This is a short tutorial on using Deep contextualized word representations (ELMo) which is discussed in the paper https://arxiv.org/abs/1802.05365. This tutorial can help in using:
- Pre Trained Elmo Model - refer Elmo_tutorial.ipynb
- Training an Elmo Model on your new data from scratch
To train and evaluate a biLM, you need to provide:
- a vocabulary file
- a set of training files
- a set of heldout files
The vocabulary file is a text file with one token per line. It must also include the special tokens , and
The vocabulary file should be sorted in descending order by token count in your training data. The first three entries/lines should be the special tokens :
<S> ,
</S> and
<UNK>.
The training data should be randomly split into many training files, each containing one slice of the data. Each file contains pre-tokenized and white space separated text, one sentence per line.
Don't include the <S> or </S> tokens in your training data.
Once done, git clone https://github.com/allenai/bilm-tf.git and run:
python bin/train_elmo.py --train_prefix= <path to training folder> --vocab_file <path to vocab file> --save_dir <path where models will be checkpointed>
To get the weights file, run:
python bin/dump_weights.py --save_dir /output_path/to/checkpoint --outfile/output_path/to/weights.hdf5
In the save dir, one options.json will be dumped and above command will give you a weights file required to create an Elmo model (options file and the weights file)
For more information refer Elmo_tutorial.ipynb
To incrementally train an existing model with new data
While doing Incremental training : git clone https://github.com/allenai/bilm-tf.git
Once done, replace train_elmo within allenai/bilm-tf/bin/ with train_elmo_updated.py provided at home.
Updated changes :
train_elmo_updated.py
tf_save_dir = args.save_dir
tf_log_dir = args.save_dir
train(options, data, n_gpus, tf_save_dir, tf_log_dir,restart_ckpt_file)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--save_dir', help='Location of checkpoint files')
parser.add_argument('--vocab_file', help='Vocabulary file')
parser.add_argument('--train_prefix', help='Prefix for train files')
parser.add_argument('--restart_ckpt_file', help='latest checkpoint file to start with')
This takes an argument (--restart_ckpt_file) to accept the path of the checkpointed file.
replace training.py within allenai/bilm-tf/bilm/ with training_updated.py provided at home. Also, make sure to put your embedding layer name in line 758 in training_updated.py :
exclude = ['the embedding layer name you want to remove']
Updated changes :
training_updated.py
# load the checkpoint data if needed
if restart_ckpt_file is not None:
reader = tf.train.NewCheckpointReader(your_checkpoint_file)
cur_vars = reader.get_variable_to_shape_map()
exclude = ['the embedding layer name you want to remove']
variables_to_restore = tf.contrib.slim.get_variables_to_restore(exclude=exclude)
loader = tf.train.Saver(variables_to_restore)
#loader = tf.train.Saver()
loader.save(sess,'/tmp')
loader.restore(sess, '/tmp')
with open(os.path.join(tf_save_dir, 'options.json'), 'w') as fout:
fout.write(json.dumps(options))
summary_writer = tf.summary.FileWriter(tf_log_dir, sess.graph)
The code reads the checkpointed file and reads all the current variables in the graph and excludes the layers mentioned in the exclude variable, restores rest of the variables along with the associated weights.
