Agradecimentos ao Felipe Megale pelas imagens
- Sumário
- Introdução à modelagem e avaliação de desempenho de sistemas computacionais
- Metodologia para o planejamento de capacidade

A prática tem mostrado que frente a um baixo desempenho de sistemas computacionais (baixos níveis de QoS - Quality of Service) os maiores prejuízos financeiros ocorrem pela falta de uma mentalidade voltada para extrair o máximo benefício do investimento. Na prãtica, os responsáveis pelos setores de T.I. se apressam para propostas em mudanças de hardware sem mesmo ter esgotado todos os esforços para melhorar os níveis de QoS.

A Engenharia de Avaliação de Sistemas computacionais tem por objetivo, frente ao aumento contínuo da carga de trabalho, alimentar a vida útil do sistema, melhorando os níveis de serviço (R - tempo de resposta, U - utilização do sistema) dentro de limites normalmente estipulados pela gerência.
A engenharia de avaliação de desempenho de sistemas computacionais possui uma metodologia para o "planejamento de capacidade" a qual envolve uma série de etapas e ações, corretivas e preventivas que podem ser aplicadas ao longo do ciclo de vida do sistema.
Resumidamente essas ações podem ser sintetizadas nas seguintes:
- Monitor: Com quais dispositivos e durante quanto tempo?
- Coletor: Quais porâmetros observar objetivando a avaliação do sistema?
- Sumarizar e identificar horãrios de pico
- Coletar novos dados: Quais parâmetros coletar objetivando a otimização do sistema?
- Selecionar os processos críticos: Por onde começar a otimimza?
- Otimizar: Propor soluções para aumentar a vida útil e afastar a super-utilização
- Meta-Otimização: Tornar mais eficiente, provavelmente eficaz, o processo de otimização
- Prever a carga de trabalho futuro: Construção de modelos matemáticos
- Modelar o sistema: Construir modelos baseados na teoria das filas
- Simular para prever o início da fase de super-utilização
- Configurar: Propor configurações por meio de simulação
- Negociar: Fortes justificativas
Diferentemente ao ciclo de vida de um software, o ciclo de vida do sistema computacional não apresenta a "fase de morte". Qualquer mudança parcial ou completa da configuração de hardware é considerada evolução natural do sistema.

Nesta fase, existe duas possíveis situações:
- Proposta da configuração inicial: Para esta situação não existem técnicas altamente eficientes para configurar o hardware. As técnicas mais utilizadas são as técnicas Eu acho, Benchmark, Kernel.
- Proposta de atualização deconfiguração existente: Para esta situação existem técnicas mais elaboradas como a teoria das filas, simulação discreta, redes de petri, etc. Dentre estas a teoria das filas é mais aplicada para fins comerciais. Isso pelo tempo necessário para implementá-la.
Aparentemente esta fase parece transmitir uma impressão de simplicidade. Porém é exigido do responsável habilidades e estratégias de negociação e convencimento frente à diretoria e fornecedores. O resultado desta fase possui grandes implicações financeiras para a empresa. Isto torna-se mais sensível em ambientes onde predomina a compra de recursos e de sistemas leasing (aluguel-venda). Neste último, existe maiores responsabilidade do responsável por acompanhar o desempenho do sistema.
Por exemplo, no sistema leasing:

Custo do aluguel: Por média ou por pico?
Espera-se que esta fase seja a mais longa de todas (2, 3 a 4 anos). Durante esta fase, o objetivo é extrair o máximo de proveito do investimento. Em outras palavras aumenta a vida últil do sistema, sem troca de configuração de hardware (aumento de memória é permitido).

Durante a fase de operação são aplicadas as ações até a Meta-otimização do sistema. Ao final desta fase normalmente é realizada a previsão da carga de trabalho.
Esta fase se caracteriza pelo fato da utilização do sistema estar em 100% de forma permanente. Esta fase deve ser previsa com 1 ano de antecedência. Na prática deve ser previsto com no mínimo 3 meses. Muitas vezes nos encontramos já na super-utilização.
| Antes | Depois | |||
|---|---|---|---|---|
| 🅧 | Memória (%) | 100 | 98 | |
| Paginação (%) | 35 | 5 | Horário de pico | |
| 🅧 | CPU (%) | 5 | 5 |
Foram identificados: 80 requisições distintas Modelos do sistema: 80 equações
Para simplificar o modelo:
- Eliminação de processos obsoletos e irrelevantes
- Redução de processos pela similaridade de características
Exempo:
Saldo Conta Corrente ≡ Saldo Poupança
Modelo resultante: 5 equações


- Envia para o servidor com menor carga;
- Tempo de resposta no instante
t; - Utilização dos servidores;
- Disponibilidade.

