Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering
For the purpose of this project I focused on the overall solution design and implementation. I have used a very common architecture in the question answering task, using a pretrained transformer encode, i.e. distilbert-base-uncased, and adding a classification head to predict the start and end indices of the answer. The model is trained/fine-tuned using my own Trainer module.
I have chosen the value of the max length to be 385 because ~99% of the data points have less than 384 tokens. The loss function is the cross entropy, and the optimizer is the AdamW with the most common hyperparameters fot this task. The model is trained for 5 epochs and the batch size is 32.
The model training was executed on an AWS EC2 virtual machine, specifically a g4dn.2xlarge instance type equipped with a T4 Nvidia GPU. To improve the training speed, it was conducted using fp16 (half-precision floating-point) precision.
The configuration is:
train:
seed: 42
epochs: 5
batch_size: 32
num_workers: 8
log_every_n_steps: 100
precision: 'fp16'
model:
embedding_mode: 'distilbert-base-uncased'
hidden_size: 768
hidden_dropout_prob: 0.1
max_length: 385
loss:
criterion: 'CrossEntropyLoss'
reduction: mean
optimizer:
optim: adam
beta1: 0.9
beta2: 0.999
epsilon: 1e-8
learning_rate: 3e-5
wandb:
wandb_project: question_answering_system
wandb_run: 'train'Using the official eval scrip on the dev dataset is:
{
"exact": 35.32384401583425,
"f1": 40.65245381115769,
"total": 11873,
"HasAns_exact": 66.07624831309042,
"HasAns_f1": 76.74874900470228,
"HasAns_total": 5928,
"NoAns_exact": 4.659377628259041,
"NoAns_f1": 4.659377628259041,
"NoAns_total": 5945
}In order to install the dependencies
poetry env use 3.11
poetry install
To download the necessary datasets:
wget -nc https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json
wget -nc https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json
