마이 핀테크 서비스 개발 경진 대회 (2022.06.24 ~ 26 )
금융 생활이 익숙하지 않은 사람들의 금융 의사결정을 도와주는 나의 금융 페이스 메이커, Financial Pace Maker, FPM
- fpm-docker에서 compose up
- mongodb .env 파일필요
- local hosts 파일 fpm.local / api.fpm.local 로 2가지 DNS 세팅하면 훨씬 편함
- (1)의 명령어는 fpm-docker -> docker-run.sh 참고
- mongodb admin user 세팅 - env 파일과 통일 시키기
- BE에서 .env파일 필요, fpm-fe와 fpm-be의 yarn install 후 각 package.json 파일에서 script 참조
- ps. fe는 html 퍼블리싱이 우선 (fpm-fe-html)
- 그리고 갤럭시 S8+ 로 뷰사이즈 픽스세팅
- docker -> nginx -> conf.d 하위 conf 파일들 참조
- be에서는 dump 파일 메킹이 모두 세팅되어 있음, 데이터 세팅 순서
- user dump
- deposit dump
- stock / loan
- user hashtag
- financialDetail
- 위 순서로 모두 dump POTS request로 세팅
- BE API는 insomnia json file 참조 - 확인하기
- jwt 토큰 기반 auth라 쿠키 세팅 체크 (헤더 -> body -> 쿠키 순서로 체크)
- insomnia에서 import, docs도 참조
- 사용자 군집화 및 분류
- 개인 데이터를 kmeans clustring, 군집화하고, 사용자 특성을 #(해시태그)로 표현
- 원하는 해시태그만 활성화 하면, 나의 군집 내의 그 해시태그에 해당되는 사람들의 결과만 선택적으로 볼 수 있다. 그리고 나의 위치와 상위 n% 평균, 또는 전혀 다른 군집의 사람들을 볼 수 있다.
