注:第一次运行程序耗费时间会很大!
本项目实现了一个基于特定语料库的搜索引擎,其支持的功能有:
- 布尔查询
- 通配查询
- 拼写校正
- 短语查询
- 同义词扩展
- 建立倒排索引和向量空间模型
- 索引压缩
- 词典索引
- TopK排序
- 在浏览器中显式地反馈搜索结构
-
运行环境
操作系统 Windows10
MacOSpython python3 使用工具 pip -
安装库
项目使用了WordNet开源库,首先需要安装WordNet才能开始运行程序。
首先安装nltk库:
pip install nltk
进入python命令行中,输入下列命令:
import nltk import ssl try: _create_unverified_https_context = ssl._create_unverified_context except AttributeError: pass else: ssl._create_default_https_context = _create_unverified_https_context nltk.download('wordnet') nltk.download('omw-1.4')
-
运行时若发生以下错误:


- 进入到项目文件夹下
$ cd WebSearch - 终端输入
启动服务器
$ python -m http.server
- 新建终端,输入
此时开始运行搜索引擎程序并进行搜索引擎初始化
$ python main.py
- 搜索引擎初始化完成后共有四种选项:
- 输入
1,进行普通查询 - 输入
2,使用topK查询 - 输入
3,开/关向量排序 - 输入
4,退出程序
- 输入
查询模式选择1
education
查询语句如下所示:
将按照education的倒排索引表顺序返回结果(包含了同义词扩展的结果)
查询结果如下图所示:

因为我们·计算向量时采用了高IDF策略,所以忽略了高频词education,因此我们以低频词input为例。
首先选择 3 打开向量排序功能
然后选择1 进行查询
查询模式选择 3
查询模式选择 1
input
此时返回的便是向量相似度排序的结果:
为了之后的测试速度,我们选择选择3关闭排序进行之后的计算
查询模式选择1
AND: government AND policy
OR: billion OR million
NOT: NOT fall AND rise
查询语句如下所示:

查询结果如下图所示:

查询模式选择1
*put
technol*
*formatia*
查询语句如下所示:

查询结果如下所示:

查询模式选择1
information technology
查询语句如下所示:

查询结果如下所示:

查询模式选择1
kindom
查询语句如下所示:
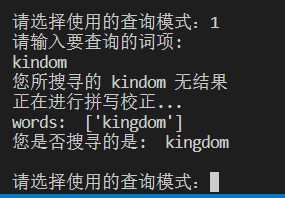
查询结果如下所示:

查询模式选择1
education
查询语句如下所示:

查询结果如下所示:
| 成员 | 分工 |
|---|---|
| 王越嵩 | 布尔查询 通配查询 拼写校正 |
| 邓承克 | 倒排索引 向量空间模型 短语查询 同义词扩展 |
| 李炯 | TopK查询 索引压缩 词典索引 |