This project involves building a data warehouse with fact and dimension tables by integrating I94 immigration data, world temperature data and US demographic data.
The project follows the follow steps:
- Step 1: Scope the Project and Gather Data
- Step 2: Explore and Assess the Data
- Step 3: Define the Data Model
- Step 4: Run ETL to Model the Data
- Step 5: Complete Project Write Up
This project will integrate I94 immigration data, world temperature data and US demographic data to setup a data warehouse with fact and dimension tables.
-
Data Sets
-
Tools
- AWS S3: data storage
- Python for data processing
- Pandas - exploratory data analysis on small data set
- PySpark - data processing on large data set
| Data Set | Format | Description |
|---|---|---|
| I94 Immigration Data | SAS | This data comes from the US National Tourism and Trade Office and contains international visitor arrival statistics by world regions and select countries and other data points. |
| World Temperature Data | CSV | This dataset comes from Kaggle and contains monthly average temperature data for different countries. |
| U.S. City Demographic Data | CSV | This data comes from OpenSoft and shows demographics of all US cities and census-designated places with a population greater or equal to 65,000. |
- Use pandas for exploratory data analysis to get an overview on these data sets
- Split data sets to dimensional tables and change column names for better understanding
- Utilize PySpark on one of the SAS data sets to test ETL data pipeline logic
- Transform arrdate, depdate from SAS time format to pandad.datetime
- Parse description file to get auxiliary dimension table - country_code, city_code, state_code, mode, visa
- Tranform city, state to upper case to match city _code and state _code table
Please refer to Capstone_Project.ipynb.
(This step was completed in Udacity workspace as pre-steps for building up and testing the ETL data pipeline. File paths should be modified if notebook is run locally.)
Since the purpose of this data lake is for BI app usage, we will model these data sets with star schema data modeling.
-
Star Schema
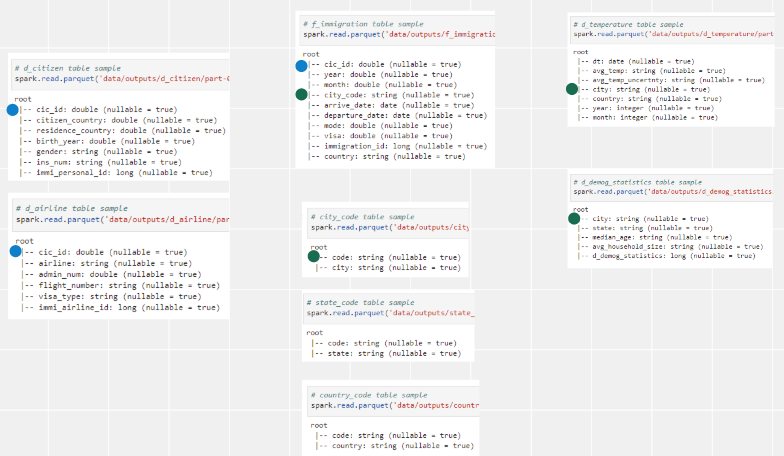

- Assume all data sets are stored in S3 buckets
- Follow by Step 2 – Cleaning step to clean up data sets
- Transform immigration data to 1 fact table and 2 dimension tables, fact table will be partitioned by
state_code - Parsing label description file to get auxiliary tables
- Transform temperature data to dimension table
- Split demography data to 2 dimension tables
- Store these tables back to target S3 bucket
Check etl.py to see code.
Data processing and data model was created by Spark.
Check Capstone_Project.ipynb.
Data quality checks includes
- No empty table after running ETL data pipeline
- Data schema of every dimensional table matches data model
Please refer to Quality-checks.ipynb.
Please refer to Capstone_Project.ipynb.
- AWS S3 for data storage
- Pandas for sample data set exploratory data analysis
- PySpark for large data set data processing to transform staging table to dimensional table
- Tables created from immigration and temperature data set should be updated on a monthly basis since the raw data set is built up monthly.
- Tables created from demography data set could be updated on an annual basis since it's data collection takes time..
- All tables should be updated in an append-only mode.
-
The data was increased by 100x.
If Spark with standalone server mode can not process 100x data set, we could consider to put data in AWS EMR which is a distributed data cluster for processing large data sets on cloud
-
The data populates a dashboard that must be updated on a daily basis by 7am every day.
Apache Airflow can be used to schedule and automate this data pipeline. There are other services similar to apache Airflow such as dagster and Luigi.
-
The database needed to be accessed by 100+ people.
AWS Redshift can handle this efficiently. If our provisioned nodes are not sufficient, we can scale our resources to cater to the increased workload.