- 분류 된 소비 패턴 분석으로 사용자 특성 파악
- 다양한 데이터를 혼합하여 키워드를 추출하여, 사용자의 자산 프로세스에서 부족한 부분을 효과적으로 전달할 수 있다.
- KoBERT 등의 문맥 파악 모델을 활용한다면 문맥 파악을 바탕으로 더욱 고도화된 사용자 특성을 파악할 수 있다.
- 사용자 소비, 투자 리포트 공유
- 해당 페이스 메이커 플랫폼을 활용하는 “유저들 간, 개인정보 누출 없이” 투자 리포트, 소비 패턴 등 금융과 관련된 데이터를 서로 볼 수 있다.
- 목표 수익률을 설정하고, 해당 수익률을 달성 중인 사용자의 투자, 소비 라이프 스타일 등을 확인할 수 있다.
- 나의 목표를 이룰 수 있게 지속적인 참여 유도 기능
- 금융 멘토가 이끄는 챌린지에 참여함으로써 지속적인 도전을 유도하고, 금융 목표 달성에 도움을 줄 수 있다.
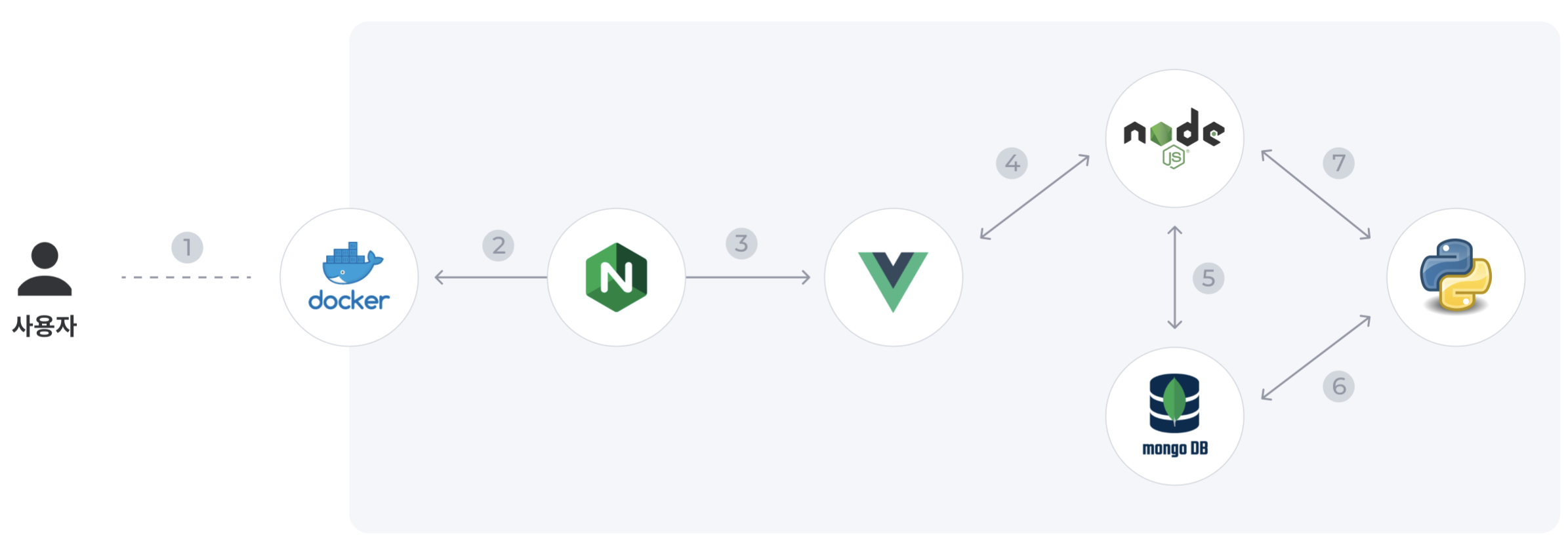
- Infra (& build, devOps) : Docker
- web-server : Nignx
- FE : Vue.js
- BE(api) : Express.js (node)
- DB : Mongodb(nosql)
- Python : 하단 부분에서 다시 설명
-
우선 유저의 deposit data 기반으로 user를 1차 분류화 -> 특정 키워드 기반으로 hashtag 만들어서 분류
- deposit 정보 기반이라 해당 부분에 NLP 중 문맥 파악(BERT, KoBERT 등의)의 적용 고려 가능함 (추후)
-
그에 그치지않고 전체 유저들을 대상으로 "개인과 개인이 모여, 우리가 되어 서로가 서로에게 도움이 되는" 군집 형성을 하기 위해 k-means clustring 활용
- k-means후 군집에 대한 결정권이 있다면 Knn의 확장 가능성 고려 가능
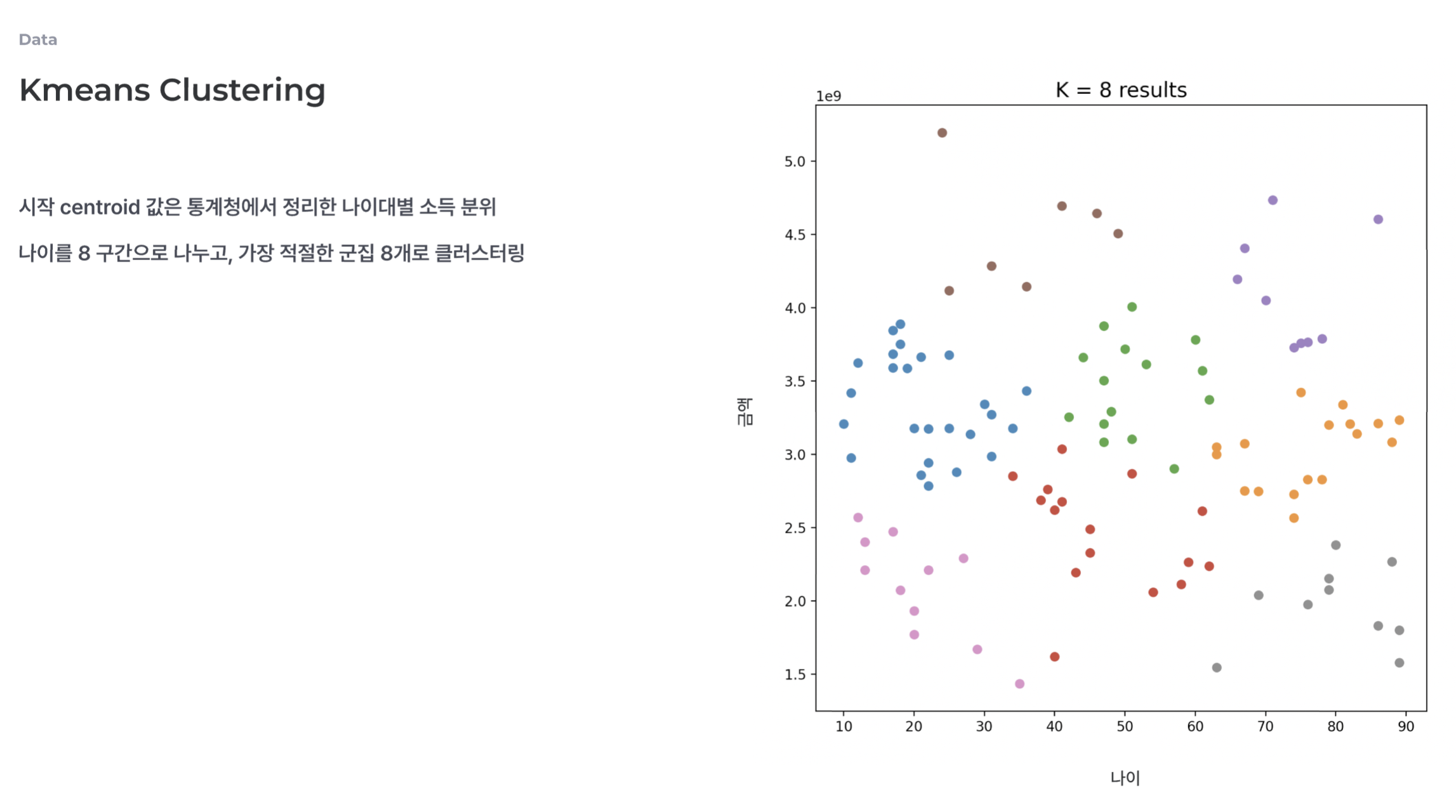
- AI - 비지도 학습 Kmeans 를 활용한다.
