[🏠Homepage] |[📄arXiv] | [🤗HF Paper] | [📊Datasets] | [🤖Models] | [🛠️Code]
🏆[2024-03-13]: Our 33B model has claimed the top spot on the BigCode leaderboard!
💡[2024-03-06]: We have pushed the model scores of the OpenCodeInterpreter-DS series to EvalPlus!
💡[2024-03-01]: We have open-sourced OpenCodeInterpreter-SC2 series Model (based on StarCoder2 base)!
🛠️[2024-02-29]: Our official online demo is deployed on HuggingFace Spaces! Take a look at Demo Page!
🛠️[2024-02-28]: We have open-sourced the Demo Local Deployment Code with a Setup Guide.
✨[2024-02-26]: We have open-sourced the OpenCodeInterpreter-DS-1.3b Model.
📘[2024-02-26]: We have open-sourced the CodeFeedback-Filtered-Instruction Dataset.
🚀[2024-02-23]: We have open-sourced the datasets used in our project named Code-Feedback.
🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series! We welcome everyone to try out our models and look forward to your participation! 😆
OpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities.
All models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: OpenCodeInterpreter Models.
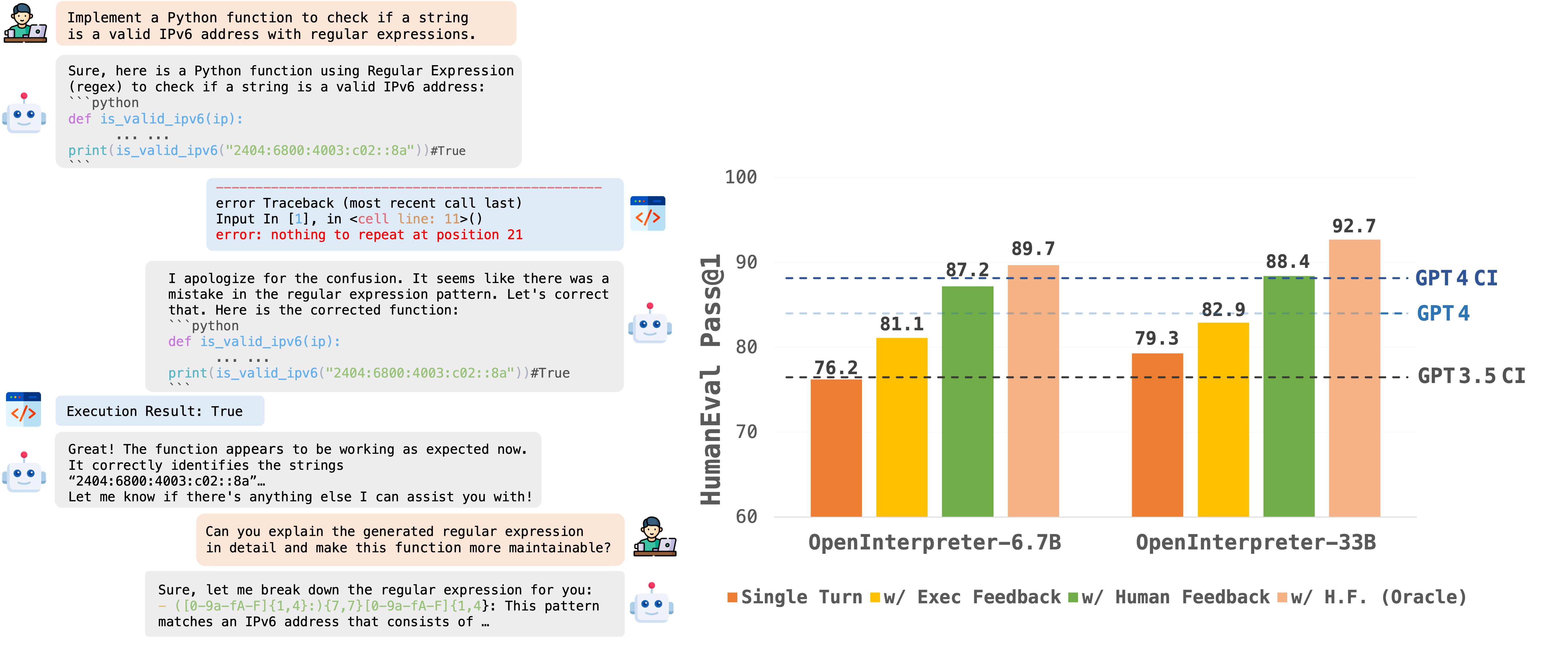
The OpenCodeInterpreter Models series exemplifies the evolution of coding model performance, particularly highlighting the significant enhancements brought about by the integration of execution feedback. In an effort to quantify these improvements, we present a detailed comparison across two critical benchmarks: HumanEval and MBPP. This comparison not only showcases the individual performance metrics on each benchmark but also provides an aggregated view of the overall performance enhancement. The subsequent table succinctly encapsulates the performance data, offering a clear perspective on how execution feedback contributes to elevating the models' capabilities in code interpretation and execution tasks.
