일 경우, 층을 통과할수록 활성화 값이 고르지 못하게 되는 문제가 있기 때문에 출력층에서만 사용한다.


- 카이밍 히 초기화
- 고정된 표준편차를 사용하지 않고, 이전 층의 노드 수에 맞게 현재 층의 가중치를 초기화한다.
- 층마다 노드 개수를 다르게 설정하더라도, 이에 맞게 가중치가 초기화되기 때문에
고정된 표준편차를 사용하는 것보다 이상치에 민감하지 않다.- 활성화 함수가 ReLU일 때 추천하는 초기화 방식으로서, 층이 깊어지더라도 모든 활성화 값이 고르게 분포된다.
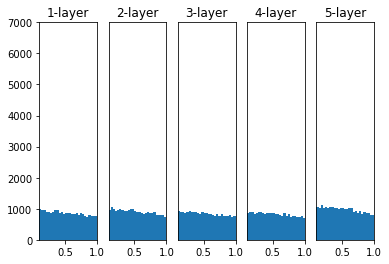

- 입력 데이터 간 값의 차이가 발생하면, 그에 따라 가중치의 비중도 달라지기 때문에 층을 통과할수록 편차가 심해진다.
이를 내부 공변량 이동(Internal Convariant Shift)이라고 한다. - 가중치의 값의 비중이 달라지면, 특정 가중치에 중점을 두면서 경사 하강법이 진행되기 때문에
모든 입력값을 표준 정규화하여 최적의 파라미터를 보다 빠르게 학습할 수 있도록 해야한다. - 가중치를 표준화할 때 민감도를 감소시키고, 학습 속도를 증가시키며, 모델을 일반화하기 위해 사용한다.


- BN을 활성화 함수 앞에 적용하면, Weight(가중치) 값은 평균이 0, 분산이 1인 상태로 정규분포가 된다.
- ReLU가 activation 파라미터로 적용되면, 음수에 해당하는 부분(절반 정도)이 0이 된다.
- 이러한 문제를 해결하기 위해 γ(감마)와 β(베타)를 활용해서 음수 부분이 모두 0이 되는 것을 막아준다.


- Batch Size를 작게 설정하면 적절한 noise가 생겨서 overfitting을 방지하게 된다.
이는 모델의 성능을 향상시키는 계기가 될 수 있지만, 그렇다고 해도 너무 작아지면 안된다. - Batch Size를 너무 작게 설정했을 경우, Batch 하나 당 샘플 수가 줄어들기 때문에
그만큼 훈련 데이터를 학습하는 데에는 부족해질 수 있다. - 따라서 매우 크게 주는 것보다는 매우 작게 주는 것이 낫지만, 너무 작게 주면 안 된다.
- 논문에 따르면, Batch Size는 8 ~ 32 사이로 주는 것이 효과적이라고 한다.


- 이전의 Pooling은 면적을 줄이기 위해 사용했지만,
Global Average Pooling은 면적을 없애고 채널 수 만큼의 값이 나오게 한다. - feature map의 가로 * 세로의 특정 영역을 Sub Sampling하지 않고 채널 별 평균 값을 추출한다.
- 보통 feature map의 채널 수가 많을 때(512개 이상) 적용하는 방식이며, 채널 수가 적을 때는 Flatten을 적용한다.
- Flatten 이후 Classification Dense Layer로 이어지면서
많은 파라미터들로 인한 overfitting 유발 가능성 및 학습 시간 증가로 이어지기 때문에,
맨 마지막 feature map의 채널 수가 크다면 Global Average Pooling을 적용하는 것이 더 나을 수도 있다.

- Loss Function은 loss 값이 작아지는 방향으로 가중치를 업데이트한다.
- 하지만, loss를 줄이는 데에만 신경쓰게 되면 특정 가중치가 지나치게 커지면서 결과는 오히려 악화될 수 있다.
- 기존 가중치에 특정 연산을 수행하여 loss function의 출력 값과 더해주면
loss function의 결과를 어느 정도 제어할 수 있게 된다. - 보통 파라미터 수가 많은 Dense Layer(분류기)에서 많이 사용되며,
가중치보다는 loss function에 규제를 걸어 가중치를 감소시키는 게 원리다. - kernel_reguarlizer 파라미터에서 l1, l2 중 하나를 선택하여 사용한다.

- 이미지의 종류와 개수가 적으면, CNN 모델의 성능이 떨어질 수 밖에 없다.
- 또한, 몇 안되는 이미지로 훈련시키면 과적합이 발생한다.
- CNN 모델의 성능을 높이고 과적합을 개선하기 위해서는 이미지의 종류와 개수가 많아야 한다.
즉, 데이터의 양을 늘려줘야 한다. - 이미지 데이터는 학습 데이터를 수집하여 양을 늘리기 쉽지 않기 때문에,
원본 이미지를 변형시킴으로서 양을 늘릴 수 있다. - Data Augmentation을 통해 원본 이미지에 다양한 변형을 주면,
학습에 사용하는 이미지 데이터를 늘리는 것과 유사한 효과를 볼 수 있다. - 원본 학습 이미지의 개수를 늘리는 것이 아닌, 매 학습마다 개별적으로 원본 이미지를 변형해서 학습을 수행한다.

- 좌우 또는 상하 반전, 특정 영역만큼 확대, 축소, 회전 등으로 변형시킨다.

- 밝기, 명암, 채도, 색상 등을 변형시킨다.
![]()
- 모델을 처음부터 학습시키려면 많은 시간을 소비해야 한다.
- 이를 위해 대규모 학습 데이터를 기반으로 사전에 훈련된 모델을 활용한다.
- 대규모 데이터 세트에서 훈련되고 저장된 데이터로서, 일반적으로 대규모 이미지 분류 작업에서 훈련된 것을 의미한다.
- 입력 이미지는 대부분 244 * 244 크기지만, 모델 별로 차이가 있다.
- 자동차나 고양이 등을 포함한 1000개의 클래스,
총 약 1400만개의 이미지로 구성된 ImageNet 데이터 세트로 사전 훈련되었다.

- 2017년까지 대회가 주최되었으며, 이후에도 좋은 모델들이 등장했고 앞으로도 계속 등장할 것이다.
- 메이저 플레이어들(구글, 마이크로소프트)이 만들어놓은 모델도 등장했다.

- 옥스포드 대학 연구팀이 만든 모델이다.
- 2014년 ILSVRC에서 만든 GoogleNet이 1위. VGG는 2위를 차지했다.
- GoogleNet의 오류율은 6.7%, VGG의 오류율은 7.3%로, 0.6%의 차이밖에 나지 않았다.
- 간결하고 단순한 아키텍처임에도 불구하고, 1위인 GoogleNet과 큰 차이 없는 성능을 보여줘서 주목을 받게 되었다.
- 네트워크 깊이에 따른 모델 성능의 영향에 대한 연구에 집중하여 만들어진 네트워크다.
- 신경망을 깊게 만들수록 성능이 좋아지는 것을 확인했지만, 커널 사이즈가 클수록 이미지 사이즈가 급격하게 줄어들기 때문에
층을 더 깊게 만들기 어렵고 파라미터 개수와 연산량도 더 많이 필요하다는 것을 알게 되었다. - 따라서 커널 크기를 3 * 3으로 단일화했으며, padding과 strides 값을 조정하여 단순한 네트워크를 구성하였다.
- 2개의 3 * 3 커널은 5 * 5 커널 1개와 동일한 크기의 feature map을 생성하기 때문에
3 * 3 커널로 연산하면 더 많은 층을 쌓을 수 있게 된다.

- 여러 사이즈의 커널들을 한꺼번에 결합하는 방식을 사용하며, 이를 묶어서 Inception Module이라고 한다.
- 여러 개의 Inception Module을 연속적으로 이어서 구상하고,
여러 사이즈의 필터들이 서로 다른 공간을 기반으로 feature들을 추출한다. - Inception Module을 결합하면서, 보다 풍부한 Feature Extractor Layer를 구성하게 된다.
- 하지만, 여러 사이즈의 커널을 결합하게 되면, Convolution 연산을 수행할 때
파라미터 수가 증가하게 되고, 이는 과적합으로 이어진다. - 이를 극복하고자 연산을 수행하기 전에 1 * 1 Convolution을 적용해서 파라미터 수를 획기적으로 감소시킨다.
- 1 * 1 Convolution을 적용하면, 입력 데이터의 특징을 함축적으로 표현하면서
파라미터 수를 줄이는 차원 축소 역할을 수행하게 된다.


