Ziyu Zhu, Zhuofan Zhang, Xiaojian Ma, Xuesong Niu, Yixin Chen, Baoxiong Jia, Zhidong Deng📧, Siyuan Huang📧, Qing Li📧
This repository is the official implementation of the ECCV 2024 paper "Unifying 3D Vision-Language Understanding via Promptable Queries".
Paper | arXiv | Project | HuggingFace Demo | Checkpoints
- [ 2024.07 ] Our huggingface DEMO is here DEMO, welcome to try our model!
- [ 2024.07 ] Release codes of model! TODO: Clean up training and evaluation
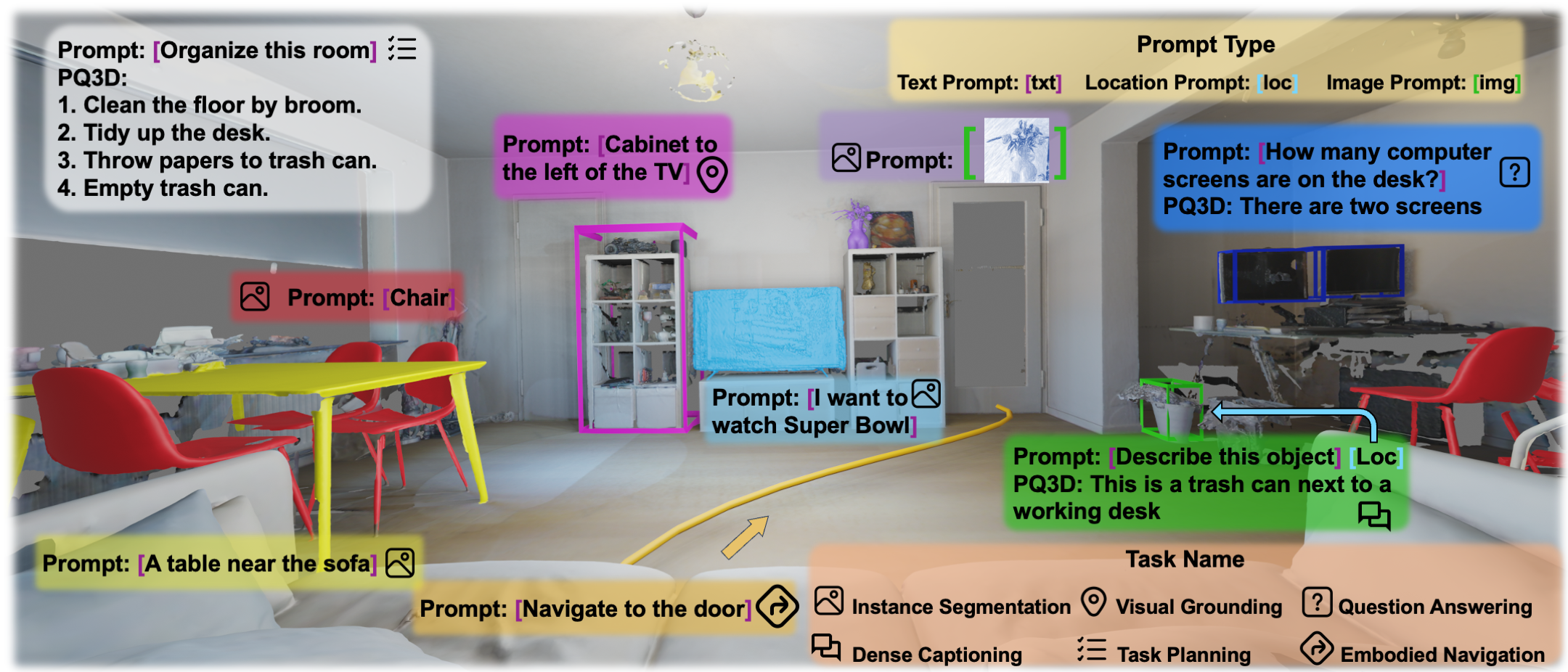
A unified model for 3D vision-language (3D-VL) understanding is expected to take various scene representations and perform a wide range of tasks in a 3D scene. However, a considerable gap exists between existing methods and such a unified model, due to the independent application of representation and insufficient exploration of 3D multi-task training. In this paper, we introduce PQ3D, a unified model capable of using Promptable Queries to tackle a wide range of 3D-VL tasks, from low-level instance segmentation to high-level reasoning and planning.Tested across ten diverse 3D-VL datasets, This is achieved through three key innovations: (1) unifying various 3D scene representations (i.e., voxels, point clouds, multi-view im- ages) into a shared 3D coordinate space by segment-level grouping, (2) an attention-based query decoder for task-specific information retrieval guided by prompts, and (3) universal output heads for different tasks to support multi-task training. PQ3D demonstrates impressive performance on these tasks, setting new records on most benchmarks. Particularly, PQ3D improves the state- of-the-art on ScanNet200 by 4.9% (AP25), ScanRefer by 5.4% (acc@0.5), Multi3DRefer by 11.7% (F1@0.5), and Scan2Cap by 13.4% (CIDEr@0.5).Moreover, PQ3D supports flexible inference with individual or combined forms of available 3D representations, e.g., solely voxel input
- Install conda package
conda env create --name envname
pip3 install torch==2.0.0
pip3 install torchvision==0.15.1
pip3 install -r requirements.txt
- install pointnet2
cd modules/third_party
# PointNet2
cd pointnet2
python setup.py install
cd ..
- Install Minkowski Engine
git clone https://github.com/NVIDIA/MinkowskiEngine.git
conda install openblas-devel -c anaconda
cd MinkowskiEngine
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
TODO
download all checkpoint and use pretrain_ckpt_path={checkpoint_path} to ;pad checkpoint
python3 run.py --config-path configs --config-name config-name.yaml
for multi-gpu training use
python launch.py --mode ${launch_mode} \
--qos=${qos} --partition=${partition} --gpu_per_node=4 --port=29512 --mem_per_gpu=80 \
--config {config} \
We would like to thank the authors of Vil3dref, Mask3d, Openscene, Xdecoder, and 3D-VisTA for their open-source release.
@article{zhu2024unifying,
title={Unifying 3D Vision-Language Understanding via Promptable Queries},
author={Zhu, Ziyu and Zhang, Zhuofan and Ma, Xiaojian and Niu, Xuesong and Chen, Yixin and Jia, Baoxiong and Deng, Zhidong and Huang, Siyuan and Li, Qing},
journal={arXiv preprint arXiv:2405.11442},
year={2024}
}