For training run:
python bin/train_elmo_updated.py --train_prefix= <path to training folder> --vocab_file <path to vocab file> --save_dir <path where models will be checkpointed> --restart_ckpt_file <path to checkpointed model>
In the train_elmo_updated.py within bin, set these options based on your data:
batch_size = 128 # batch size for each GPU
n_gpus = 3
# number of tokens in training data
n_train_tokens =
options = {
'bidirectional': True,
'dropout': 0.1,
'all_clip_norm_val': 10.0,
'n_epochs': 10,
'n_train_tokens': n_train_tokens,
'batch_size': batch_size,
'n_tokens_vocab': vocab.size,
'unroll_steps': 20,
'n_negative_samples_batch': 8192,
Visualisation
Visualization of the word vectors using Elmo:
-
Tsne
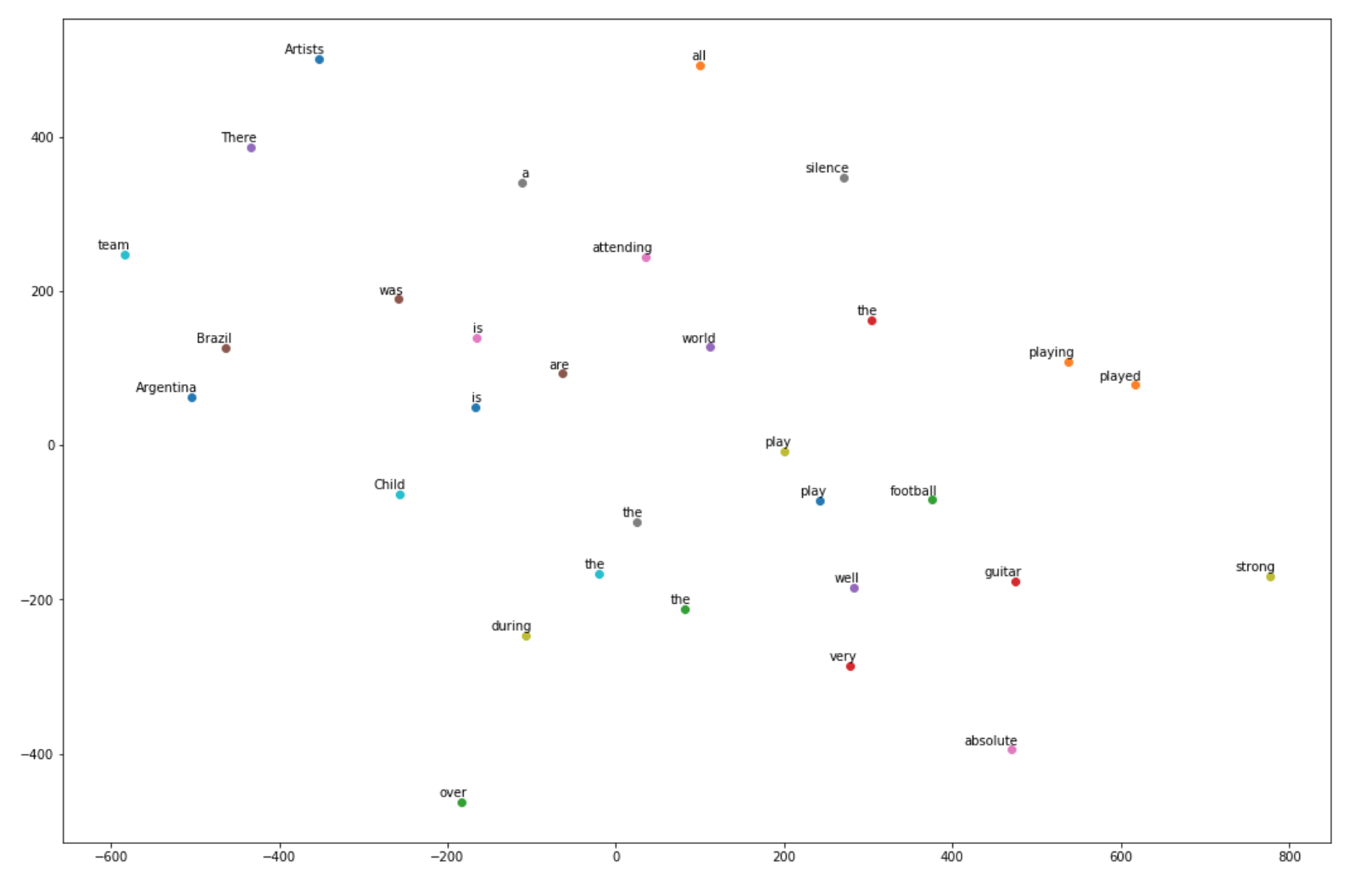
-
Tensorboard


if you want to use Elmo Embedding layer in consequent model build refer : https://github.com/PrashantRanjan09/WordEmbeddings-Elmo-Fasttext-Word2Vec