To train the model, you first need to configure it using the config file located in the config folder. If you want to log the metrics at wandb, run wandb init first.
So the train command is:
poetry run python3 qa_system/qa_ml_model train --config_path config/config.yml --train_dataset_path train-v2.0.json --dev_dataset_path dev-v2.0.json --embedding_mode "distilbert-base-uncased" --checkpoints_path models/
When the training is finished you can run the predictions as follows:
poetry run python3 qa_system/qa_ml_model/__main__.py predict --checkpoint_file models/model.bin --metadata_file models/metadata.json --dataset_path data/squad_v2/raw/dev-v2.0.json --results_file results.json
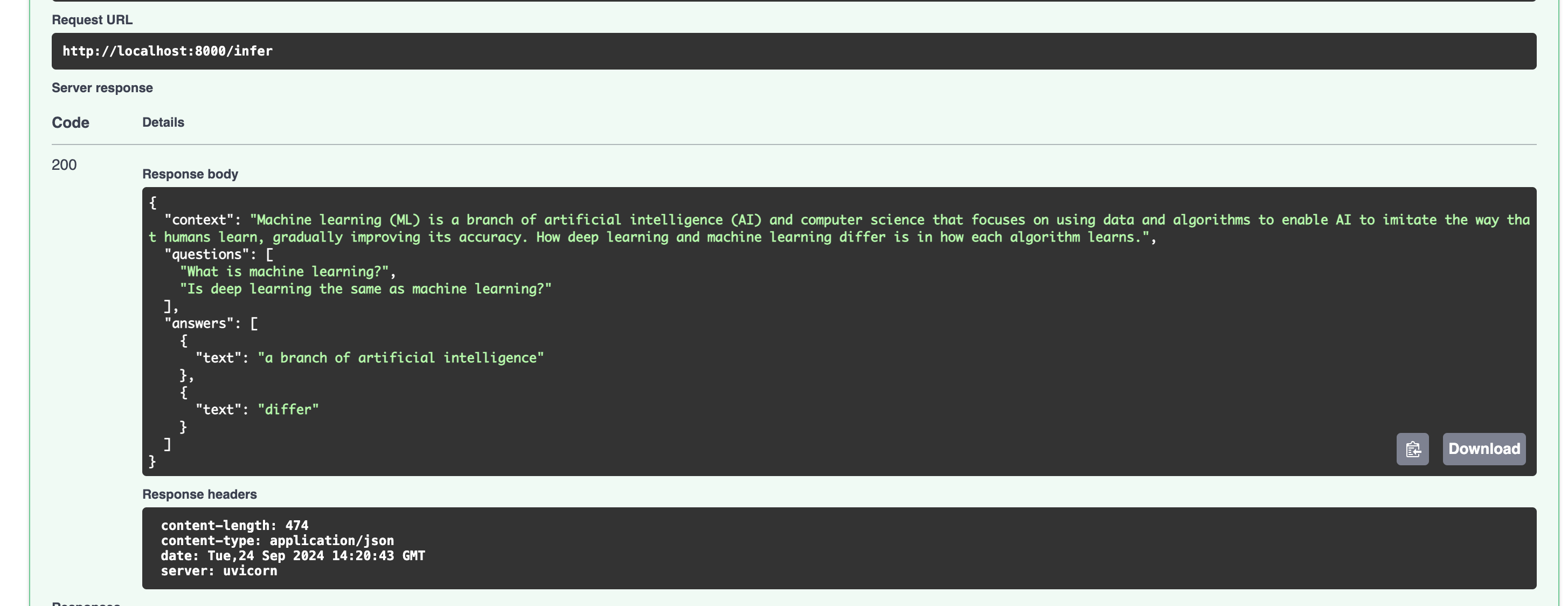
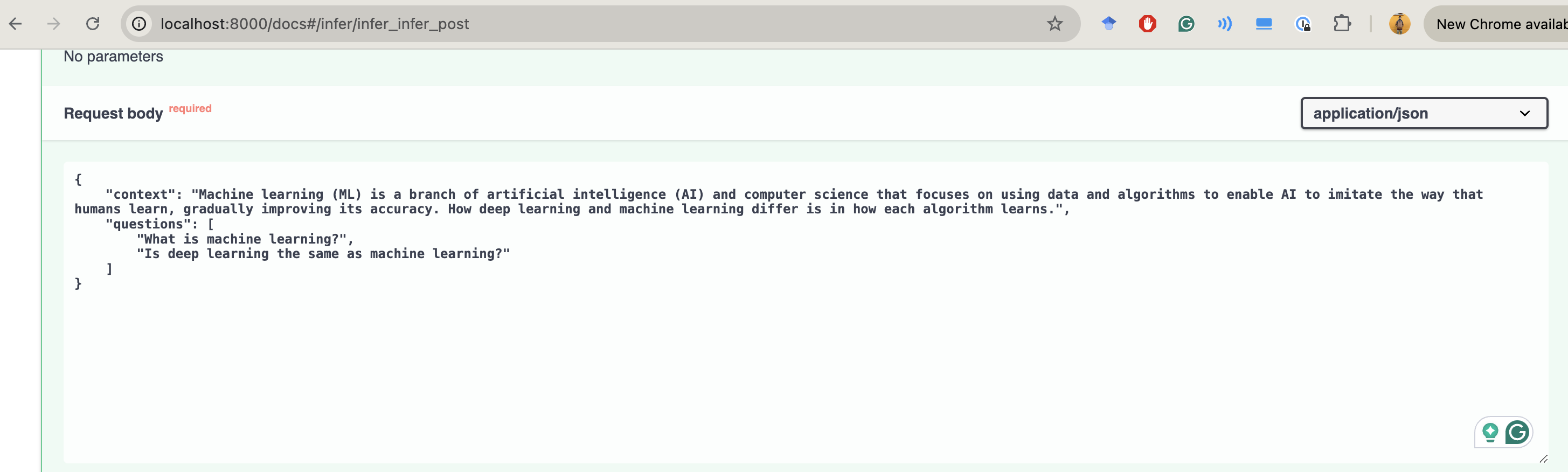
To perform inference, I've developed an API featuring a straightforward authentication mechanism, equipped with both health check and inference endpoints. The API receives the context and a list of questions. The response is a list of their corresponding answers.
Example request:
{
"context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ('Norman' comes from 'Norseman') raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
"questions": [
"In what country is Normandy located?",
"When were the Normans in Normandy?",
]
}Example response
{
"context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ('Norman' comes from 'Norseman') raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
"questions": [
"In what country is Normandy located?",
"When were the Normans in Normandy?",
],
"answers": [
{
"text": "France",
},
{
"text": "in the 10th and 11th centuries",
}
]
}Before you create the application you need the .env file with:
API_KEY=...
To build the application you must run:
docker build --no-cache -t qna_system:latest .
docker-compose up -d
Then send requests in localhost at port 8000.
Below are some snapshots of the API:
-
Request
-
Response