- 시작 centroid 값은 통계청에서 정리한 나이대별 소득 분위로 잡은 뒤 군집화 시킨다.
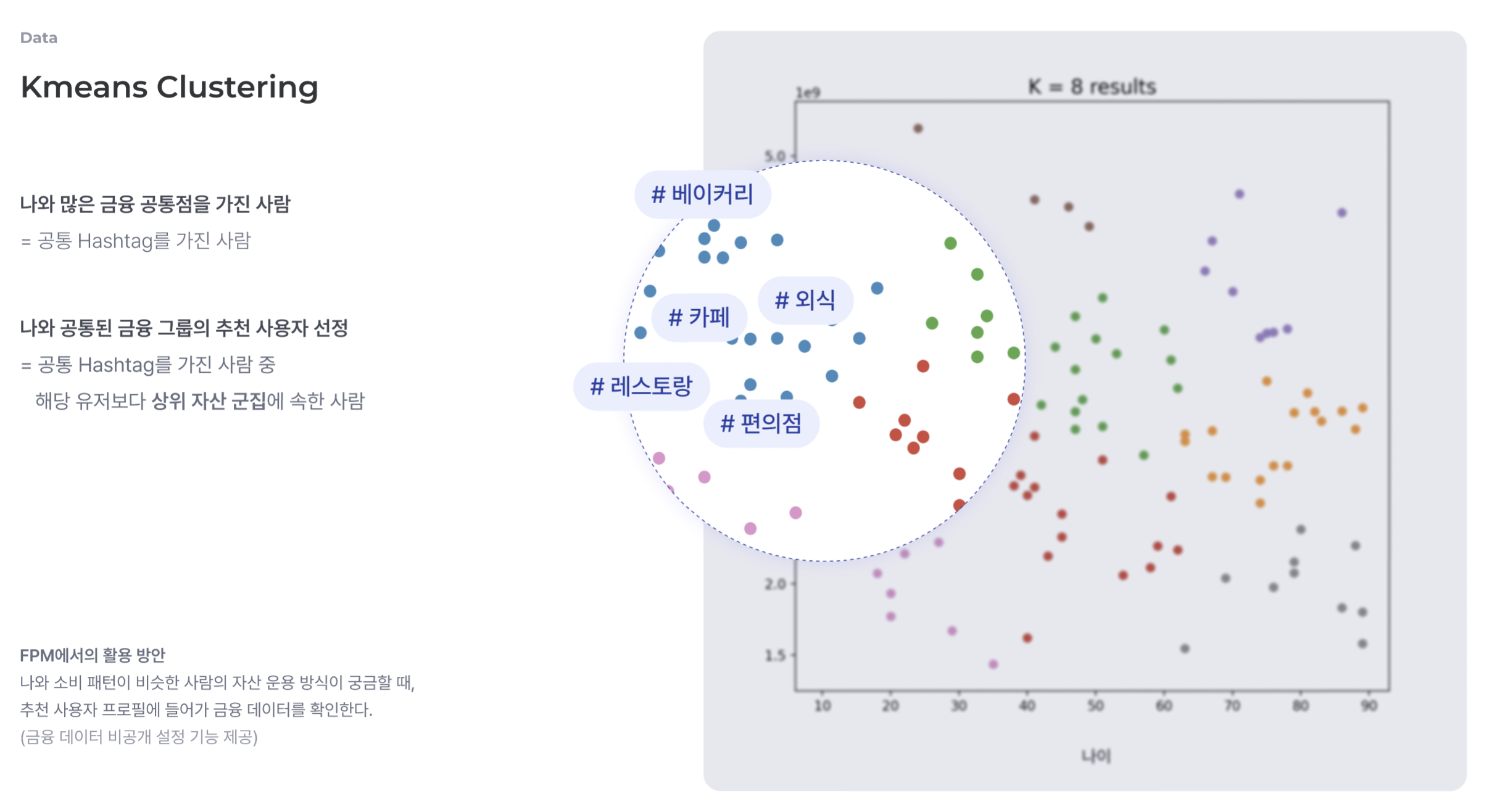
- 그 군집 내부에서 공통점을 가지는 사람은 같은 “hashtag”를 가지고 있는 사람. 이렇게 진짜 “비슷한 공통점” 으로 이뤄진 군집이 이워진다.