- 행과 열의 크기 변환 없이 채널 수를 조절할 수 있고, weight 및 비선형성을 추가하는 역할을 한다.
- 행과 열의 사이즈를 줄이고 싶다면 Pooling을 사용하면 되고,
채널 수만 줄이고 싶다면 1 * 1 Convolution을 사용하면 된다.
![]()
- VGG 이후 더 깊은 네트워크에 대한 연구가 많아졌지만,
네트워크의 깊이가 깊어질수록 오히려 정확도가 떨어지는 문제가 있었다. - 이는 층이 깊어질수록 기울기가 계속해서 0에 가까워지는 Gradient Vanishing이 발생하기 때문이다.

- 이 문제를 해결하고자 층을 만들되, Input 데이터와 Output이 동일하게 나올 수 있도록 하는 층을 연구하기 시작했다.
이를 함수로 나타내면 H(x) = x이다. - 하지만 활성화 함수를 통과한 값을 기존 Input과 동일하게 만드는 것은 굉장히 복잡했기 때문에
H(x) = F(x) + x일 때, F(x)를 0으로 만드는 것에 포커스하게 되었다. - Input은 x이고, Model인 F(x)라는 일련의 과정을 거치면서, 자신인 x가 더해져서
Output으로 F(x) + x가 나오는 구조가 된다.


- 이미지 분류 문제를 해결하는 데 사용했던 모델을
다른 데이터 세트 또는 다른 문제에 적용시켜 해결하는 것을 의미한다. - 즉, 사전 학습 모델을 다른 작업에 이용하는 것을 의미한다.
- 사전 훈련 모델의 Convolutional Base 구조(Conv2D + Pooling)을 그대로 두고,
분류기(Fully Connected Layer)를 붙여서 학습시킨다.

- 사전 학습 모델의 용도를 변경하기 위한 층별 미세 조정(Fine Tuning)은
데이터 세트의 크기와 유사성을 기반으로 고민하여 조정한다. - 2018년 FAIR(Facebook AI Research) 논문에서 실험을 통해 '전이 학습이 학습 속도 면에서 효과가 있다'라는 것을 밝혀냈다.
![]()
- 0 ~ 1, -1 ~ 1, z-score 변환 중 하나를 선택하여 범위를 축소하는 작업을 의미한다.
- 사전 훈련 모델은 주로 TensorFlow와 PyTorch 프레임워크 방식을 사용한다.
- TensorFlow는 -1 ~ 1, PyTorch는 z-score 방식으로 변환하는 것이 각 프레임워크의 전통이다.

- ImageNet으로 학습된 사전 훈련 모델을 다른 목적이나 용도로 활용할 때
Feature Extractor(CNN)의 Weight(가중치)를 제어하기 위한 기법이다. - 특정 Layer들을 Freeze시켜 학습에서 제외시키고, Learning Rate를 점차 감소시켜 적용한다.
- ImageNet과 유사한 데이터 세트거나, 클래스 별 데이터 건 수가 적을 경우 사용하는 것을 권장한다.
- 학습시간 단축이 주 목적으로, 위 상황이 아닌 경우에는 Sequence까지만 진행하는 것이 좋다.
- Fine Tuning이 언제나 모델의 성능을 향상시키는 것은 아니기 때문에, 적절한 상황에 사용할 수 있어야 한다.
- 먼저 Classification Layer(분류기)만 학습시킨 뒤 전체를 학습시키는 순서로 진행하며,
이를 위해 fit을 최소 2번 이상 실행한다. - 층별로 Freeze 또는 Unfreeze 여부를 결정하기 위해 미세 조정을 진행할 때,
학습률이 높으면 이전에 학습한 것을 잃을 위험이 있기 때문에 학습률은 작게 설정한다.