![]()
The trubrics-sdk allows ML practitioners to collect human feedback on datasets & ML models, and integrate this feedback into the ML workflow.
- Feedback collection on ML models / data from users with the FeedbackCollector
- Integration of feedback into ML workflows with the ModelValidator
- Tracking and management of user feedback in the Trubrics platform
(venv)$ pip install trubricsThe Trubrics FeedbackCollector helps you to collect user feedback on your models with your favourite python web development library. Exposing ML data and model results to users / domain experts is a great way to find bugs and issues.
Start collecting feedback directly from within your ML apps now with our various integrations:
👇 click here to view our demo app

To start collecting feedback from your Streamlit app, install the additional dependency:
(venv)$ pip install "trubrics[streamlit]"and add this code snippet directly to your streamlit app:
from trubrics.integrations.streamlit import FeedbackCollector
collector = FeedbackCollector()
collector.st_feedback(type="issue") # feedback is saved to a .json fileFor more information on our Streamlit integration, check our docs.
Dash
To get started with Dash, install the additional dependency:
(venv)$ pip install "trubrics[dash]"And add this to your Dash app:
from dash import Dash, html
from trubrics.integrations.dash import collect_feedback
app = Dash(__name__)
app.layout = html.Div([collect_feedback(tags=["Dash"])])
if __name__ == "__main__":
app.run_server(debug=True)Gradio
To get started with Gradio, install the additional dependency:
(venv)$ pip install "trubrics[gradio]"And add this to your Gradio app:
import gradio as gr
from trubrics.integrations.gradio import collect_feedback
with gr.Blocks() as demo:
gr.Markdown("Gradio app to collect user feedback on models.")
with gr.Tab("Feedback"):
collect_feedback(tags=["Gradio"])
demo.launch()To close the loop on feedback issues and ensure they are not repeated, ML practitioners can build validations. There are three main steps to creating model validations with the trubrics-sdk:
- Initialise a
DataContext, that wraps ML datasets and metadata into a trubrics friendly object. - Build validations with the
ModelValidator, using theDataContextand any ML model (scikit-learn or any python model). TheModelValidatorholds a number of out-of-the-box validations and can also be used to build custom validations from a python function. - Group validations into a
Trubric, which is saved as a .json file and rerun against any model / dataset.
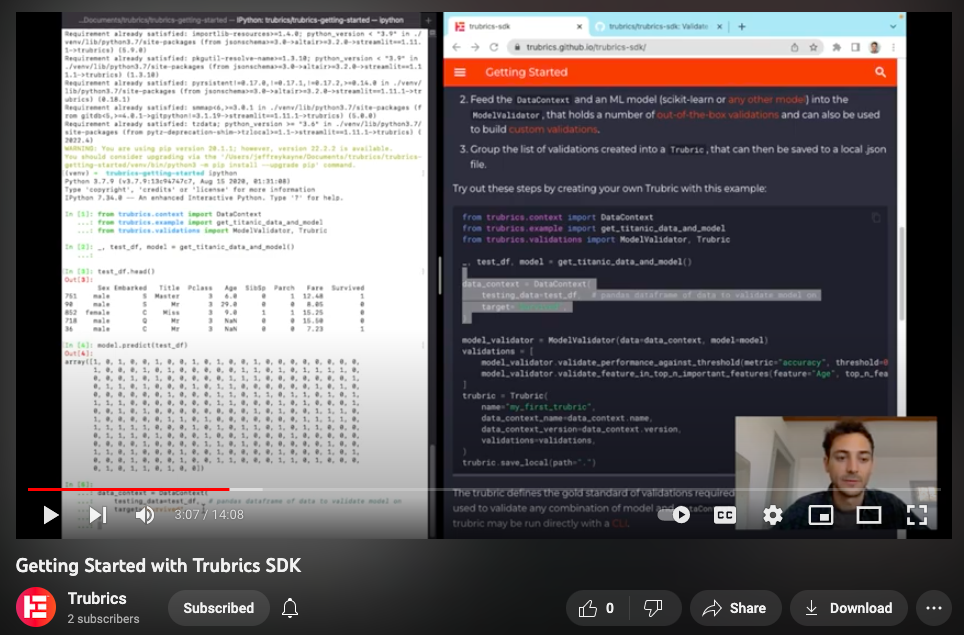
Try out these steps by creating your own Trubric with this example:
from trubrics.context import DataContext
from trubrics.example import get_titanic_data_and_model
from trubrics.validations import ModelValidator, Trubric
_, test_df, model = get_titanic_data_and_model()
# 1. Init DataContext
data_context = DataContext(
testing_data=test_df, # pandas dataframe of data to validate model on
target="Survived",
)
# 2. Build validations with ModelValidator
model_validator = ModelValidator(data=data_context, model=model)
validations = [
model_validator.validate_performance_against_threshold(metric="accuracy", threshold=0.7),
model_validator.validate_feature_in_top_n_important_features(feature="Age", top_n_features=3),
]
# 3. Group validations into a Trubric
trubric = Trubric(
name="my_first_trubric",
data_context_name=data_context.name,
data_context_version=data_context.version,
validations=validations,
)
trubric.save_local(path="./my_first_trubric.json") # save trubric as a local .json file
trubric.save_ui() # or to the Trubrics platformThe Trubric defines the gold standard of validations required for your project, and may be used to validate any combination of model and DataContext. Once saved as a .json, the trubric may be run directly from the CLI.
See a full tutorial on the titanic dataset here.
The Trubrics platform allows teams to collaborate on model issues and track validation changes. Please get in touch with us here to gain access to Trubrics for you and your team.