| Benchmark | HumanEval (+) | MBPP (+) | Average (+) |
|---|---|---|---|
| OpenCodeInterpreter-DS-1.3B | 65.2 (61.0) | 63.4 (52.4) | 64.3 (56.7) |
| + Execution Feedback | 65.2 (62.2) | 65.2 (55.6) | 65.2 (58.9) |
| OpenCodeInterpreter-DS-6.7B | 76.2 (72.0) | 73.9 (63.7) | 75.1 (67.9) |
| + Execution Feedback | 81.1 (78.7) | 82.7 (72.4) | 81.9 (75.6) |
| + Synth. Human Feedback | 87.2 (86.6) | 86.2 (74.2) | 86.7 (80.4) |
| + Synth. Human Feedback (Oracle) | 89.7 (86.6) | 87.2 (75.2) | 88.5 (80.9) |
| OpenCodeInterpreter-DS-33B | 79.3 (74.3) | 78.7 (66.4) | 79.0 (70.4) |
| + Execution Feedback | 82.9 (80.5) | 83.5 (72.2) | 83.2 (76.4) |
| + Synth. Human Feedback | 88.4 (86.0) | 87.5 (75.9) | 88.0 (81.0) |
| + Synth. Human Feedback (Oracle) | 92.7 (89.7) | 90.5 (79.5) | 91.6 (84.6) |
| OpenCodeInterpreter-CL-7B | 72.6 (67.7) | 66.4 (55.4) | 69.5 (61.6) |
| + Execution Feedback | 75.6 (70.1) | 69.9 (60.7) | 72.8 (65.4) |
| OpenCodeInterpreter-CL-13B | 77.4 (73.8) | 70.7 (59.2) | 74.1 (66.5) |
| + Execution Feedback | 81.1 (76.8) | 78.2 (67.2) | 79.7 (72.0) |
| OpenCodeInterpreter-CL-34B | 78.0 (72.6) | 73.4 (61.4) | 75.7 (67.0) |
| + Execution Feedback | 81.7 (78.7) | 80.2 (67.9) | 81.0 (73.3) |
| OpenCodeInterpreter-CL-70B | 76.2 (70.7) | 73.0 (61.9) | 74.6 (66.3) |
| + Execution Feedback | 79.9 (77.4) | 81.5 (69.9) | 80.7 (73.7) |
| OpenCodeInterpreter-GM-7B | 56.1 (50.0) | 39.8 (34.6) | 48.0 (42.3) |
| + Execution Feedback | 64.0 (54.3) | 48.6 (40.9) | 56.3 (47.6) |
| OpenCodeInterpreter-SC2-3B | 65.2 (57.9) | 62.7 (52.9) | 64.0 (55.4) |
| + Execution Feedback | 67.1 (60.4) | 63.4 (54.9) | 65.3 (57.7) |
| OpenCodeInterpreter-SC2-7B | 73.8 (68.9) | 61.7 (51.1) | 67.8 (60.0) |
| + Execution Feedback | 75.6 (69.5) | 66.9 (55.4) | 71.3 (62.5) |
| OpenCodeInterpreter-SC2-15B | 75.6 (69.5) | 71.2 (61.2) | 73.4 (65.4) |
| + Execution Feedback | 77.4 (72.0) | 74.2 (63.4) | 75.8 (67.7) |
Note: The "(+)" notation represents scores from extended versions of the HumanEval and MBPP benchmarks. To ensure a fair comparison, the results shown for adding execution feedback are based on outcomes after just one iteration of feedback, without unrestricted iterations. This approach highlights the immediate impact of execution feedback on performance improvements across benchmarks.
Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement. For additional insights into data collection procedures, please consult the readme provided under Data Collection.
Our evaluation framework primarily utilizes HumanEval and MBPP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the EvalPlus framework for a more comprehensive assessment. For specific evaluation methodologies, please refer to the Evaluation README for more details.
We're excited to present our open-source demo, enabling users to effortlessly generate and execute code with our LLM locally. Within the demo, users can leverage the power of LLM to generate code and execute it locally, receiving automated execution feedback. LLM dynamically adjusts the code based on this feedback, ensuring a smoother coding experience. Additionally, users can engage in chat-based interactions with the LLM model, providing feedback to further enhance the generated code.
To begin exploring the demo and experiencing the capabilities firsthand, please refer to the instructions outlined in the OpenCodeInterpreter Demo README file. Happy coding!
-
Entering the workspace:
git clone https://github.com/OpenCodeInterpreter/OpenCodeInterpreter.git cd demo -
Create a new conda environment:
conda create -n demo python=3.10 -
Activate the demo environment you create:
conda activate demo -
Install requirements:
pip install -r requirements.txt -
Create a Huggingface access token with write permission here. Our code will only use this token to create and push content to a specific repository called
opencodeinterpreter_user_dataunder your own Huggingface account. We cannot get access to your data if you deploy this demo on your own device. -
Add the access token to environment variables:
export HF_TOKEN="your huggingface access token" -
Run the Gradio App:
python3 chatbot.py --path "the model name of opencodeinterpreter model family. e.g., m-a-p/OpenCodeInterpreter-DS-6.7B"
demo.mp4
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. We're here to assist you!
If you find this repo useful for your research, please kindly cite our paper:
@article{zheng2024opencodeinterpreter,
title={OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement},
author={Zheng, Tianyu and Zhang, Ge and Shen, Tianhao and Liu, Xueling and Lin, Bill Yuchen and Fu, Jie and Chen, Wenhu and Yue, Xiang},
journal={arXiv preprint arXiv:2402.14658},
year={2024}
}
We would like to extend our heartfelt gratitude to EvalPlus for their invaluable support and contributions to our project.