参考某熊的技术之路指北 ☯,深入浅出分布式基础架构是笔者归档自己,在学习与实践软件分布式架构过程中的,笔记与代码的仓库;主要包含分布式计算、分布式系统、数据存储、虚拟化、网络、操作系统等几个部分。
所谓的分布式系统,其主要由网络、分布式存储与分布式计算等部分构成,分布式存储侧重于数据的读写存取及一致性等方面,而分布式计算则侧重于资源、任务的编排调度。
过去数十年间,信息技术的浪潮深刻地改变了这个社会的通信、交流与协作模式,我们熟知的互联网也经历了基于流量点击赢利的单方面信息发布的 Web 1.0 业务模式,转变为由用户主导而生成内容的 Web 2.0 业务模式;在可见的将来随着 3D 相关技术的落地,互联网应用系统所需处理的访问量和数据量必然会再次爆发性增长。
从**演进看,凯文.凯利 2016 年在《失控》一书中指出,分布式系统具有四个突出特点,即没有强制性的中心控制、次级单位具有自治的特质、次级单位之间彼此高度链接、点对点之间的影响通过网络形成了非线性因果关系。凯文.凯利进一步指出,与其说一个分布式、去中心化的网络是一个物体,还不如说它是一个过程。
并发的增加对我们的后端架构提出了巨大的挑战,要求我们的系统弹性可扩展。

上图从三个维度概括了一个系统的扩展过程:
- X 轴即水平复制,即在负载均衡服务器后增加多个 Web 服务器。
- Z 轴是对数据库的扩展,即分库分表,分库是将关系紧密的表放在一台数据库服务器上,分表是因为一张表的数据太多,需要将一张表的数据通过 hash 放在不同的数据库服务器上。
- Y 轴是业务方向的扩展,才能将巨型应用分解为一组不同的服务,将应用进一步分解为微服务(分库),例如订单管理中心、客户信息管理中心、商品管理中心等等。
总结而言,垂直伸缩只能通过增加服务器的配置有限度地提升系统的处理能力,而水平伸缩能够仅通过增减服务器数量相应地提升和降低系统的吞吐量;这种分布式系统架构,在理论上为吞吐量的提升提供了无限的可能。因此,用于搭建互联网应用的服务器也渐渐放弃了昂贵的小型机,转而采用大量的廉价 PC 服务器。
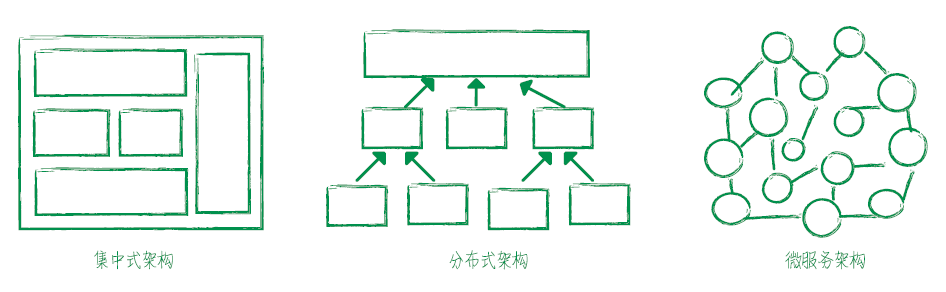
在分布式系统的背景下,企业架构也由早期的单体式应用架构渐渐转为更加灵活的分布式应用架构,经历了单体分层架构、SOA 服务化架构、微服务架构、云原生架构等不同架构模式的变迁。后端开发不再局限于单一技术栈,并且为了应对更加庞大的集群规模,单纯的分布式系统已经难于驾驭,因此技术圈开启了一个概念爆发的时代:SOA、DevOps、容器、CI/CD、微服务、Service Mesh 等概念层出不穷,而 Docker、Kubernetes、Mesos、Spring Cloud、gRPC、Istio 等一系列产品的出现,标志着云时代已真正到来。

分布式场景下比较著名的难题就是 CAP 定理。CAP 定理认为,在分布式系统中,系统的一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance),三者不可能同时兼顾。在分布式系统中,由于网络通信的不稳定性,分区容忍性是必须要保证的,因此在设计应用的时候就需要在一致性和可用性之间权衡选择。互联网应用比企业级应用更加偏向保持可用性,因此通常用最终一致性代替传统事务的 ACID 强一致性。
-
如果你想了解数据库相关,可以参阅 Database-Series。
-
如果你想了解虚拟化与云计算相关,可以参阅 Cloud-Series。
-
如果你想了解 Linux 与操作系统相关,可以参阅 Linux-Series。
笔者所有文章遵循 知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议,欢迎转载,尊重版权。如果觉得本系列对你有所帮助,欢迎给我家布丁买点狗粮(支付宝扫码)~

您还可以前往 NGTE Books 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:
