Here you can find several projects dedicated to the Deep Reinforcement Learning methods.
The projects are deployed in the matrix form: [env x model], where env is the environment
to be solved, and model is the model/algorithm which solves this environment. In some cases,
the same environment is resolved by several algorithms. All projects are presented as
a jupyter notebook containing training log.
The following environments are supported:
AntBulletEnv, Bipedalwalker, CarRacing, CartPole, Crawler, HalfCheetahBulletEnv,
HopperBulletEnv, LunarLander, LunarLanderContinuous, Markov Decision 6x6, Minitaur,
Minitaur with Duck, Pong, Navigation, Reacher, Snake, Tennis, Waker2DBulletEnv.

Four environments (Navigation, Crawler, Reacher, Tennis) are solved in the framework of the
Udacity Deep Reinforcement Learning Nanodegree Program.
- Monte-Carlo Methods
In Monte Carlo (MC), we play episodes of the game until we reach the end, we grab the rewards
collected on the way and move backward to the start of the episode. We repeat this method
a sufficient number of times and we average the value of each state. - Temporal Difference Methods and Q-learning
- Reinforcement Learning in Continuous Space (Deep Q-Network)
- Function Approximation and Neural Network
The Universal Approximation Theorem (UAT) states that feed-forward neural networks containing a
single hidden layer with a finite number of nodes can be used to approximate any continuous function
provided rather mild assumptions about the form of the activation function are satisfied. - Policy-Based Methods, Hill-Climbing, Simulating Annealing
Random-restart hill-climbing is a surprisingly effective algorithm in many cases. Simulated annealing is a good
probabilistic technique because it does not accidentally think a local extrema is a global extrema. - Policy-Gradient Methods, REINFORCE, PPO
Define a performance measure J(\theta) to maximaze. Learn policy paramter \theta throgh approximate gradient ascent.
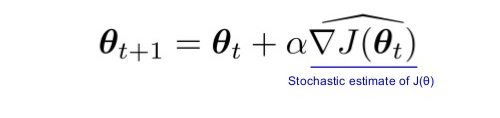
- Actor-Critic Methods, A3C, A2C, DDPG, TD3, SAC
The key difference from A2C is the Asynchronous part. A3C consists of multiple independent agents(networks) with
their own weights, who interact with a different copy of the environment in parallel. Thus, they can explore
a bigger part of the state-action space in much less time.

AntBulletEnv, Soft Actor-Critic (SAC)
BipedalWalker, Twin Delayed DDPG (TD3)
BipedalWalker, PPO, Vectorized Environment
BipedalWalker, Soft Actor-Critic (SAC)
BipedalWalker, A2C, Vectorized Environment
CarRacing with PPO, Learning from Raw Pixels
CartPole, Policy Based Methods, Hill Climbing
CartPole, Policy Gradient Methods, REINFORCE
HalfCheetahBulletEnv, Twin Delayed DDPG (TD3)
HopperBulletEnv, Twin Delayed DDPG (TD3)
HopperBulletEnv, Soft Actor-Critic (SAC)
LunarLanderContinuous-v2, DDPG
Markov Decision Process, Monte-Carlo, Gridworld 6x6
MinitaurBulletEnv, Soft Actor-Critic (SAC)
MinitaurBulletDuckEnv, Soft Actor-Critic (SAC)
Pong, Policy Gradient Methods, PPO
Pong, Policy Gradient Methods, REINFORCE
Udacity Project 1: Navigation, DQN, ReplayBuffer
Udacity Project 2: Continuous Control-Reacher, DDPG, environment Reacher (Double-Jointed-Arm)
Udacity Project 2: Continuous Control-Crawler, PPO, environment Crawler
Udacity Project 3: Collaboration_Competition-Tennis, Multi-agent DDPG, environment Tennis
Walker2DBulletEnv, Twin Delayed DDPG (TD3)
Walker2DBulletEnv, Soft Actor-Critic (SAC)
- Pong, 8 parallel agents
- CarRacing, Single agent, Learning from pixels
- C r a w l e r , 12 parallel agents
- BipedalWalker, 16 parallel agents
- AntBulletEnv
- BipedalWalker
- HopperBulletEnv
- MinitaurBulletEnv
- MinitaurBulletDuckEnv
- Walker2dBulletEnv
- BipedalWalker, Twin Delayed DDPG (TD3)
- BipedalWalker, PPO, Vectorized Environment
- BipedalWalker, Soft-Actor-Critic (SAC)
- BipedalWalker, A2C, Vectorized Environment
- CartPole, Policy Based Methods, Hill Climbing
- CartPole, Policy Gradient Methods, REINFORCE
- Cartpole with Deep Q-Learning
- Cartpole with Doouble Deep Q-Learning
- on Policy-Gradient Methods, see 1, 2, 3.
- on REINFORCE, see 1, 2, 3.
- on PPO, see 1, 2, 3, 4, 5.
- on DDPG, see 1, 2.
- on Actor-Critic Methods, and A3C, see 1, 2, 3, 4.
- on TD3, see 1, 2, 3
- on SAC, see 1, 2, 3, 4, 5
- on A2C, see 1, 2, 3, 4, 5
How does the Bellman equation work in Deep Reinforcement Learning?
A pair of interrelated neural networks in Deep Q-Network
Three aspects of Deep Reinforcement Learning: noise, overestimation and exploration