Lei do fluxo forçado



A metodologia para o planejamento de capacidade possui uma série de etapas com ações tanto corretivas como preventivas. A aplicação desta metodologia procura melhorar o desempenho do sistema, aumento da vida útil do sistema dentro dos padrões de qualidade previamente estipulados.
Durante esta etapa é necessário responder às seguintes questões:
- Quais variáveis monitorar?
- Quando monitorar?
- Com quais tipos de monitores devemos monitorar?
- Durante quanto tempo devemos monitorar?
- De quanto em quanto tempo devemos coletar?
- Como sintetizar?
- Como visualizar?
| Variável | Descrição | Unidade |
|---|---|---|
| λ | Requisições que chegam | requisições por segundo |
| R | Tempo médio de resposta | segundos por requisição |
| Ui | Utilização da CPU (processamento) | porcentagem |
| Du | Disponibilidade do sistema | |
| M | Consumo de memória | porcentagem |
| Pag | Paginação | porcentagem |
É altamente aconselhável realizar o monitoramento durante o horário de pico. Caso esse horário não seja previamente definido podem ser executadas as seguintes ações:
- Coleta de dados durante 1 semana
- Excepcionalmente durante 1 dia
- Em teoria durante 1 ano
É possível também considerar o próprio experiência.
Por exemplo:
- Setor financeiro:
P1: 11:00 - 13:00 P2: 16:00 - 20:00 - Setor eComerce:
- Lojas Americanas:
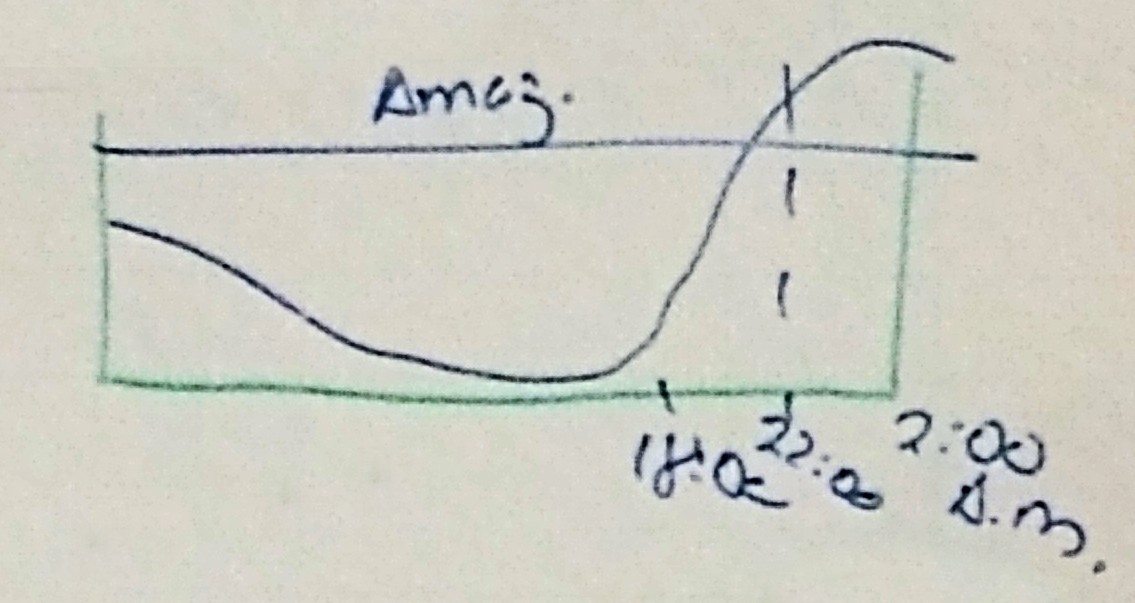
- Lojas Americanas:

Os monitores mais utilizados comercialmente correspondem aos monitores de software, os quais ficam residentes em memória observando todas as interrupções (instruções) do sistema.
Esses monitores consomem memória, CPU, disco e possuem impacto no desempenho do sistema. Existem 2 modalidades:
-
RMF: Monitores orientados a eventos. Altamente precisos, porém com grande impacto no desempenho atual do sistema. devem ser evitados quando o sistema é crítico. Estes podem chegar a impactar até 15%.
-
SMF: Orientado a amostragem. O sistema é observado de tempos em tempos. São mais imprecisos e redundantes. Comercialmente mais utilizados.

Para monitores na modalidade SMF 2 parâmetros devem ser ajustados:
T₀: Tempo de observação
Tₛ: Tempo de amostragem
O ajuste desses parâmetros dependem dos objetivos.
Para o diagnóstico não existe fortes restrições para ajustar o T₀ e Tₛ.
Exemplo:
T₀ = 30 min, 1h
Tₛ = 2, 3 até 5h
// Observação: Procurar respeitar a Hipótese do Equilíbrio de Fluxo
-
Objetivo é o diagnóstico
T₀ = não há restrições Tₛ = 2 a 5 segundos (recomenda-se 3 segundos) // Observação: Procurar respeitar a Hipótese do Equilíbrio de Fluxo -
Objetivo é a modelagem
T₀ = não é possível definir a priori Tₛ = não é possível definir a priori // Condições: Respeitar a Hipótese do Equilíbrio de Fluxo e das transições unitárias
É recomendado a construção de gráficos de valores médios de consumo ao longo das semanas e/ou meses. Referências menores à semana, por dia, não é interessante, pois mostra excessiva variabilidade. O objetivo é observar tendências.


Observações:
- Batch aumenta ➡️ Online diminui
- Batch próximo de 100%
- Online abaixo do batch
- Não existem variações abruptas
- Pouca permanência em condição de alto consumo
- Sistema estável, sem variações significativas
De forma a ser eficientes na melhoria do desempenho do sistema os esforços de otimização devem estar concentrados durante o(s) horário(s) de pico. Daí é imperativo identificar esses horários.
Para isto, deve ser feita uma coleta do consumo do processador ao longo de 1 ano, 24 horas, por dia. A ideia é identificar:
- Mês mais crítico
- Semana mais crítica
- Dia da semana mais crítico
- Período do dia mais crítico
-
Definir
T₀ = 365 dias x 24 horas Tₛ = 3 segundos -
Definir períodos do dia
Exemplo:
P₁ 08:00 - 10:00 P₂ 10:01 - 12:00 P₃ 12:10 - 18:00 P₄ 18:01 - 07:59

